**Question/Issue:I am encountering an issue related to the number of features when using the Edge Impulse Linux SDK for inference. My model was trained to detect 50 features, but I would like to perform inference with fewer than 50 features.
When I attempt this, the system returns the following error message:
“Exception: Invalid number of features in ‘classify’, expected 50 but got 10(lower than 50)”
I understand that this error occurs because the model expects 50 features as input. However, in my application, the number of features may be less than this. Is there a way to have the model accept fewer than 50 features for classification without retraining the model? Alternatively, do you have any suggestions on how to address this issue?**
Build Environment Details: [e.g., Arduino IDE 1.8.19 ESP32 Core for Arduino 2.0.4]
OS Version: [e.g., Ubuntu 20.04, Windows 10]
Edge Impulse Version (Firmware):v1.27.1 [e.g., 1.2.3]
To find out Edge Impulse Version:
if you have pre-compiled firmware: run edge-impulse-run-impulse --raw and type AT+INFO. Look for Edge Impulse version in the output.
if you have a library deployment: inside the unarchived deployment, open model-parameters/model_metadata.h and look for EI_STUDIO_VERSION_MAJOR, EI_STUDIO_VERSION_MINOR, EI_STUDIO_VERSION_PATCH
Edge Impulse CLI Version: [e.g., 1.5.0]
Project Version: [e.g., 1.0.0]
Custom Blocks / Impulse Configuration: [Describe custom blocks used or impulse configuration] Logs/Attachments:
[Include any logs or screenshots that may help in diagnosing the issue]
The features are the output of the digital signal processing part of the impulse which helps reduce the raw data down to key features, the type of which depends on if your project uses imagery, audio, or time-series data like accelerometer etc.
If you want to run the model with fewer features that typically means the impulse will need to be re-tailored to accommodate this and that means changing the input size or DSP block.
Do you have access to the project which created the impulse or only the deployed binary or library?
Since you mentioned 50 features I’m going to assume you are dealing with time-series data.
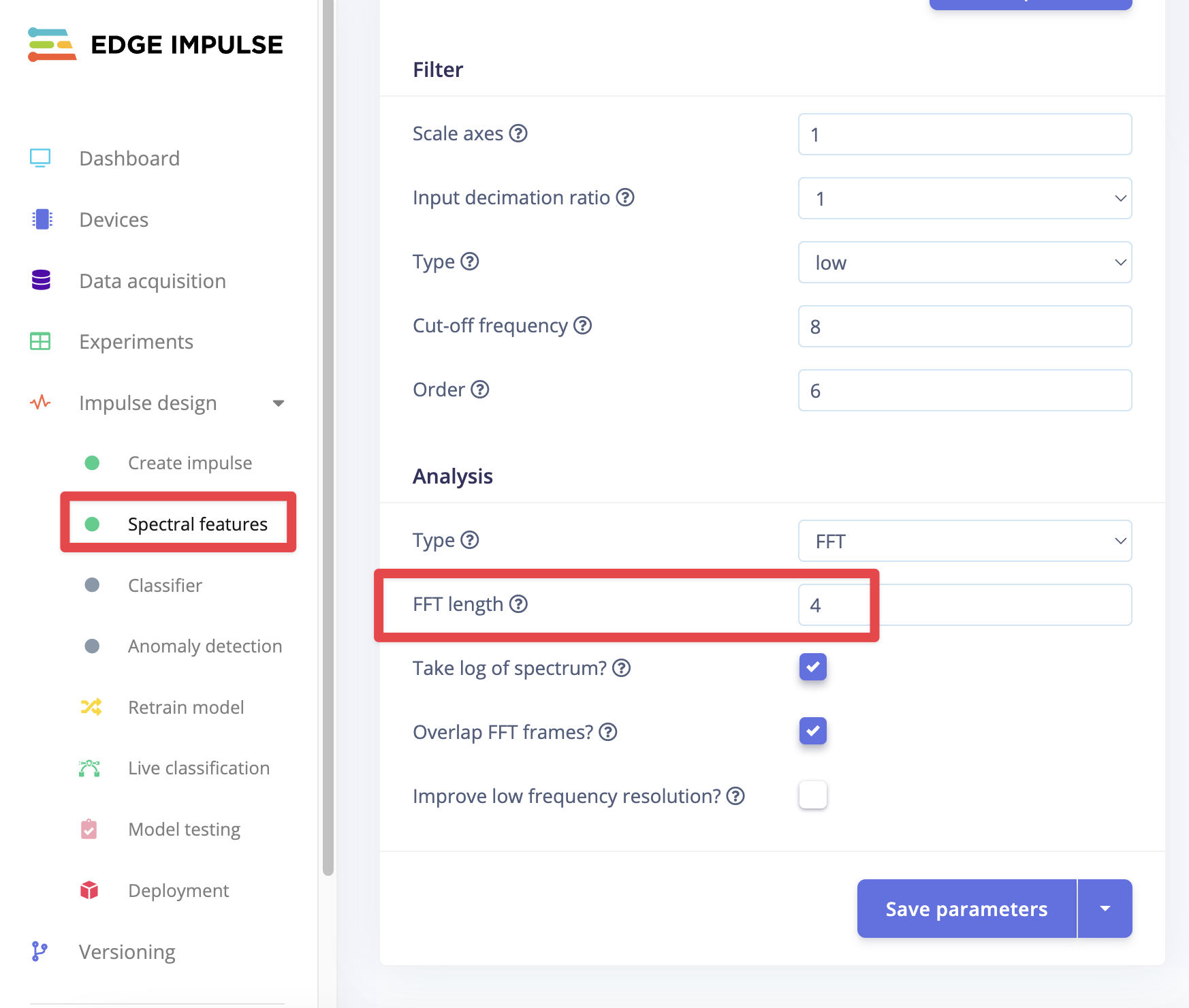
You might be using the spectral features block. In this case reducing the FFT size will also lead to a smaller feature size. It of course will reduce overall accuracy as that’s the tradeoff but it depends on your model and application what you should choose. It just has to be a power of 2.
Since I’m running the model on an RPi4, I want to modify the classify.py file on GitHub so that it can dynamically adjust the amount of data read using a sliding window approach during execution. I also tried retraining the model after changing the FFT length, but I still encounter an error.
Here’s the error I receive when running it on the RPi4:
iot409490454@raspberrypi:~/linux-sdk-python/examples/custom $ python3 classifydiff.py modelfile.eim test.txt
MODEL: /home/iot409490454/linux-sdk-python/examples/custom/modelfile.eim
Loaded runner for "Iot025454 / test"
Traceback (most recent call last):
File "/home/iot409490454/linux-sdk-python/examples/custom/classifydiff.py", line 70, in <module>
main(sys.argv[1:])
File "/home/iot409490454/linux-sdk-python/examples/custom/classifydiff.py", line 59, in main
res = runner.classify(features)
File "/home/iot409490454/.local/lib/python3.9/site-packages/edge_impulse_linux/runner.py", line 60, in classify
return self.send_msg(msg)
File "/home/iot409490454/.local/lib/python3.9/site-packages/edge_impulse_linux/runner.py", line 109, in send_msg
raise Exception(resp["error"])
Exception: Invalid number of features in 'classify', expected 50 but got 1248
Could you please advise on how I can achieve this dynamic adjustment of the number of features when running the model on the RPi4?
Can I ask why are you doing this instead of retraining your project with the correct features? (That is the easiest way, and we recommend doing this for beginners)
Otherwise you will need to modify the provided classify.py that we’ve designed to demonstrate how to run inference on a single set of features. This is done to make it easy to get started with the Edge Impulse Linux SDK. By giving it a feature file as input, the script processes the data, performs classification, and outputs the result. Be careful on the available resource restrictions.
Could you please advise on how I can achieve this dynamic adjustment of the number of features when running the model on the RPi4?
Pick the relevant example here to base your project around:
You can modify the script to segment the data into fixed-size windows that match the model’s expected input size (e.g., 50 features) and classify each window individually. (Chose your own method here with what you are comfortable with)
You can also extend the script to continuously read and classify data, instead of just processing a single input file. This would involve setting up a loop that regularly collects data, preprocesses it, and runs the classification. (Chose your own method here with what you are comfortable with)
You can refer to the examples here for an idea on the approach to take but it will require some custom code as outlined above:
Thank you for your previous guidance. I followed your advice and tried to implement a sliding window approach in my Python script to dynamically adjust the number of features used during classification on the RPi4.
Here is a brief overview of what I’ve done:
I modified the classify.py script to use a sliding window to dynamically select a subset of the features from the input data file.
The window size can be adjusted via a GUI slider, and the selected features are then passed to the classify method.
However, I am still encountering an issue when trying to classify the features. Specifically, I get the following error:
Exception: Invalid number of features in 'classify', expected 50 but got 1248
I understand that the model expects exactly 50 features, but I’m wondering if there is any way to dynamically adjust the number of features or handle this scenario where the feature count might exceed the expected number. Any insights or suggestions on how to resolve this issue would be greatly appreciated.
Additionally, I tried modifying the classify.py file, but it seems I still can’t resolve the error message.