Today the new BBC micro:bit was announced, the successor of the highly popular BBC micro:bit. While it retains the same form factor it now packs a microphone and a speaker, and a much more powerful MCU. And what better way to demonstrate these features than by adding some Machine Learning to the new micro:bit?!
@rasp good question… I’m using arm-none-eabi-gcc (GNU Arm Embedded Toolchain 9-2020-q2-update) 9.3.1 20200408 (release) rather than 10, that might have something to do with it?
Greetings Jan and everyone else at Edge Impulse.
Thank you for the nice tutorial, each step was well comprehensible.
After fixing the local toolchain I also got a successful build done and deployed the hex-file, but nothing was recognized.
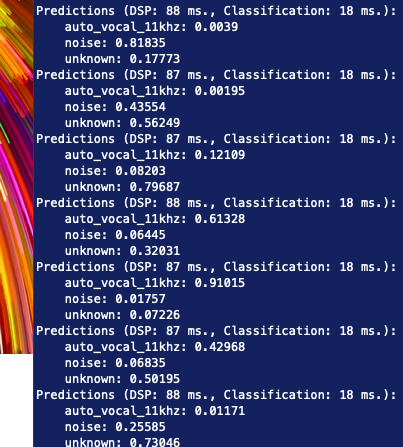
The terminal shows results like this: “Predictions (DSP: 88 ms., Classification: 19 ms.):
auto_vocal_11khz: 0
noise: 0.81835
unknown: 0.17968
Predictions (DSP: 88 ms., Classification: 18 ms.):
auto_vocal_11khz: 0
noise: 0.84374
unknown: 0.15624”
So my sample keyword (“auto”) is not recognized? What could be the reason? Test- and sample-data was derived from my smartphone. Model looked quite well in the browser, but obviously not on the micro:bit v2.
Could there be a problem with the differences between the two microphones?
@marcelpetrick When running in continuous mode we run a moving average over the predictions to prevent false positives. E.g. if we do 3 classifications per second you’ll see ‘auto’ potentially classified three times (once at the start of the audio file, once in the middle, once at the end). However, if your dataset is unbalanced (there’s a lot more noise / unknown than auto in your dataset) the ML model typically manages to only find your keyword in the ‘center’ window, and thus we filter it out as a false positive.
You can fix this by either:
Add more data
Or, disable moving average by going into ei_run_classifier.h (in the edge-impulse-sdk directory) and removing:
for (size_t ix = 0; ix < EI_CLASSIFIER_LABEL_COUNT; ix++) {
result->classification[ix].value =
run_moving_average_filter(&classifier_maf[ix], result->classification[ix].value);
}
You’ll now see predictions go up:
(this was while playing a sample from your dataset over my speakers, you might see confidence go up a bit less).
@janjongboom Thank you very much for the input. I went for the second idea: disable code; allow false positives. Yes, the confidence rises up to 0.84, but this is not enough to be recognized.
I will try to add now much more data. If this does still not work, I will go for the suggested keyword “microbit”
@janjongboom Confidence was the wrong term. Classification accuracy is the one I mean. The one shown for each label in the microbit-serial-output.
I’ve tried to add more data, this time sampled with Audacity and I had set it to 11 khz, but training reported slight mismatch. Guess I will re-record with the phone, like before xD And also remove outliers from the training data.
edit: After some more data-sampling, cleaning (I like the interface to review the dataset as a cloud!) and re-training I found the culprit and got my example running.
The keyword used in the MicroPhoneTest.cpp has to match character by character the label used for training! I’ll make a PR on github. My label was “auto_11khz”, the one in the source “AUTO” xD
This is a great project idea. Therefore I ordered a micro:bit V2 .After a few month it actually arrived. I would like to install Voice Activated Micro:bit. The Edgeimpluse part worked perfectly. However, I need some help with compling. Where can I get some instruction on the cross compling part? (Python, CMake and GNU ARM Embedded Toolchain 9). I tried on W10 and raspberry pi, but I just cannot really work it out. PS: This is my first experence in this field, even if it has not (yet) worked, I already learned a lot, it’s very interesting indeed, thanks anyway
I cloned your code from Github (https://github.com/edgeimpulse/voice-activated-microbit) and I tried building it. However, it does not work for me. I’ve installed Docker and everything else that you requested, but it still does not build the dependencies (I get errors wight after this command “docker run --rm -v ${PWD}:/app microbit_ei_build”). I am not sure what it’s going on exactly. I was wondering if you can make a video about this or if you can help me out! I will attach the error that I have below!
By the way, I am doing this in Windows 10, VSC (so I can run python build.py)
@toolelucidator Can you open a serial terminal and see what the board says? Or you can use edge-impulse-run-impulse --raw if you have the Edge Impulse CLI installed.