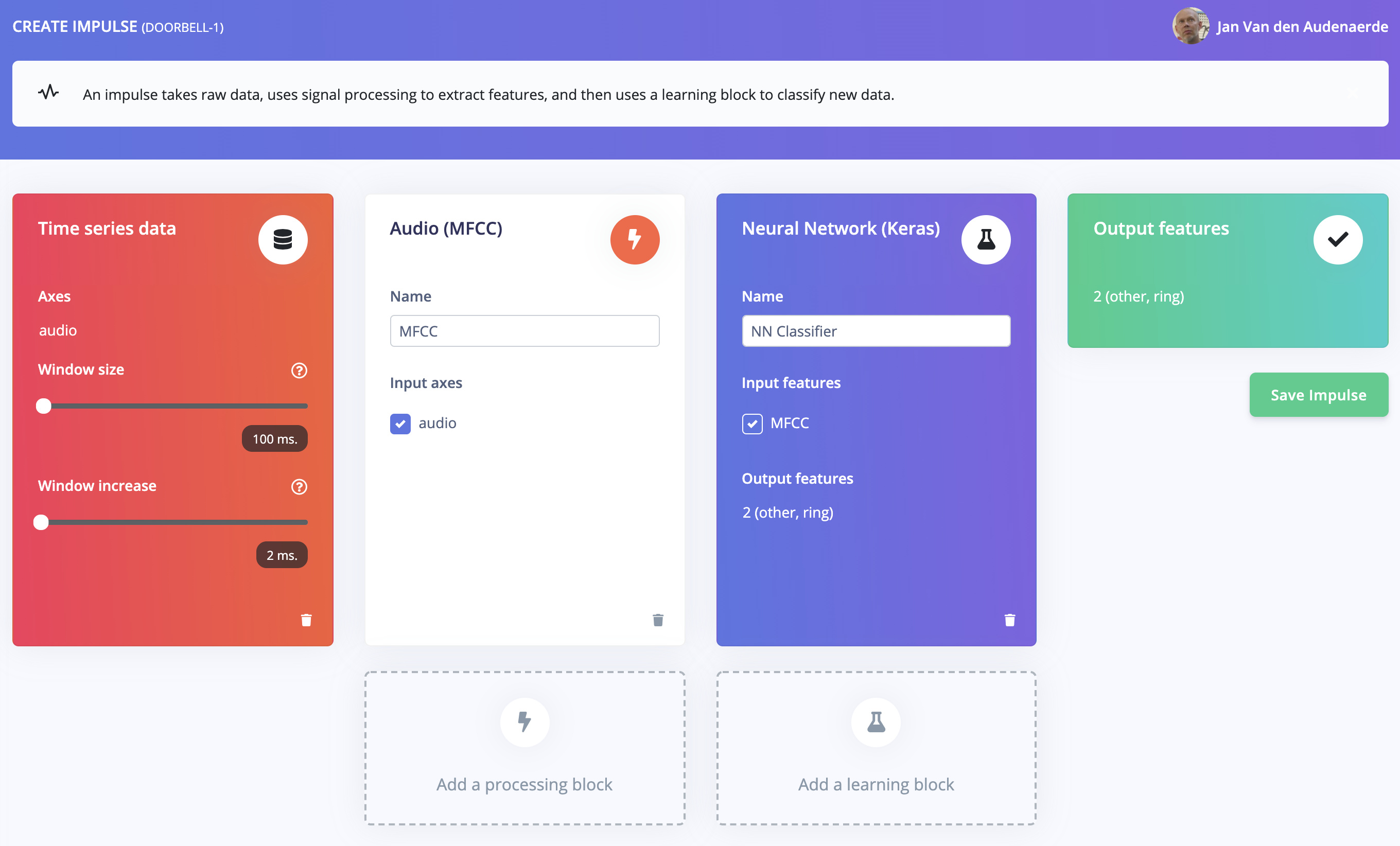
6. (MFCC) Conclusion
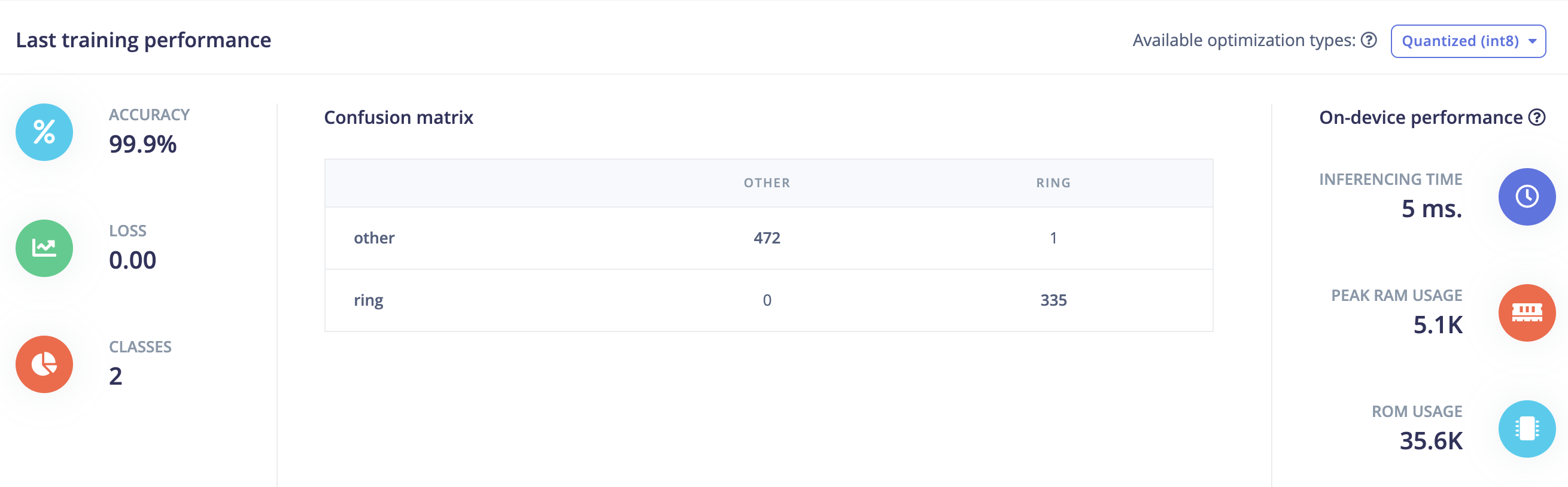
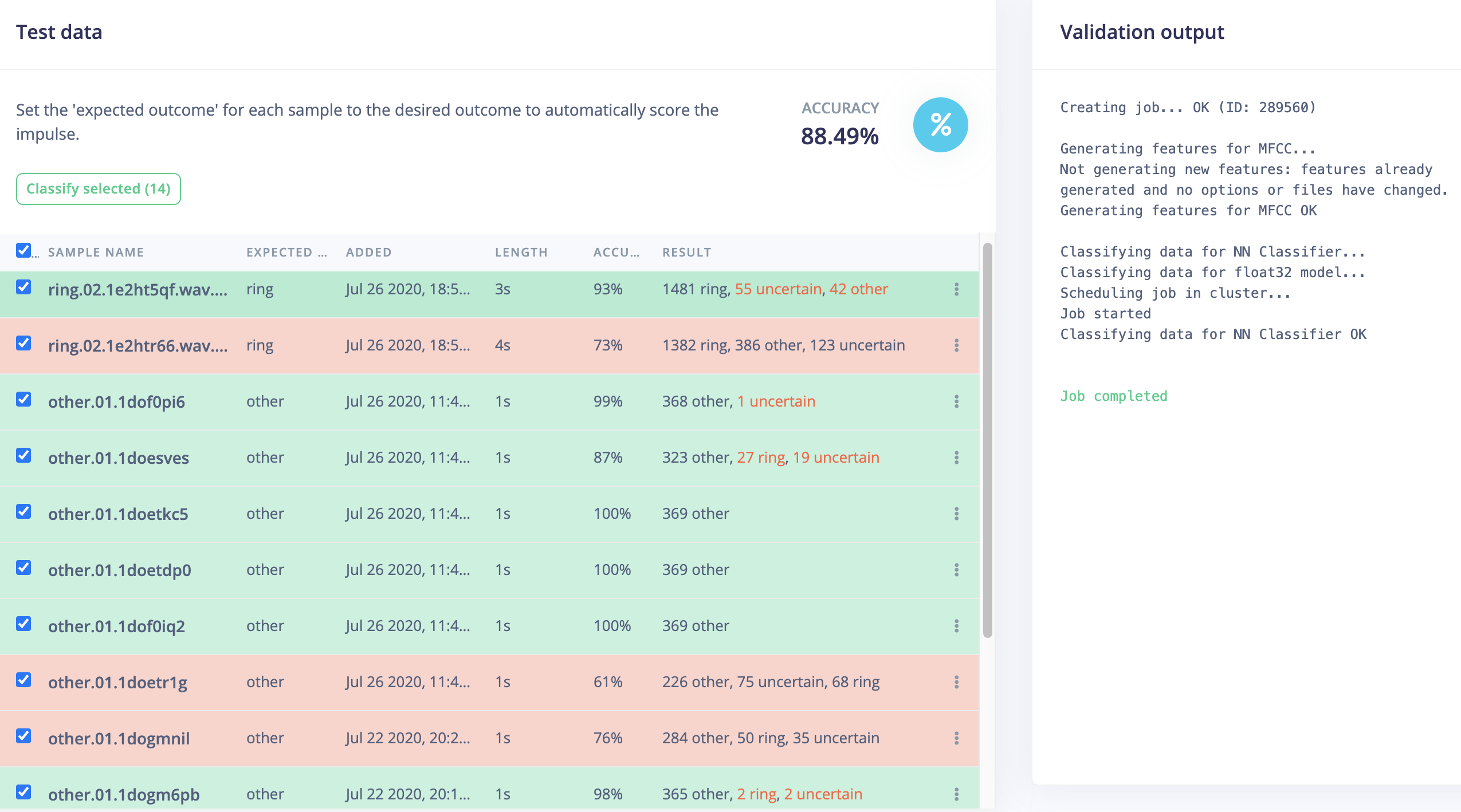
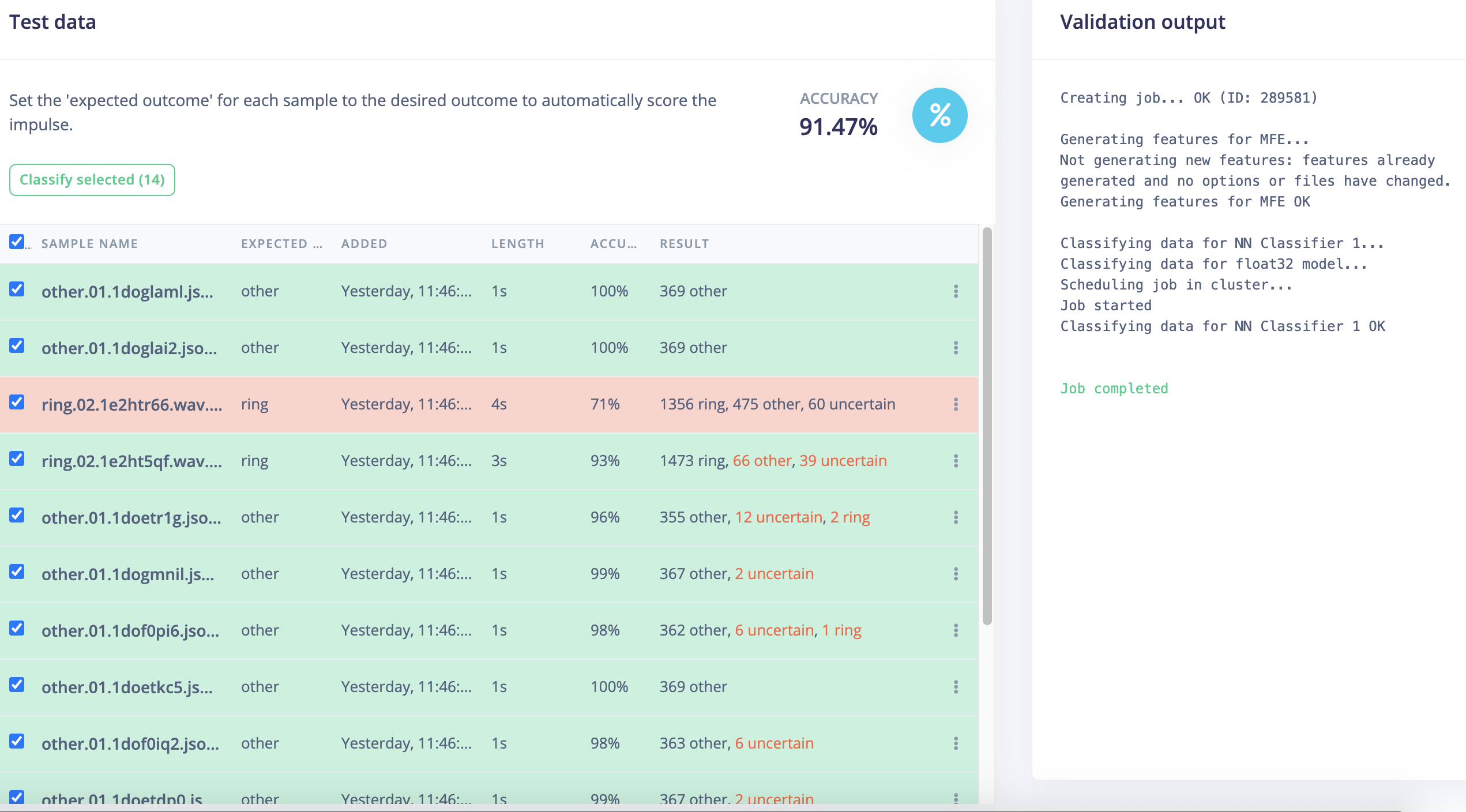
Although reporting an excellent training accuracy of 99.9% but when testing on other audio fragments it classified many “non-ring” sounds as “ring”. This makes it not really usable to detect “rings” due to too many false positives.
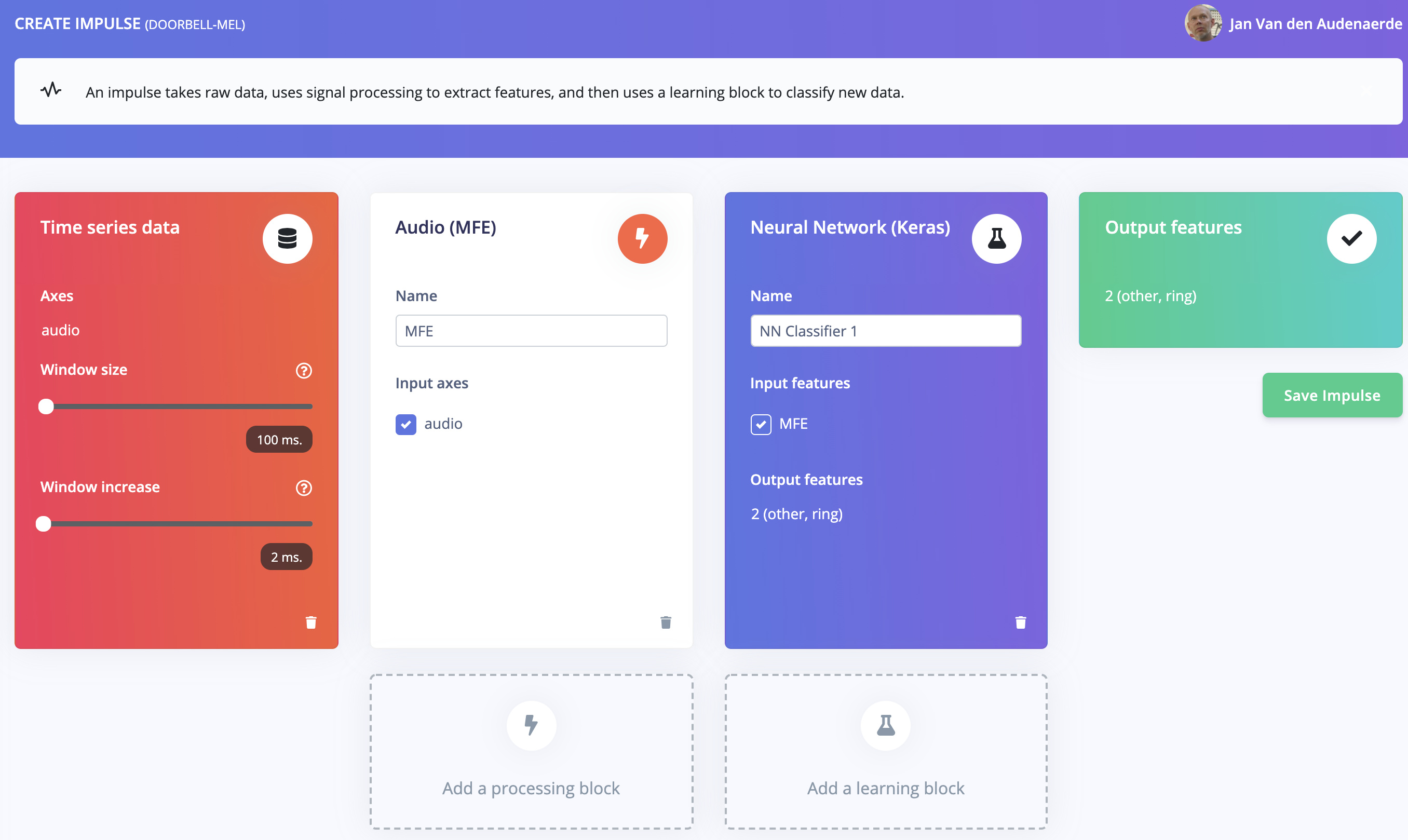
In response to this post, I will share the MFE results…
In this response you find the outcome of testing with MFE block instead of MFCC block.
Note that I have used exactly the same set of training data and test data for this comparision.
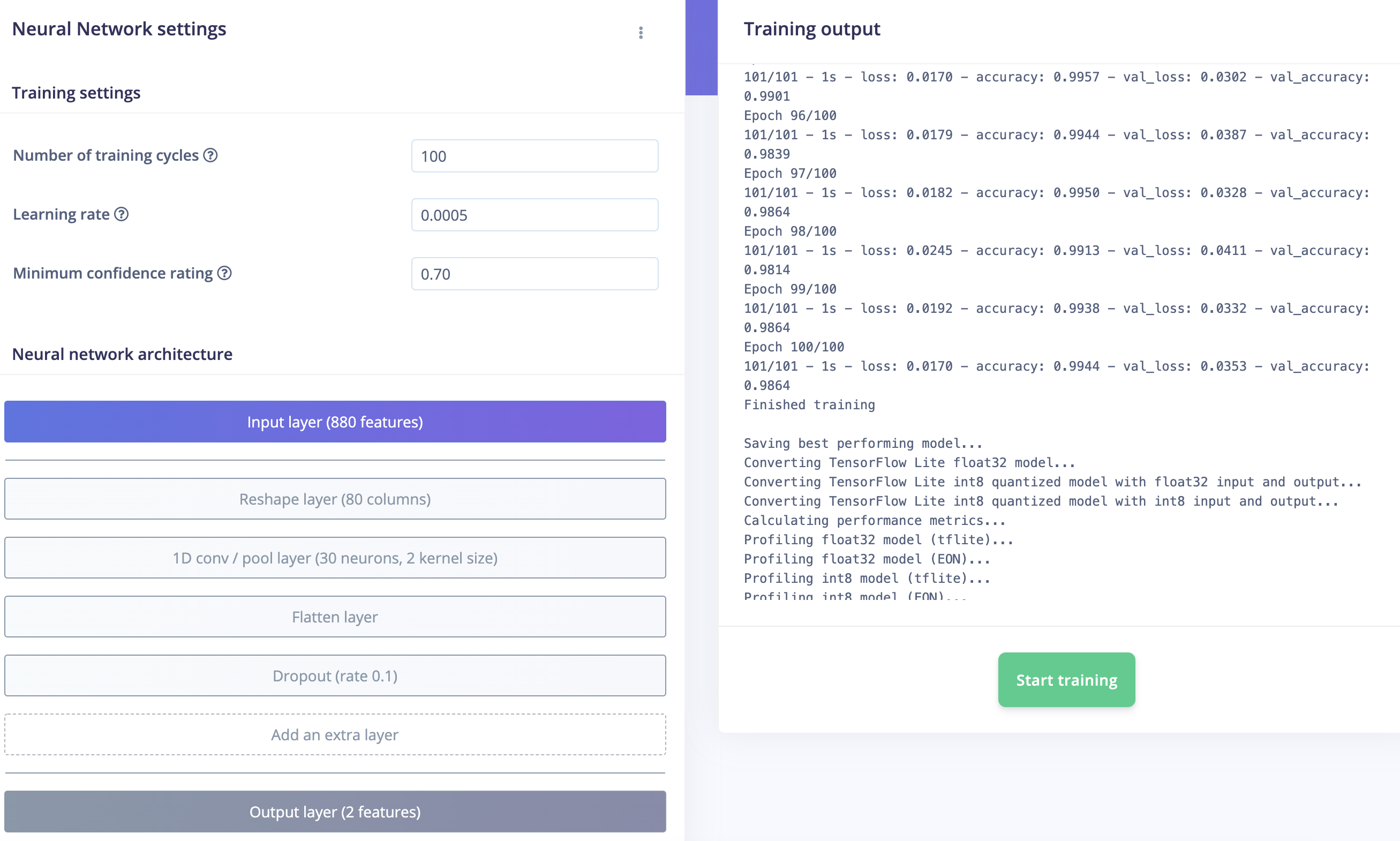
6. (MFE) Conclusion
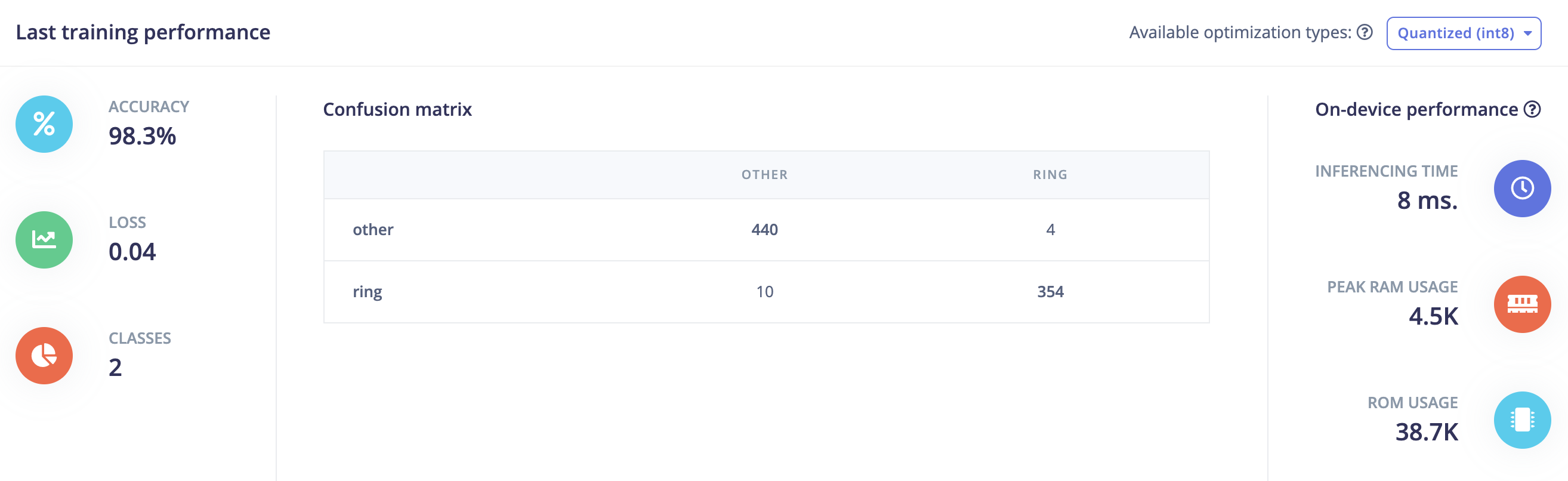
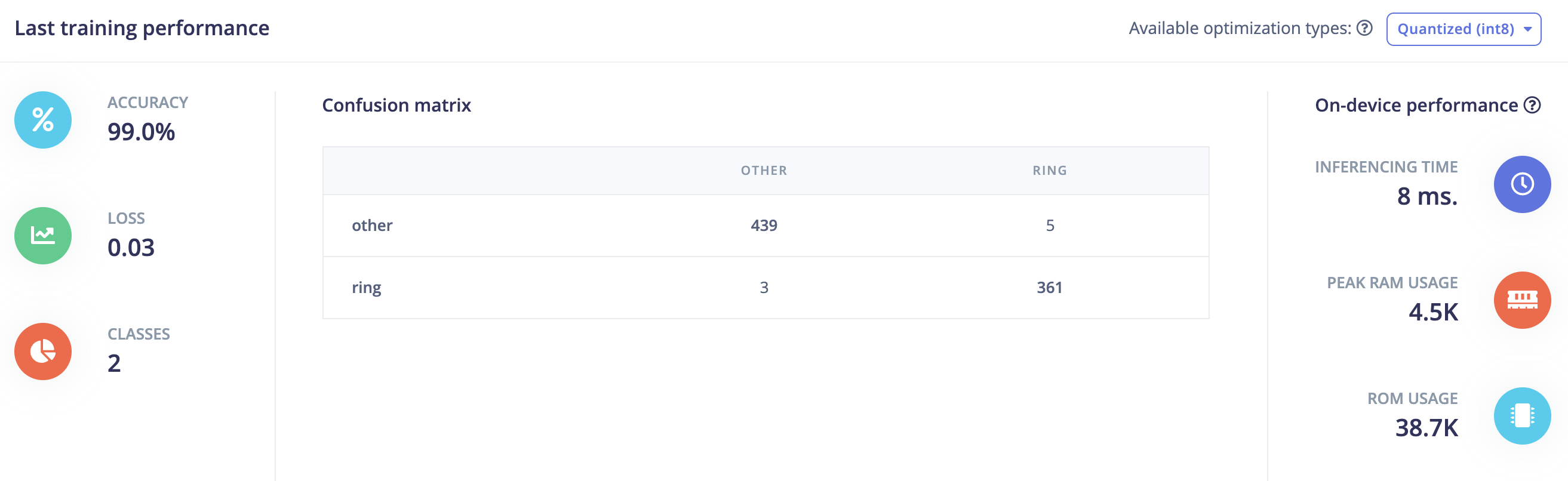
Although reporting a lower training accuracy (98.3%) compared to MFCC (99.9%), testing on other audio fragments gave better results:
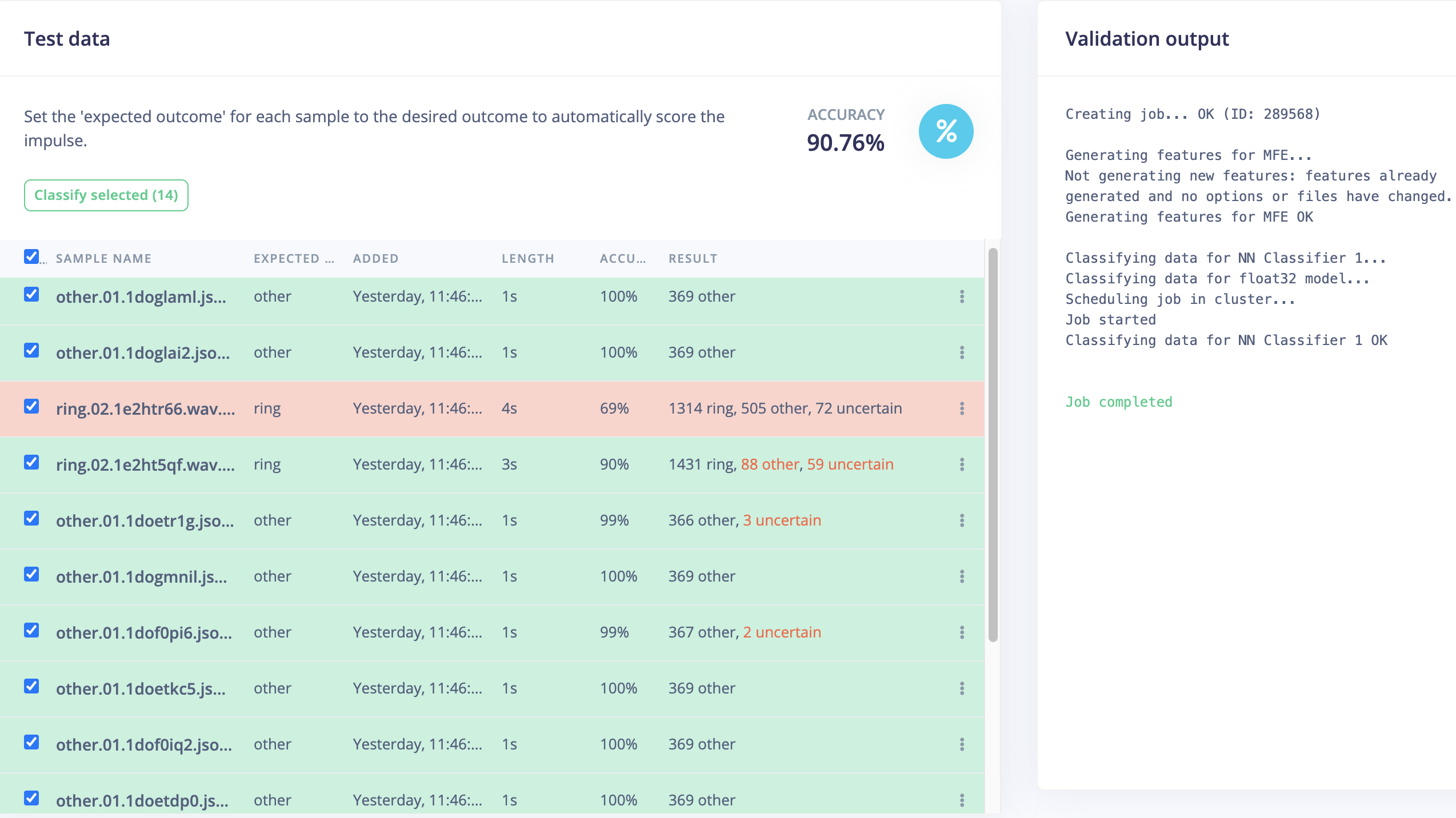
slightly better accuracy (90.76%) compared to MFCC (88.49%)
but more important No FALSE POSITIVES !
there are also some “FALSE negatives” (especially for one ring audio fragment).
So the outcome is certainly promising and more useful than MFCC (despite higher training accuracy).
@janvda Really hopeful results! You’re still overfitting by a bit, maybe a dropout layer of 0.1 after flatten would help? We’re also adding some data augmentation to audio data next week, that should help with smaller datasets.
Some other tips that would help on the inferencing side to make this robust:
If you collect a second of data, don’t classify once, but use the sliding window approach to classify a bunch of slices of the data.
If you see >70% ring windows this is a very strong indication that there was a ring.
Together that will probably get you a deployment with barely any false positives / negatives.
I think one of the issues is that there are in fact not really 2 classes but 4:
no sound (only background noise)
ring
sound X (e.g. person speaking / radio)
ring + sound X
So I think the issue is that the model is categorizing “ring + sound X” to category “other” when “sound X” is more “dominant” than the “ring” sound in the audio fragment.
I understand that one way to overcome this problem is to train the network also with all possible combinations of sound “ring + sound X” and “sound X without ring”.
Yes, I understand. So one “ring” classification is not sufficient to conclude the doorbell rings, for that you must have at least 2 “ring” classifications in a row (or even more complex conditions like at least 3 ring classifications in a series of 5 subsequent classifications).
Of course we must take care that a ring can be short (a few 100ms long) - so we must assure that multiple classifications are done covering any period X (where X is the minimal ring period we want to be able to recognize).
@janvda Yeah, e.g. take a 600 ms. recording, then classifying 500ms. windows with 20ms. frame stride would give you the 5 classifications. Based on your dataset it looks like that would work.