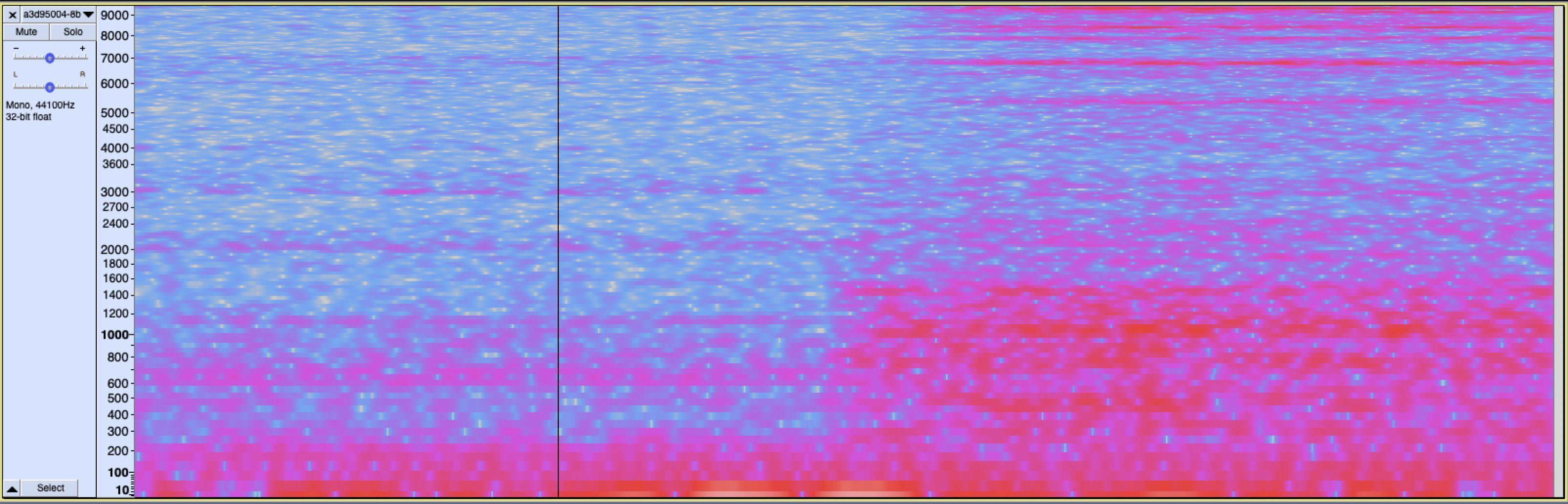
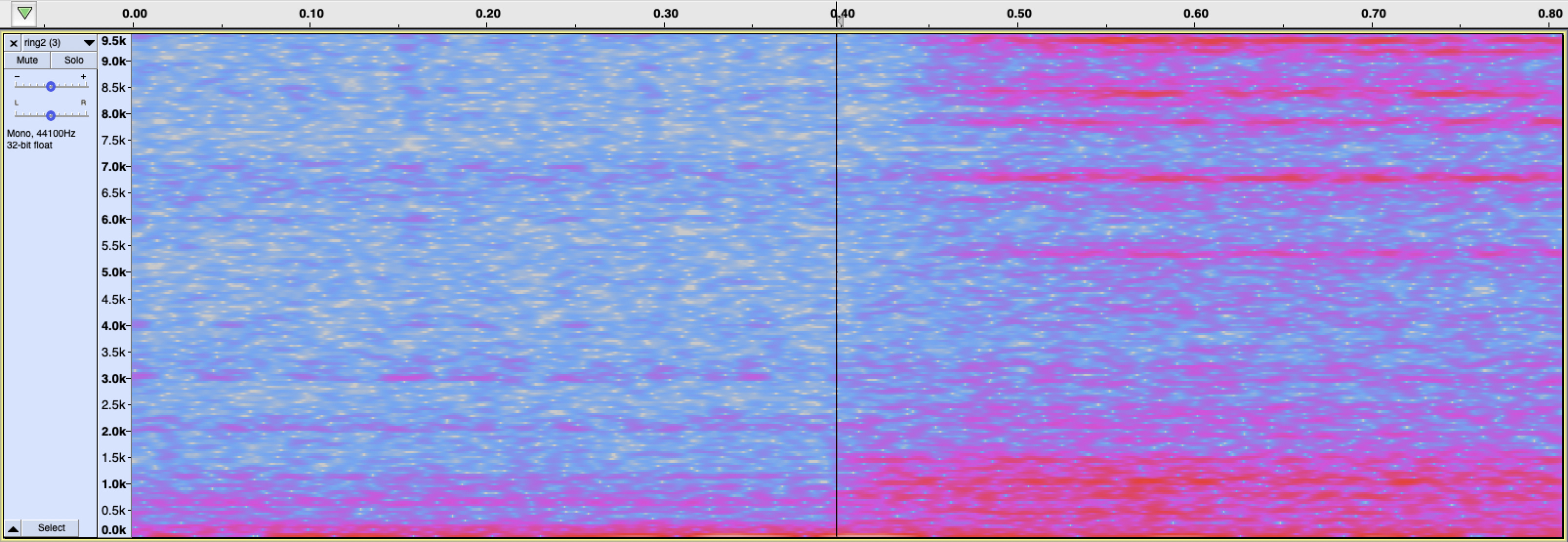
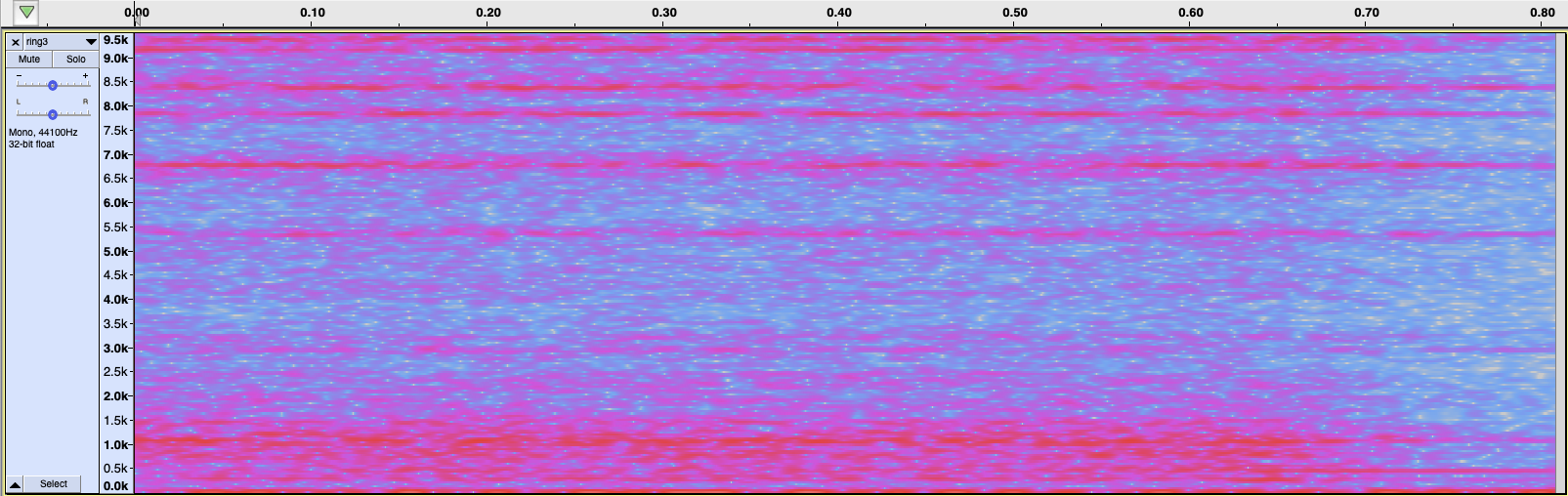
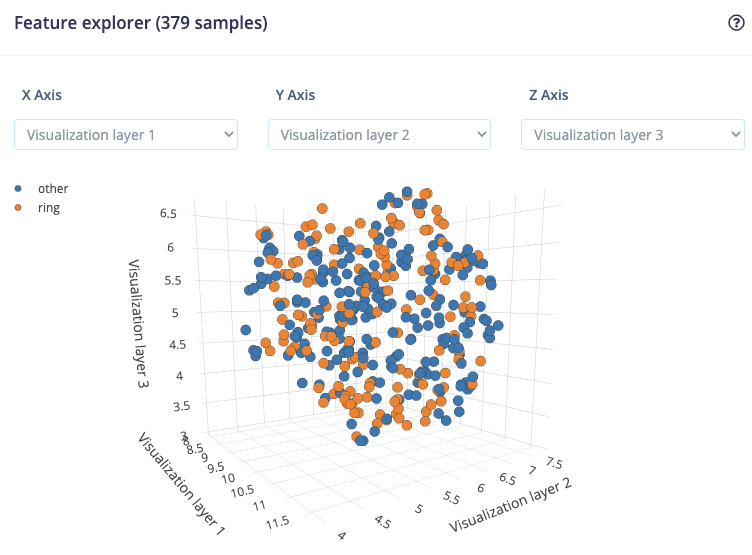
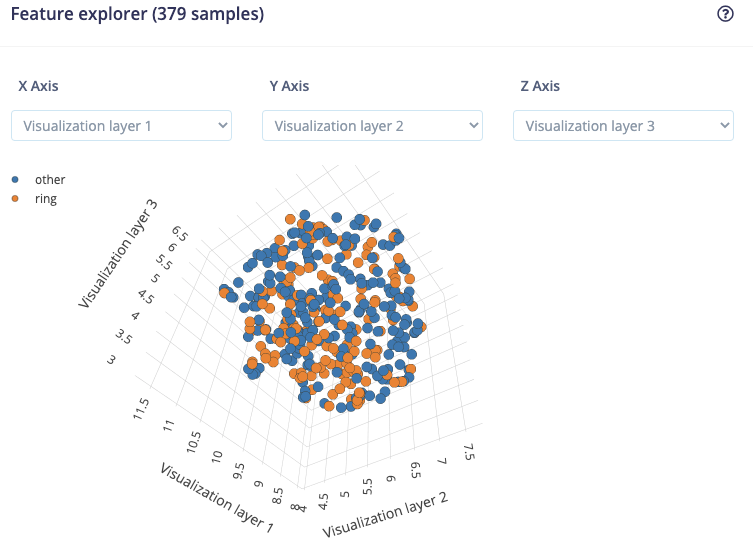
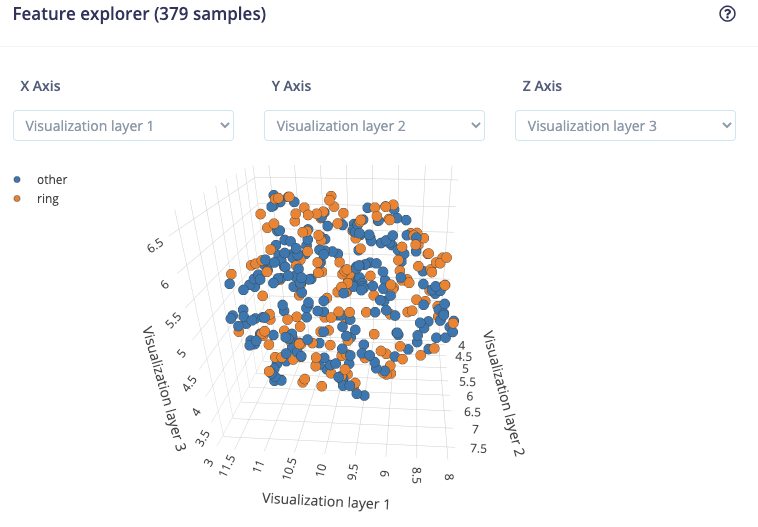
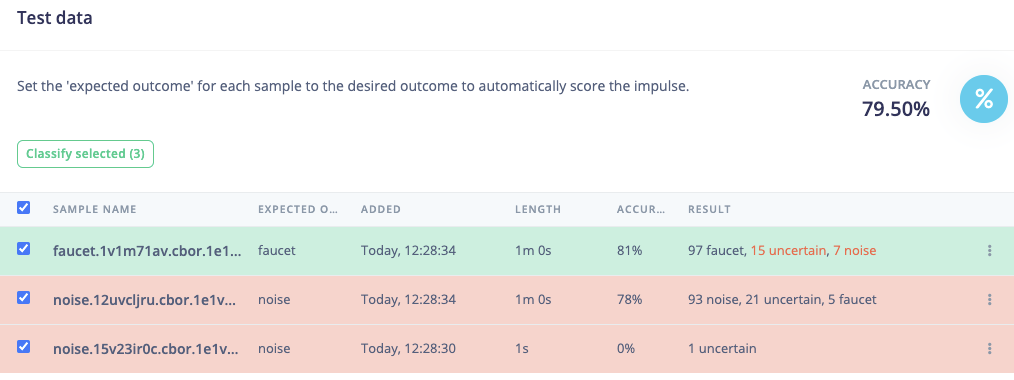
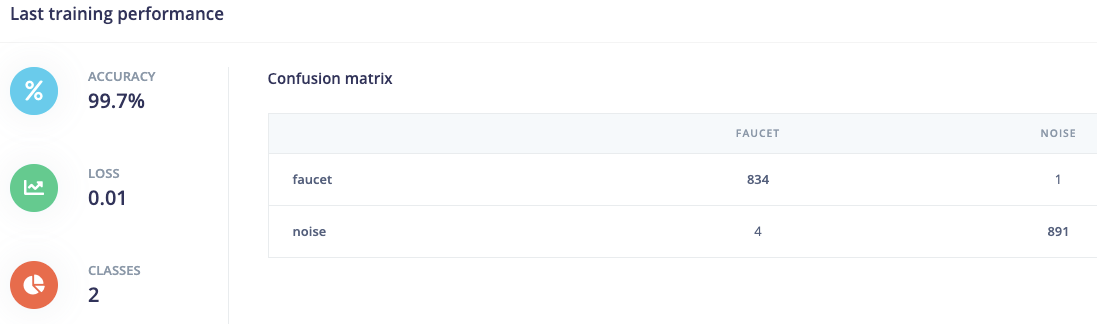
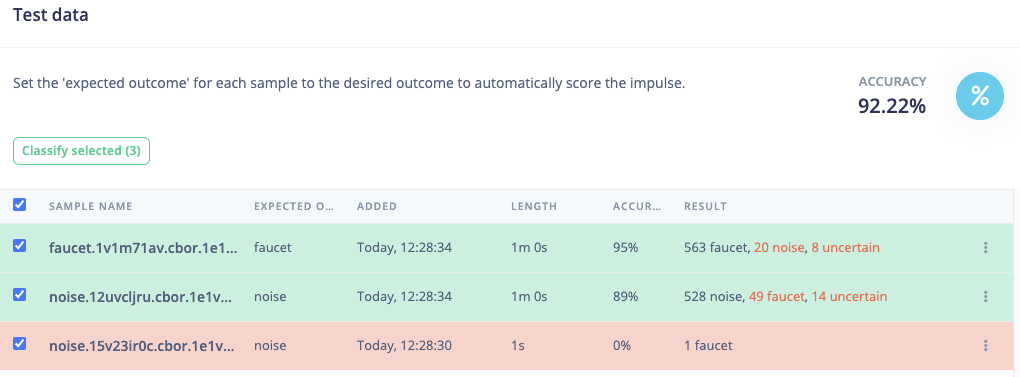
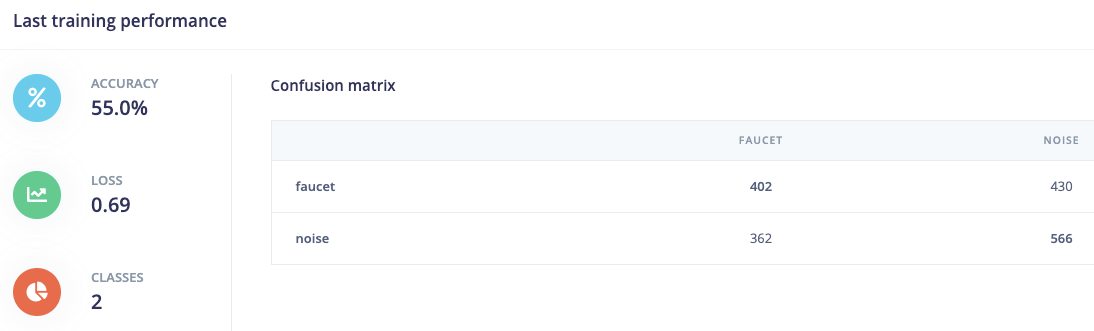
@aurel, thanks for your support.
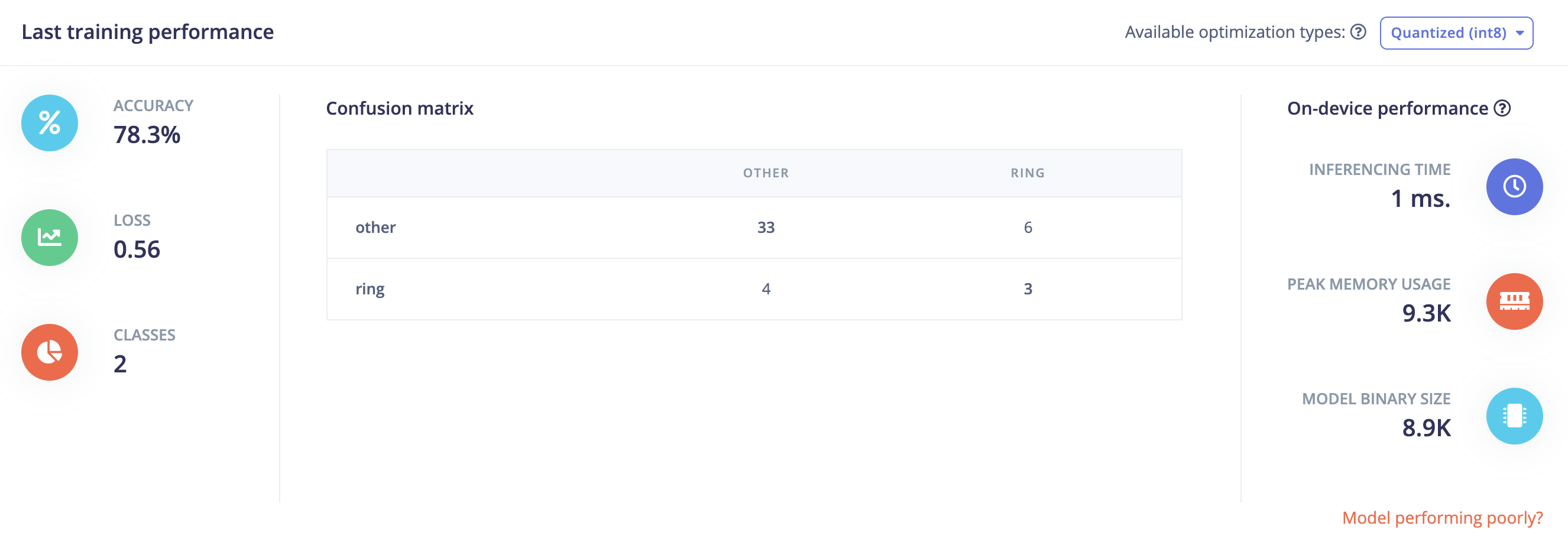
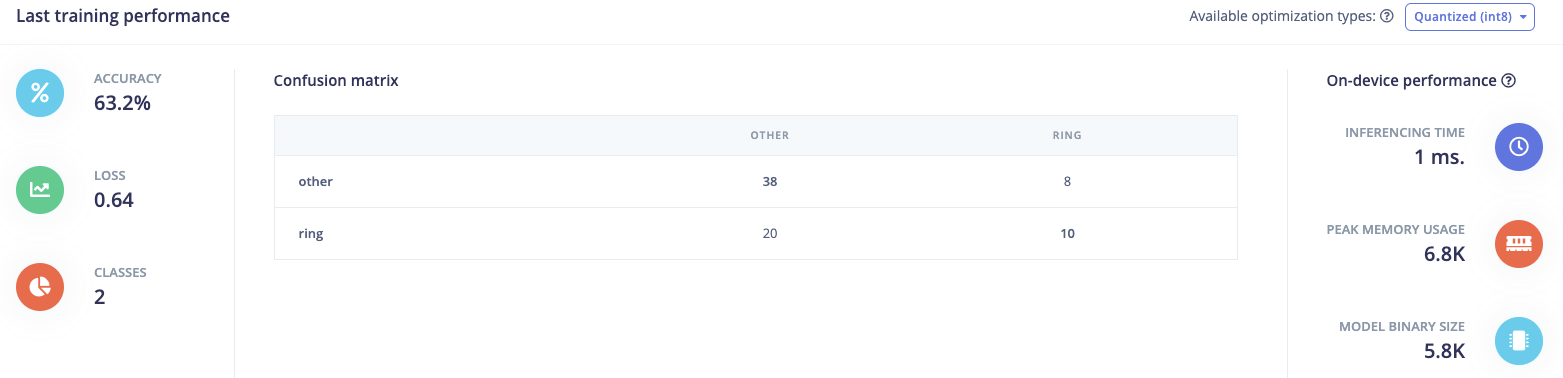
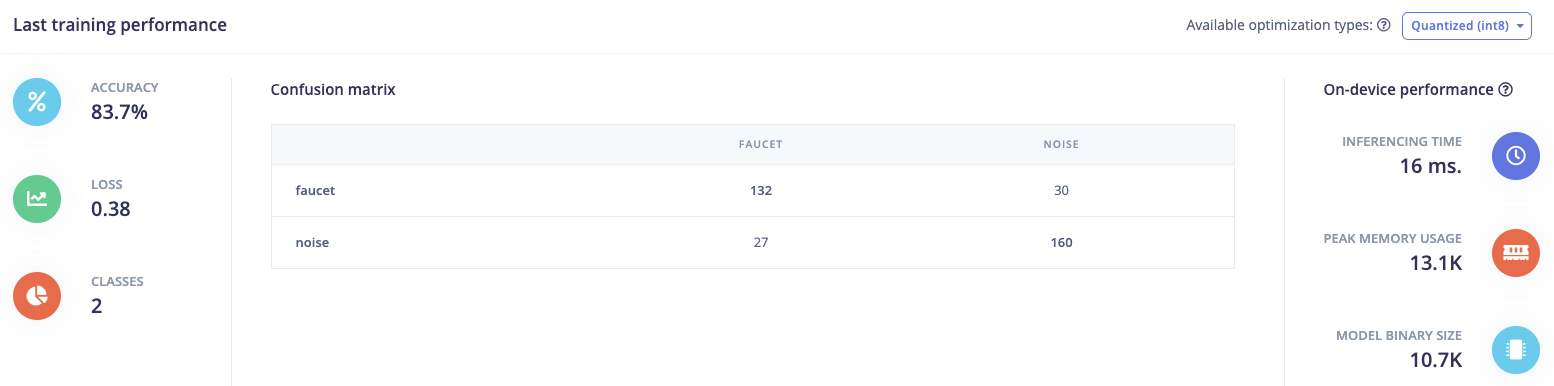
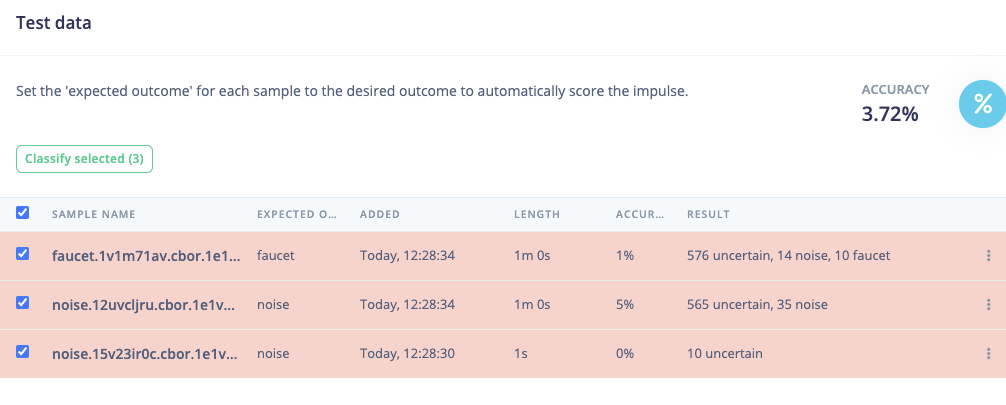
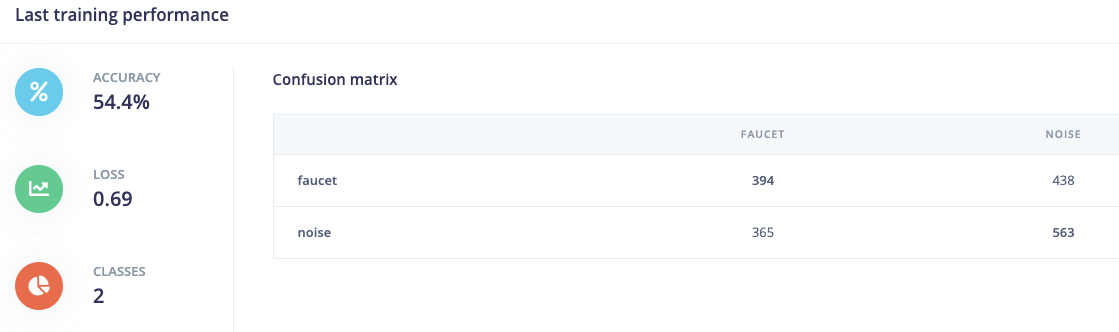
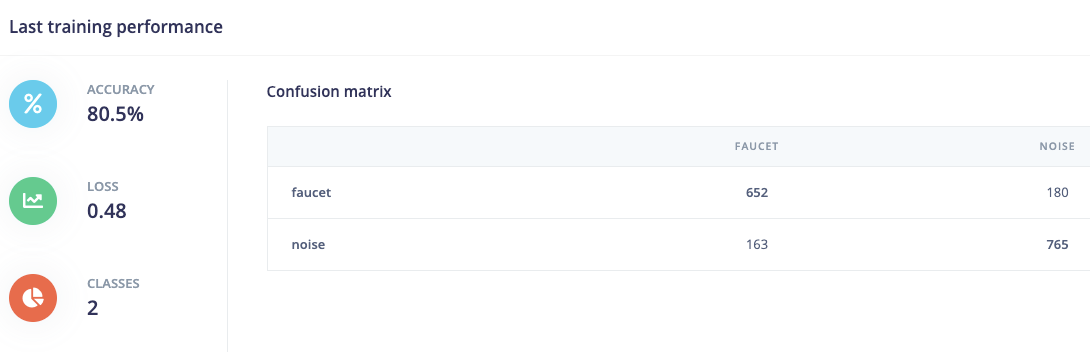
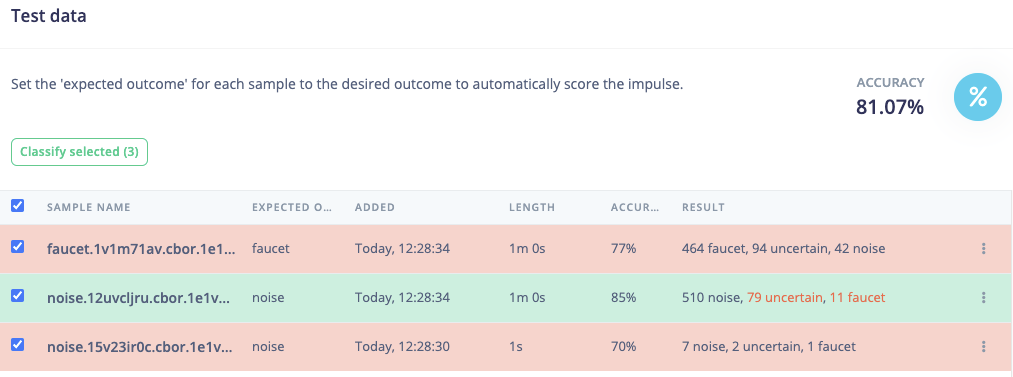
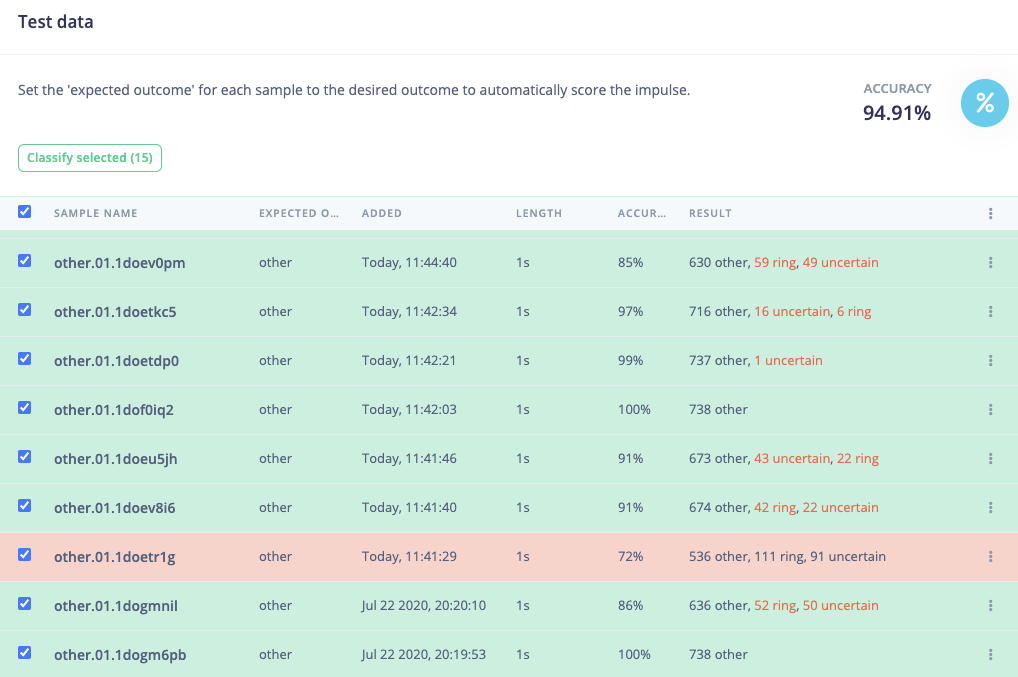
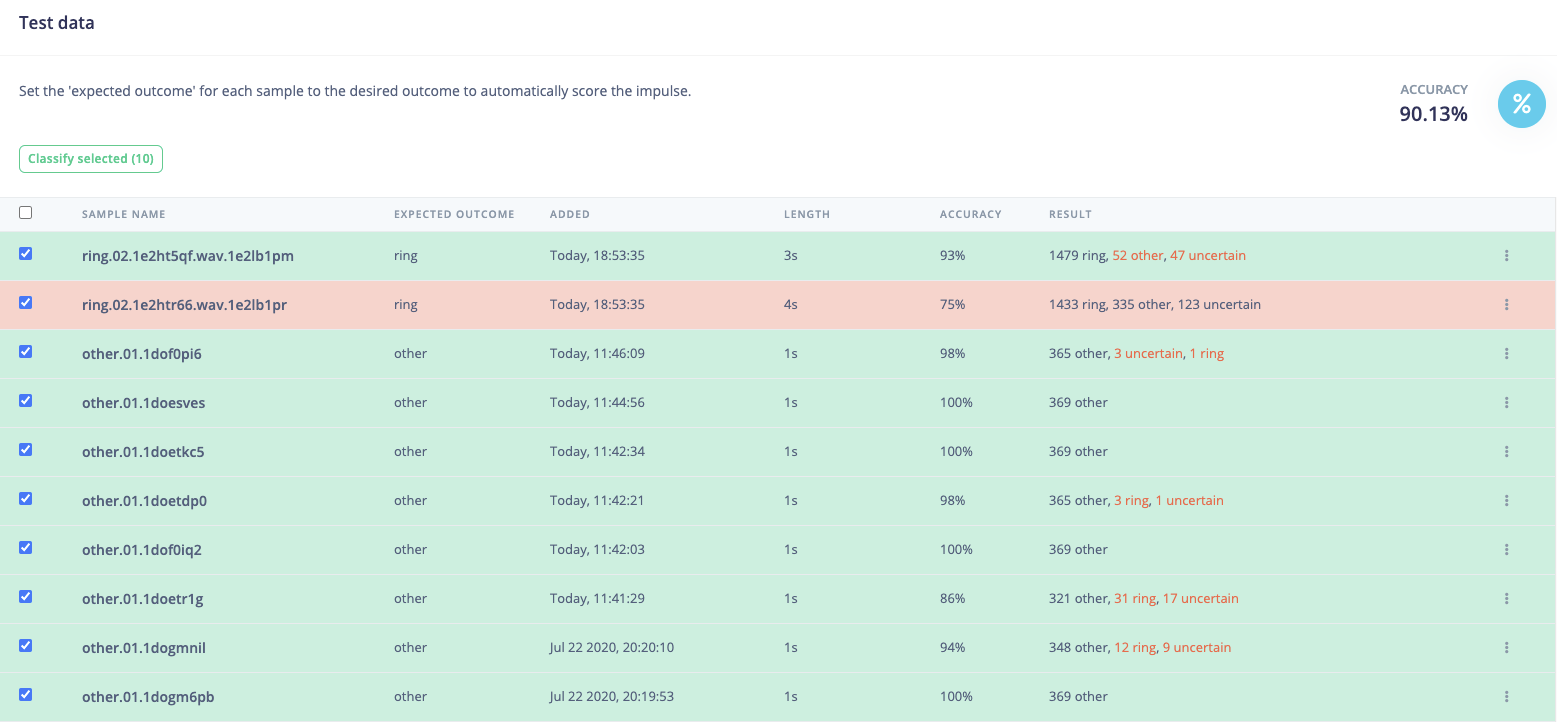
I managed to train a NN but the results are not really good. According to the confusion matrix it is classifying more than halve of the rings as “other”.
I am still thinking that there is problem with the input for the NN.
The Details of the NN training:
So I have cropped all my audio recordings containing ringing sounds so that they only contain the actual “ring” and not the period before or after it.
I have set
- the window size to 100 ms and window increase to 50 ms and
- the minimum confidence rating to 0.7
- default settings for the MFCC parameters:
My data set is not very balanced so I have added the following to my NN architecture:
from sklearn.utils.class_weight import compute_class_weight
class_weights = dict(enumerate(compute_class_weight('balanced', np.unique(np.argmax(Y_train, axis=1)), np.argmax(Y_train, axis=1))))
...
model.fit(train_dataset, epochs=300, validation_data=validation_dataset,class_weight=class_weights, verbose=2, callbacks=callbacks)
FYI : the full definition of my NN model
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, InputLayer, Dropout, Conv1D, Conv2D, Flatten, Reshape, MaxPooling1D, AveragePooling2D, BatchNormalization
from tensorflow.keras.optimizers import Adam
from sklearn.utils.class_weight import compute_class_weight
class_weights = dict(enumerate(compute_class_weight('balanced', np.unique(np.argmax(Y_train, axis=1)), np.argmax(Y_train, axis=1))))
# model architecture
model = Sequential()
model.add(InputLayer(input_shape=(input_length, ), name='x_input'))
model.add(Reshape((int(input_length / 13), 13), input_shape=(input_length, )))
model.add(Conv1D(30, kernel_size=4, activation='relu'))
model.add(MaxPooling1D(pool_size=4, padding='same'))
model.add(Conv1D(10, kernel_size=1, activation='relu'))
model.add(MaxPooling1D(pool_size=1, padding='same'))
model.add(Flatten())
model.add(Dense(classes, activation='softmax', name='y_pred'))
# this controls the learning rate
opt = Adam(lr=0.00005, beta_1=0.9, beta_2=0.999)
# this controls the batch size, or you can manipulate the tf.data.Dataset objects yourself
BATCH_SIZE = 32
train_dataset, validation_dataset = set_batch_size(BATCH_SIZE, train_dataset, validation_dataset)
callbacks.append(BatchLoggerCallback(BATCH_SIZE, train_sample_count))
# train the neural network
model.compile(loss='categorical_crossentropy', optimizer=opt, metrics=['accuracy'])
model.fit(train_dataset, epochs=300, validation_data=validation_dataset,class_weight=class_weights, verbose=2, callbacks=callbacks)
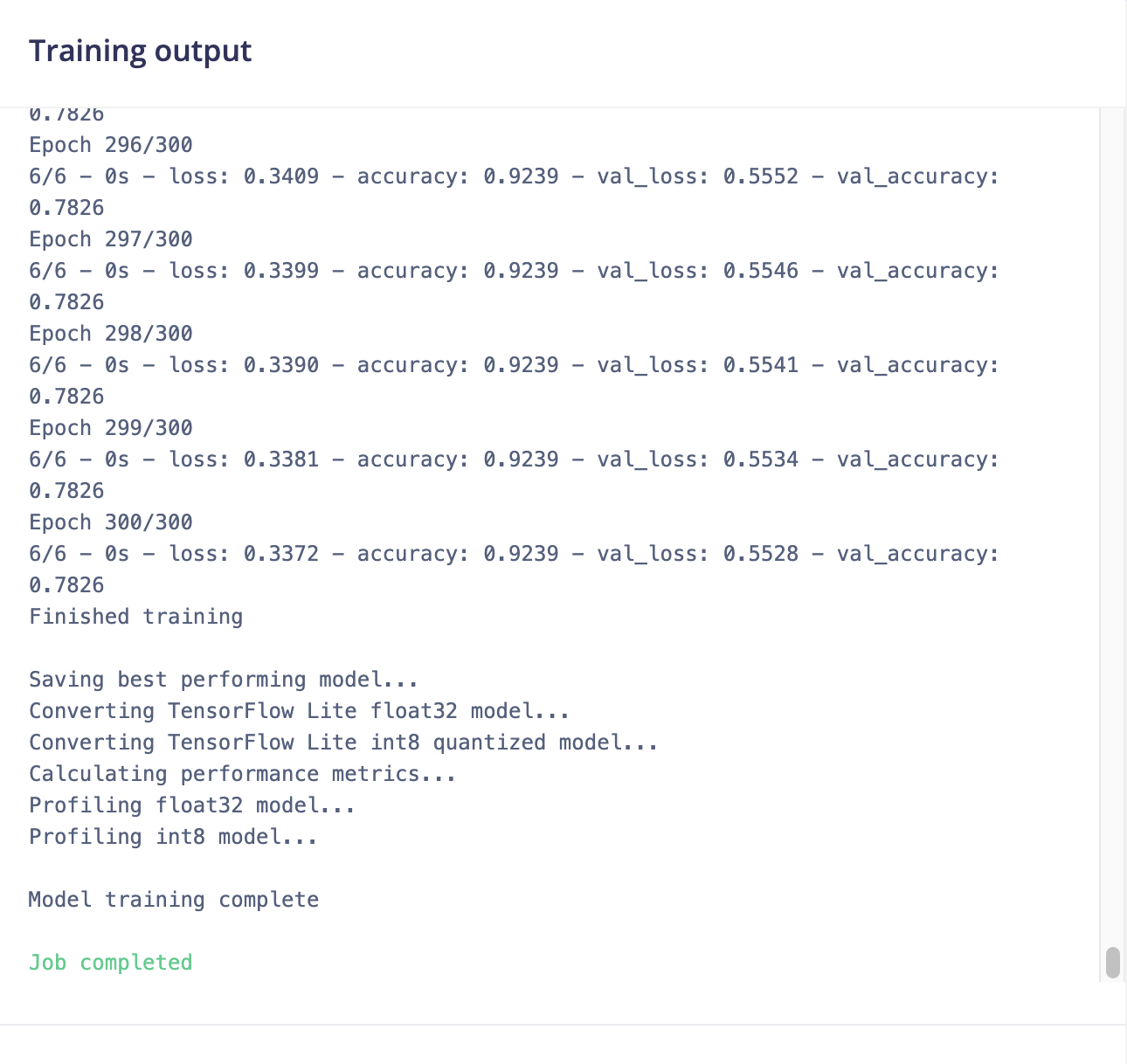
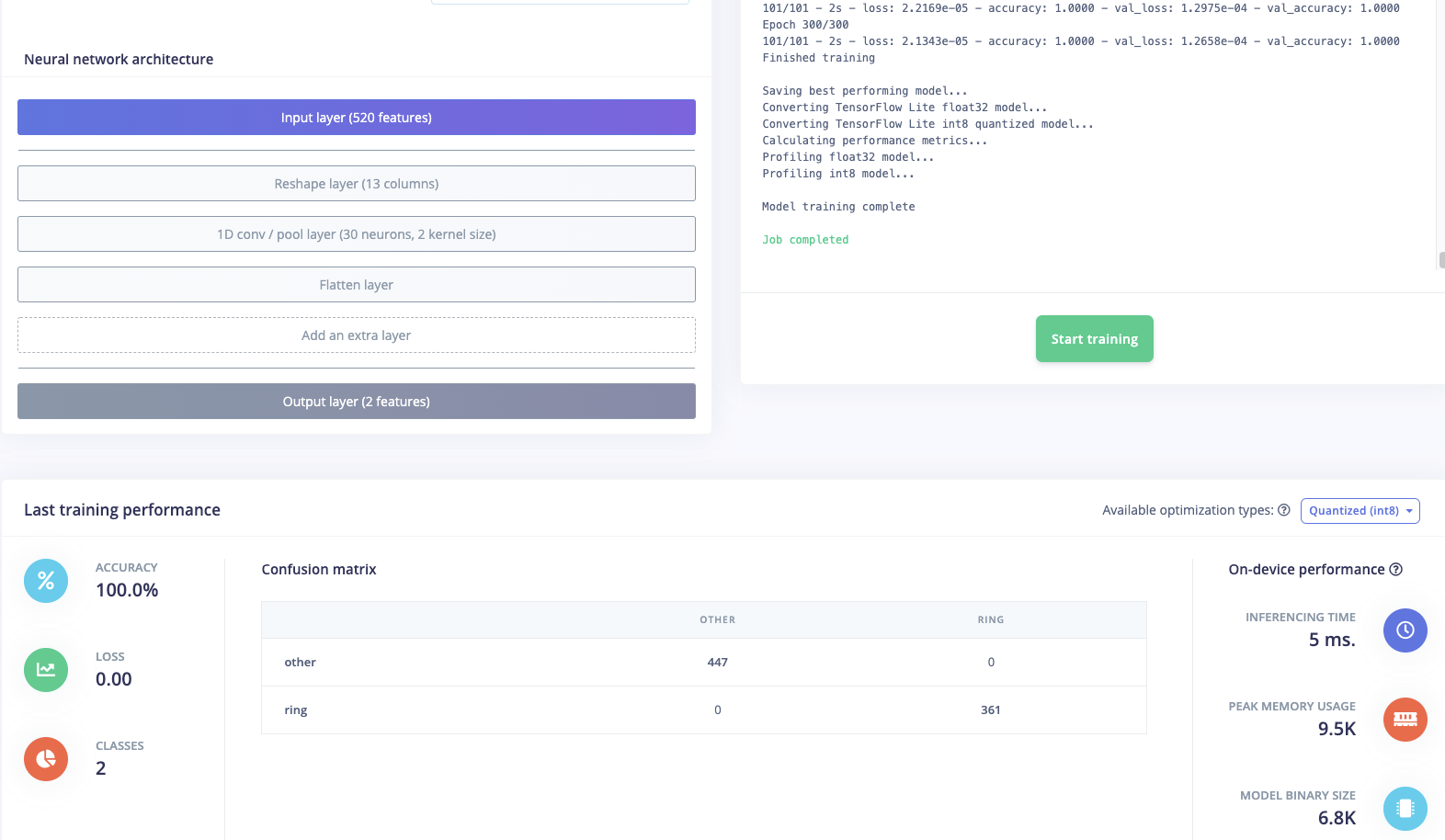
This is my training output:
This is my training performance: