@shawn_edgeimpulse Many many thanks for all the answers and support given throughout Shawn!
In regards to the system, I am doing interference on recorded audio, not continous. I have also not modified the library, only the nano_33_sense_microphone example code to suit my needs.
Just to mention, I have not run in any of the issues that I answed about, I was just curious to learn more about what could cause it to fail and how the library performs these checks that’s all.
You can rest easy now haha, my questions have been exhausted and the model is finished, still have to run 400/500 cycles and call it a day.
@shawn_edgeimpulse Last question I promise.
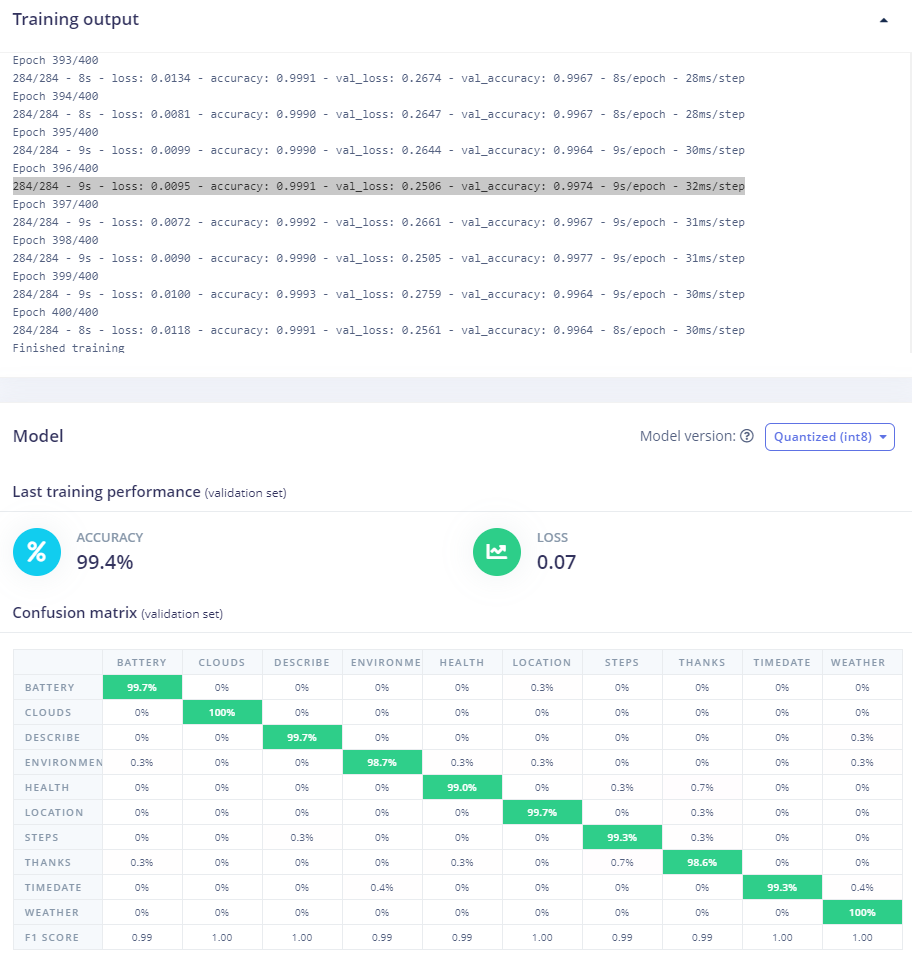
How does the training system choose the best model? I would expect it to be based on loss and validation accuracy, no?
Here I have many models with loss of 0.02 and accuracy of 99.7 or 99.8 and yet at the end of the training, it shows me 99.4% and 0.07 as best. How come? Is the lesser performance caused by the optimisation processes?