I’m currently working on an object detection project using Edge Impulse. I have collected data for two unique objects, with 160 photos in total (60 for object A and 100 for object B). I trained the model and achieved 86% performance with a validation set, and the confusion matrix looks good in all parameters.
However, when I tested the model with a test dataset, I noticed that most of the images had an F1 score of 0%, and even the images that had a 100% score only showed a small piece of the object. I checked the camera and the lighting, and they seem to be okay.
To improve the model’s performance, I have tried the following steps:
I collected more data for both objects to improve the model’s generalization ability.
I augmented the data by rotating, flipping, and cropping the images to create new variations.
I experimented with different models to see which one performs the best on my data.
I fine-tuned the model by adjusting the hyperparameters such as the learning rate and batch size.
I checked the quality of the test images to ensure they were representative of the data the model was trained on.
I also checked the model’s output to see what it was detecting and where it was detecting it.
Despite trying these steps, I’m still having trouble getting good results from the test dataset.
I plan to run this project on mobile phones, and I’m hoping to get some suggestions or ideas on how I can improve the model’s performance, specifically for mobile devices.
If anyone has any tips or advice on how I can optimize the model for mobile phones or suggestions on what I can do to improve the model’s performance, I would be grateful.
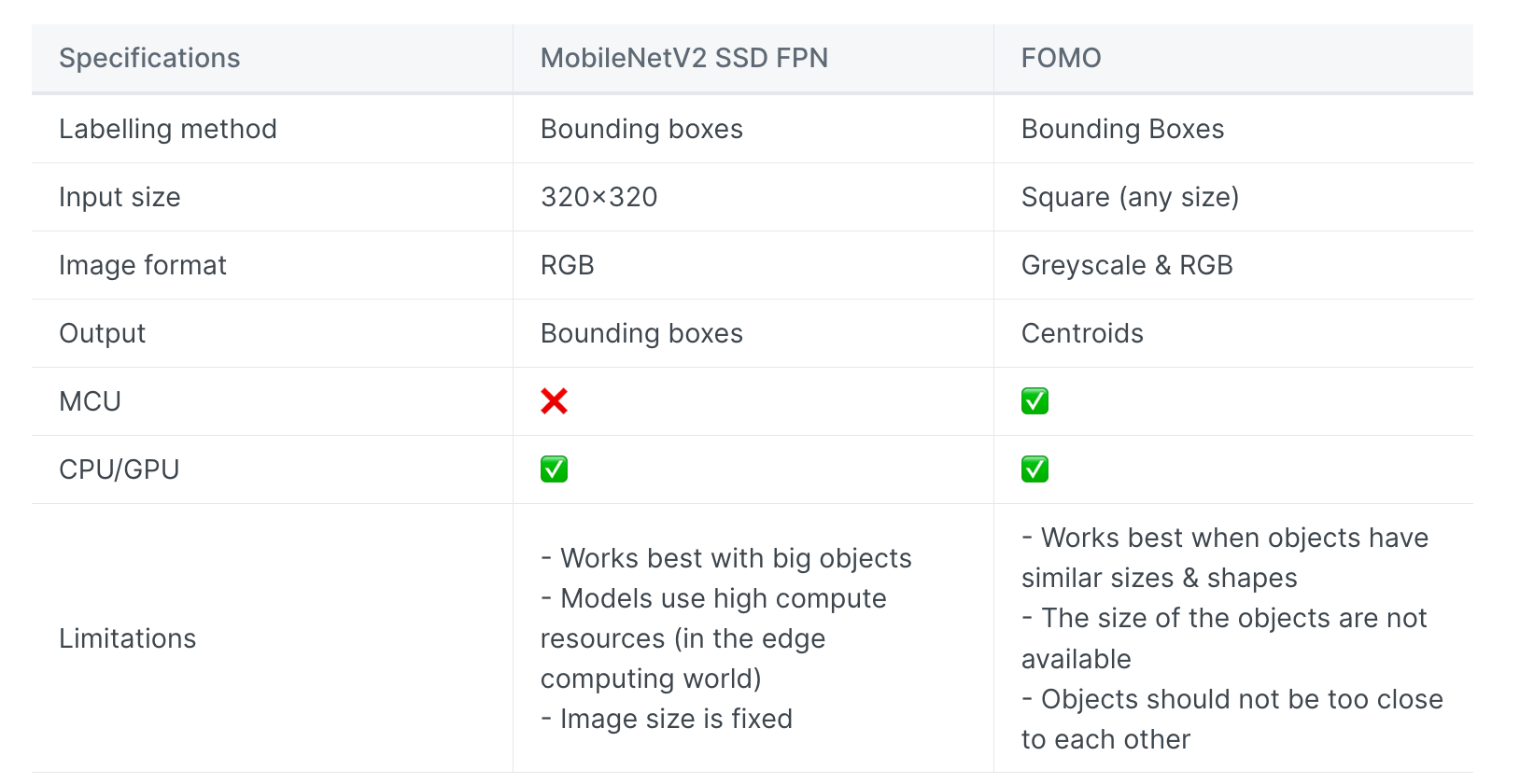
With FOMO, the image is divided into a grid and classify each box, so we can create an F1 score to represent the proportion of correct and incorrect grid boxes.See this. The default grid is 1/8th of the input image, however, this can be changed in Expert mode by editing the Keras code.
Which Object Detection model are you using?
Can you share a couple of images as an example so I can guide you about the best object detection model to choose?
Thank you MMarcia for your response . I appreciate the information you provided about being able to adjust the Keras.
Thanks, Louis I am working with on a project to detect two unique objects and run the model on mobile phone that are unlikely to be in any dataset, and I need the model to detect them as complete piece rather than just parts of them. Would FOMO be suitable for this task, or do you have any other recommendations for a model that could be more effective?
Worth noting that I some of the photos I processed them before uploading them and removed their background if that might be effect.
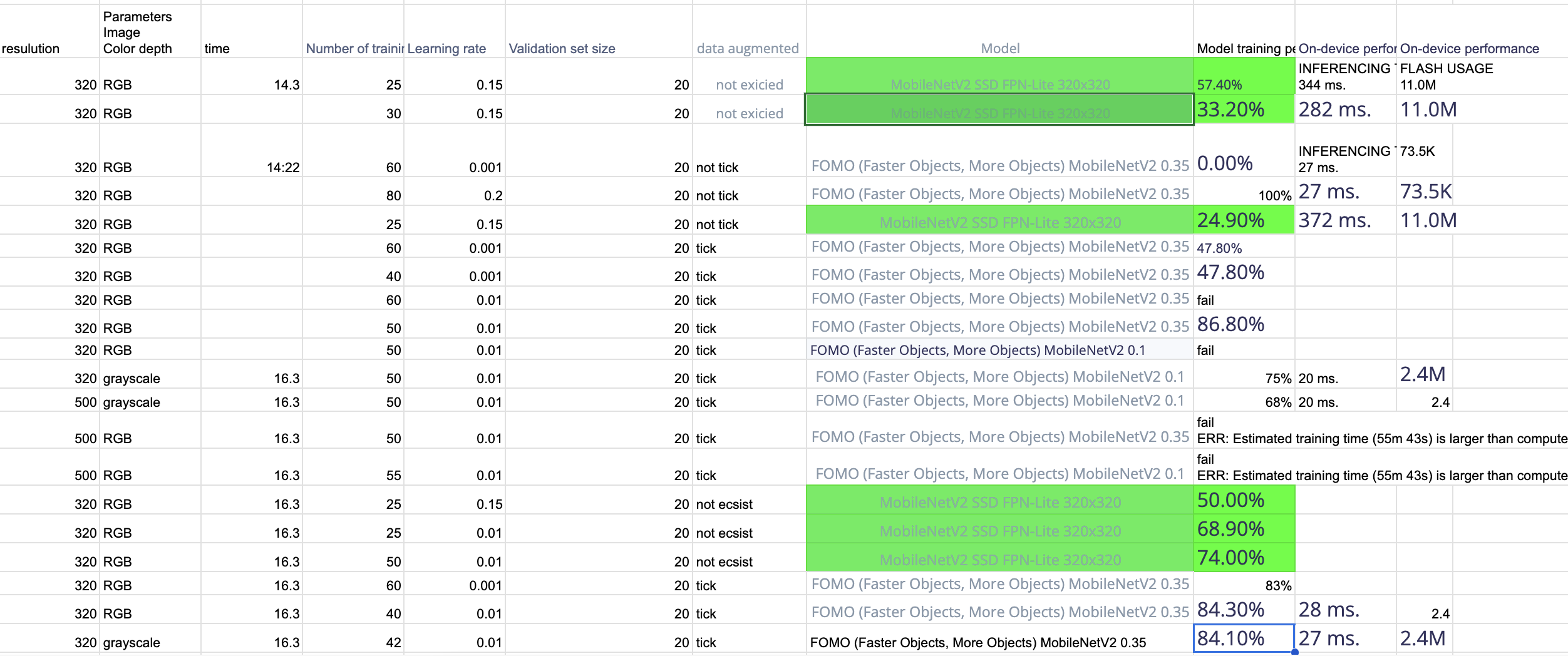
Thank you for your response and recommendation regarding my object detection project. I appreciate your advice, and I will definitely do more testing with the MobileNetv2 SSD model as you suggested.
I wanted to share with you some of the tests I conducted using the MobileNetV2 SSD FPN-Lite 320x320 model. Unfortunately, the results were unsatisfactory, and I included a screenshot of the results in my documentation. I would appreciate any further recommendations you may have to improve the model’s accuracy.
Additionally, I will be trying out image classification today as well, and I hope it will yield better results.
Sorry for the late reply I was off for a few days.
We have a beta version of the EON tuner for Object Detection, if you’re interested in testing it, could you share your project ID so I can grant you the access?
I was wondering when the EON tuner will be deployed, as I am having similar issues creating an Akida Model to detect Cracks and Spalls in concrete. I have a smaller sample size at the moment given the time it takes to train (keeping it under the 20 minutes), but results are not very encouraging at the moment, with no crack accuracy, and the best I can get is about 40% on my spalls (512x512 images, using bounding box to encase the crack/spall). In most cases, the crack/spall covers up to 25% of the photo. I’ve tried a few learning rates and number of epochs, but to keep it under 20 minutes really limits any success.
The project is shared here:
[Brainchip with good photos - Dashboard - Edge Impulse]