The use case:
Our doorbell is not clearly audible at the 2nd floor or in the garden.
I have an intel NUC6CAYS device (with embedded microphone) running docker.
I would like to create a docker service that is constantly listening for the doorbell sound and which will publish a message to my MQTT broker whenever someone rings the doorbell.
Another docker service will subscribe to this MQTT message and somehow notify me.
Solution
I would like to use Edge impulse to train the model and run it in a docker service on my intel NUC.
My doorbell
A picture of my doorbell : <picture to be added once I have the right to add more than 1 picture to a forum post>
A 1 minute spectogram covering 9 bell rings : <picture to be added once I have the right to add more than 1 picture to a forum post>
Here below the spectogram (produced by audacity) covering a single bell ring
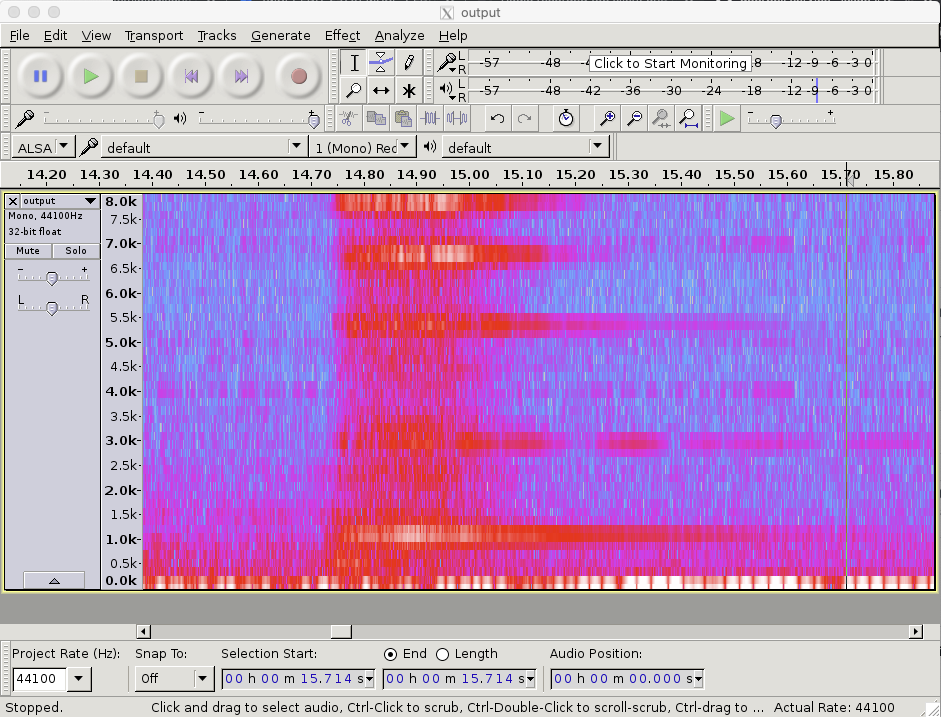
You can see that bell ringing started at 14.75 sec and then ran at full power until 15.00 sec (duration = 250 ms) and then gradually faded until about 15.60 ( duration = 600 ms). Of course people can press longer on the bell.
My questions
Some guidance / hints regarding how to best train the model for this use case.
Any hints about proper starting parameters for training are very welcome.

