Hello there,
I have created a project on Edge Impulse, in order to detect different voice commands.
The voice commands go from 0.5 seconds to 1.5 seconds, all recorded with the Nano 33 BLE Sense microphone, with variations in intonation, pronounciation, distance and angle compared to the mic. After that all samples were cropped to contain only the actual keyword, removing any in-between noise.
Here is the breakdown:
- 21 classes (4 classes for 4 types of noise)
- 50 samples per class, totalling 1351 samples
- 1215 training samples, 136 testing samples
- 624 features per class
After a multitude of tests with updates to the MFCC and CNN, I get to 92.1% accuracy on the testing samples, the only misrecognised samples were the different types of noise, which is fine.
Then I build it as a library for Arduino, I add it to Arduino, compile it and upload it and the accuracy is actually quite bad.
I edited the code so instead of displaying the prediction class and percentage of certainty, it just displays the name of the class if that specific class had a higher than 80% classification probability. Even tried with 85, 90, 95, 98. It is not good at all and it misclifies quite frequently.
Now going back to the beginning, before doing this NN and reaching 92.1% accuracy, I had a model with the same amount of commands, with 50 samples each, but only 1 brown noise class, so in total there were 17 classes. With different parameters I reached 99.1% accuracy on the 10% validation set.
The voice commands are as follows:
- "What is the Rainfall Forecast? "
- “Temperature”
- “Humidity”
- “Altitude”
- “Heat Index”
- “Current time”
etc.
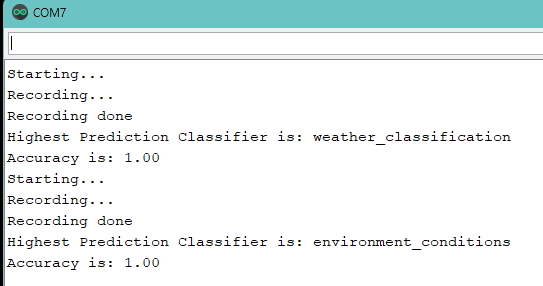
Now, the issue that I have is that if I record some samples, with the arduino nano mic(same as before), and then use those for classification in the “Model Testing”, it gets all correct, having 100% accuracy.
Can I get some help on what I am doing wrong? Would I need to reduce the number of classes as they are too many? Should I highly increase the train/test split?