Thank you, indeed, I was thinking to go with the “hey jack” and afterwards “turn on / at 2” “… at 3 etc…” Would that be ok to train the model?
What do you think if I would juggle the recoded voices around? Eg. if I took the “hey jack” from one person and “turn on” from the other, while I take the number from the third, and so on? That would mix the complexity even further… which would test the model even harder, would not ?
Indeed, I am using the “dumb” var such kids voices including words that does not mean anything to the commands, like noise and clutter…
@mu234 There’s no absolute truth, but in general adding more variance to your training set will harden the model more. Especially with small models it might be very set on just specific voices, so varying early on is a good idea to validate.
I have prepared the audio, including a bunch of cluttering… different gibberish chat, where along are also the key words, but said separately, not in a context of so called key words…, I have even recorded my kids saying some words… anyway, I am not really sure, if I understand the whole learning concept.
For example, now I have
woman say “hay jack”
man say “hay jack”
man “turn on at 1… 10”
woman “turn on at 1… 10”
man “off”
woman “off”
Indeed, there is more of woman recordings than man However, I have add two kids, this is marginal… only two and their level of saying the words is way to poor to be used as voice, but rather noise, however, I have used it as voice
As you can seen I have recorded woman and man separately, but I guess I should have them under one label, right? For example, “hey jack” said by woman or man should be under the same label in data acquisition, that should follow also for the rest of the words, like turn on 1…10 , off?
Looking forward to start dealing with impulses, etc.
Cheers Jan, went trough a 1d phase of convolutional training and got accuracy of 96% and more, etc. However, when I want to make a Live classification I got an error that my sample rate is inaccurate, indeed, the training audio is on 44.1kHz while the sampling rate of live “recording” wants to be at 16kHz!
I guess one way would be to resample of the training/testing audio, but that would be time consuming, therefore, is there another way or should the data be downloaded, resampled and uploaded again?
PS. is there a function within the audio processing block to do this?
Hi @mu234, we currently only have downsampling in our enterprise version - not in the free projects for now. But if you’re using your phone you can test at 44KHz:
You’ll probably want downsample with e.g. sox and retrain at 16KHz, e.g. by:
Export your raw data (Dashboard > Export, and selecting WAV files).
Convert everything:
cd whereeveryouexporteddata
mkdir -p 16khz/training
find training -maxdepth 1 -type f -exec sox {} -r 16000 16khz/{} \;
mkdir -p 16khz/testing
find testing -maxdepth 1 -type f -exec sox {} -r 16000 16khz/{} \;
Cheers Jan! This is exactly what I have done, SOX is really a good and simple way of doing this …
Now I have moved on, and have done the NN stage too, I can download the bin to the board via the command line, namely with the edge-impulse-flash… and it works, however, I would like to move on…
Therefore, I am wondering how to bring that C code to the Segger IDE, any ideas?
I guess there are instructions that could be followed? In addition, I guess this should be done with the “edge-impulse-standalone.emProject” and e.g. the Segger IDE, but somehow I cannot compile the “edge-impulse-standalone.emProject” got an error, see below:
Building 'edge-impulse-standalone' from solution 'edge-impulse-standalone' in configuration 'Debug'
1> build/bin/FreeRTOS_CLI.o does not exist.
1> Compiling 'FreeRTOS_CLI.c'
1> /opt/gcc-arm-none-eabi-8-2018-q4-major/bin/arm-none-eabi-gcc -c -mthumb -fno-exceptions -Wno-unused-variable -nostartfiles -Wno-unused-parameter -Wno-parentheses -Wno-unused-function -ggdb -fno-common -fmessage-length=0 -std=gnu99 -DSRAM -DPROJ_NAME=edge-impulse-standalone -DECM3532 -I../../Thirdparty/edge_impulse -I../../Thirdparty/edge_impulse/edge-impulse-sdk/CMSIS/DSP/Include -I../../Thirdparty/edge_impulse/edge-impulse-sdk/CMSIS/Core/Include -I../../Platform/ECM3532/M3/hw/hal/common/include -I../../Platform/ECM3532/Common/framework/inc -I../../eta_ai_bsp/inc -Isrc -I../../Platform/ECM3532/M3/framework/executor/include/pub -I../../Platform/ECM3532/M3/NN_kernels/include -I. -I../../Platform/ECM3532/M3 -I../../Platform/ECM3532/M3/util/include -I../../Platform/ECM3532/M3/hw/include -I../../Platform/ECM3532/M3/hw/include/ecm3532 -I../../Platform/ECM3532/M3/hw/board/ecm3532/ai_vision/include -I../../Platform/ECM3532/M3/util/console/include -I../../Platform/ECM3532/M3/util/dsp_helper/include -Iinclude -I../../Platform/ECM3532/M3/hw/csp/ecm3532/common/csp/inc -I../../Platform/ECM3532/M3/hw/csp/ecm3532/m3/reg/inc -I../../Platform/ECM3532/M3/hw/csp/common/inc -I../../Platform/ECM3532/M3/hw/csp/ecm3532/m3/csp/inc -I../../Thirdparty/FreeRTOS/Source/include -I../../Thirdparty/FreeRTOS/Source/portable/GCC/ARM_CM3 -I../../Thirdparty/FreeRTOS-Plus/Source/FreeRTOS-Plus-CLI -I../../Platform/ECM3532/M3/hw/hal/common/include -I../../Platform/ECM3532/M3/hw/hal/ecm3532/include -I../../Platform/ECM3532/M3/hw/drivers/spi_flash/common -I../../Platform/ECM3532/M3/hw/drivers/spi_flash/maxim -I../../Platform/ECM3532/M3/framework/rpc/src -I../../Platform/ECM3532/M3/framework/rpc/include -I../../Platform/ECM3532/Common/framework/inc -I../../Platform/ECM3532/M3/hw/ipc/common/include ../../Thirdparty/FreeRTOS-Plus/Source/FreeRTOS-Plus-CLI/FreeRTOS_CLI.c -MD -MF build/bin/FreeRTOS_CLI.d -fno-diagnostics-show-caret -o build/bin/FreeRTOS_CLI.o -O3 -g -ffunction-sections -fdata-sections -Wall -mcpu=cortex-m3 -mfpu=vfp -mfloat-abi=soft -mlittle-endian
2> build/bin/croutine.o does not exist.
2> Compiling 'croutine.c'
2> /opt/gcc-arm-none-eabi-8-2018-q4-major/bin/arm-none-eabi-gcc -c -mthumb -fno-exceptions -Wno-unused-variable -nostartfiles -Wno-unused-parameter -Wno-parentheses -Wno-unused-function -ggdb -fno-common -fmessage-length=0 -std=gnu99 -DSRAM -DPROJ_NAME=edge-impulse-standalone -DECM3532 -I../../Thirdparty/edge_impulse -I../../Thirdparty/edge_impulse/edge-impulse-sdk/CMSIS/DSP/Include -I../../Thirdparty/edge_impulse/edge-impulse-sdk/CMSIS/Core/Include -I../../Platform/ECM3532/M3/hw/hal/common/include -I../../Platform/ECM3532/Common/framework/inc -I../../eta_ai_bsp/inc -Isrc -I../../Platform/ECM3532/M3/framework/executor/include/pub -I../../Platform/ECM3532/M3/NN_kernels/include -I. -I../../Platform/ECM3532/M3 -I../../Platform/ECM3532/M3/util/include -I../../Platform/ECM3532/M3/hw/include -I../../Platform/ECM3532/M3/hw/include/ecm3532 -I../../Platform/ECM3532/M3/hw/board/ecm3532/ai_vision/include -I../../Platform/ECM3532/M3/util/console/include -I../../Platform/ECM3532/M3/util/dsp_helper/include -Iinclude -I../../Platform/ECM3532/M3/hw/csp/ecm3532/common/csp/inc -I../../Platform/ECM3532/M3/hw/csp/ecm3532/m3/reg/inc -I../../Platform/ECM3532/M3/hw/csp/comlibrarymon/inc -I../../Platform/ECM3532/M3/hw/csp/ecm3532/m3/csp/inc -I../../Thirdparty/FreeRTOS/Source/include -I../../Thirdparty/FreeRTOS/Source/portable/GCC/ARM_CM3 -I../../Thirdparty/FreeRTOS-Plus/Source/FreeRTOS-Plus-CLI -I../../Platform/ECM3532/M3/hw/hal/common/include -I../../Platform/ECM3532/M3/hw/hal/ecm3532/include -I../../Platform/ECM3532/M3/hw/drivers/spi_flash/common -I../../Platform/ECM3532/M3/hw/drivers/spi_flash/maxim -I../../Platform/ECM3532/M3/framework/rpc/src -I../../Platform/ECM3532/M3/framework/rpc/include -I../../Platform/ECM3532/Common/framework/inc -I../../Platform/ECM3532/M3/hw/ipc/common/include ../../Thirdparty/FreeRTOS/Source/croutine.c -MD -MF build/bin/croutine.d -fno-diagnostics-show-caret -o build/bin/croutine.o -O3 -g -ffunction-sections -fdata-sections -Wall -mcpu=cortex-m3 -mfpu=vfp -mfloat-abi=soft -mlittle-endian
3> build/bin/list.o does not exist.
2> In file included from ../../Thirdparty/FreeRTOS/Source/include/FreeRTOS.h:56,
2> from ../../Thirdparty/FreeRTOS/Source/croutine.c:28:
2> ../../Thirdparty/FreeRTOS/Source/include/FreeRTOSConfig.h:30:10: fatal error: config.h: No such file or directory
2> compilation terminated.
3> Compiling 'list.c'
3> /opt/gcc-arm-none-eabi-8-2018-q4-major/bin/arm-none-eabi-gcc -c -mthumb -fno-exceptions -Wno-unused-variable -nostartfiles -Wno-unused-parameter -Wno-parentheses -Wno-unused-function -ggdb -fno-common -fmessage-length=0 -std=gnu99 -DSRAM -DPROJ_NAME=edge-impulse-standalone -DECM3532 -I../../Thirdparty/edge_impulse -I../../Thirdparty/edge_impulse/edge-impulse-sdk/CMSIS/DSP/Include -I../../Thirdparty/edge_impulse/edge-impulse-sdk/CMSIS/Core/Include -I../../Platform/ECM3532/M3/hw/hal/common/include -I../../Platform/ECM3532/Common/framework/inc -I../../eta_ai_bsp/inc -Isrc -I../../Platform/ECM3532/M3/framework/executor/include/pub -I../../Platform/ECM3532/M3/NN_kernels/include -I. -I../../Platform/ECM3532/M3 -I../../Platform/ECM3532/M3/util/include -I../../Platform/ECM3532/M3/hw/include -I../../Platform/ECM3532/M3/hw/include/ecm3532 -I../../Platform/ECM3532/M3/hw/board/ecm3532/ai_vision/include -I../../Platform/ECM3532/M3/util/console/include -I../../Platform/ECM3532/M3/util/dsp_helper/include -Iinclude -I../../Platform/ECM3532/M3/hw/csp/ecm3532/common/csp/inc -I../../Platform/ECM3532/M3/hw/csp/ecm3532/m3/reg/inc -I../../Platform/ECM3532/M3/hw/csp/common/inc -I../../Platform/ECM3532/M3/hw/csp/ecm3532/m3/csp/inc -I../../Thirdparty/FreeRTOS/Source/include -I../../Thirdparty/FreeRTOS/Source/portable/GCC/ARM_CM3 -I../../Thirdparty/FreeRTOS-Plus/Source/FreeRTOS-Plus-CLI -I../../Platform/ECM3532/M3/hw/hal/common/include -I../../Platform/ECM3532/M3/hw/hal/ecm3532/include -I../../Platform/ECM3532/M3/hw/drivers/spi_flash/common -I../../Platform/ECM3532/M3/hw/drivers/spi_flash/maxim -I../../Platform/ECM3532/M3/framework/rpc/src -I../../Platform/ECM3532/M3/framework/rpc/include -I../../Platform/ECM3532/Common/framework/inc -I../../Platform/ECM3532/M3/hw/ipc/common/include ../../Thirdparty/FreeRTOS/Source/list.c -MD -MF build/bin/list.d -fno-diagnostics-show-caret -o build/bin/list.o -O3 -g -ffunction-sections -fdata-sections -Wall -mcpu=cortex-m3 -mfpu=vfp -mfloat-abi=soft -mlittle-endian
1> In file included from ../../Thirdparty/FreeRTOS/Source/include/FreeRTOS.h:56,
1> from ../../Thirdparty/FreeRTOS-Plus/Source/FreeRTOS-Plus-CLI/FreeRTOS_CLI.c:33:
1> ../../Thirdparty/FreeRTOS/Source/include/FreeRTOSConfig.h:30:10: fatal error: config.h: No such file or directory
1> compilation terminated.
3> In file included from ../../Thirdparty/FreeRTOS/Source/include/FreeRTOS.h:56,
3> from ../../Thirdparty/FreeRTOS/Source/list.c:30:
3> ../../Thirdparty/FreeRTOS/Source/include/FreeRTOSConfig.h:30:10: fatal error: config.h: No such file or directory
3> compilation terminated.
Build failed
Any ideas how to fix this, if I could actually make use of it? I just want to use the C code from the edge impulse and turn on/off the LEDs on my dev board… I am on linux and working with the eta… sensor board.
Any help is much appreciated!
BR.
PS: sorry for posting this here, probably it should have a different title, I am sure the forum admin will organise it properly…
Note that https://github.com/edgeimpulse/firmware-eta-compute-ecm3532 also has drivers for the audio and examples present already - might be easier to get started on that (you can replace the model by replacing the model-parameters / tflite-model folders).
@janjongboom Hello, I have created the topic about the problem I am encountering when trying to compile, build the Edge Impulse SDK and ETA Compute SDK …
more here: Missing include path
If you by any change have an idea how to go around this that would be wonderful!
@janjongboom After several compilations and help from ETA compute I have finally compiled via the cmake/make deploy-able C++ and it works ok, now I would like to improve my NN. On the one hand it takes some time, approx. 1500 - 2000 to react on the command, on the other hand the recognition of a simple voice of 757ms is rather vague, although I have approx. 80% accuracy… Any ideas how to fix this two issues?
The inference runs on the ECM3532 Cortex-M3 which doesn’t have any DSP instructions. You could try reducing the FFT size of your DSP block to decrease the latency.
How many minutes of audio do you have in your project? Also feel free to share your project ID and we can have a look.
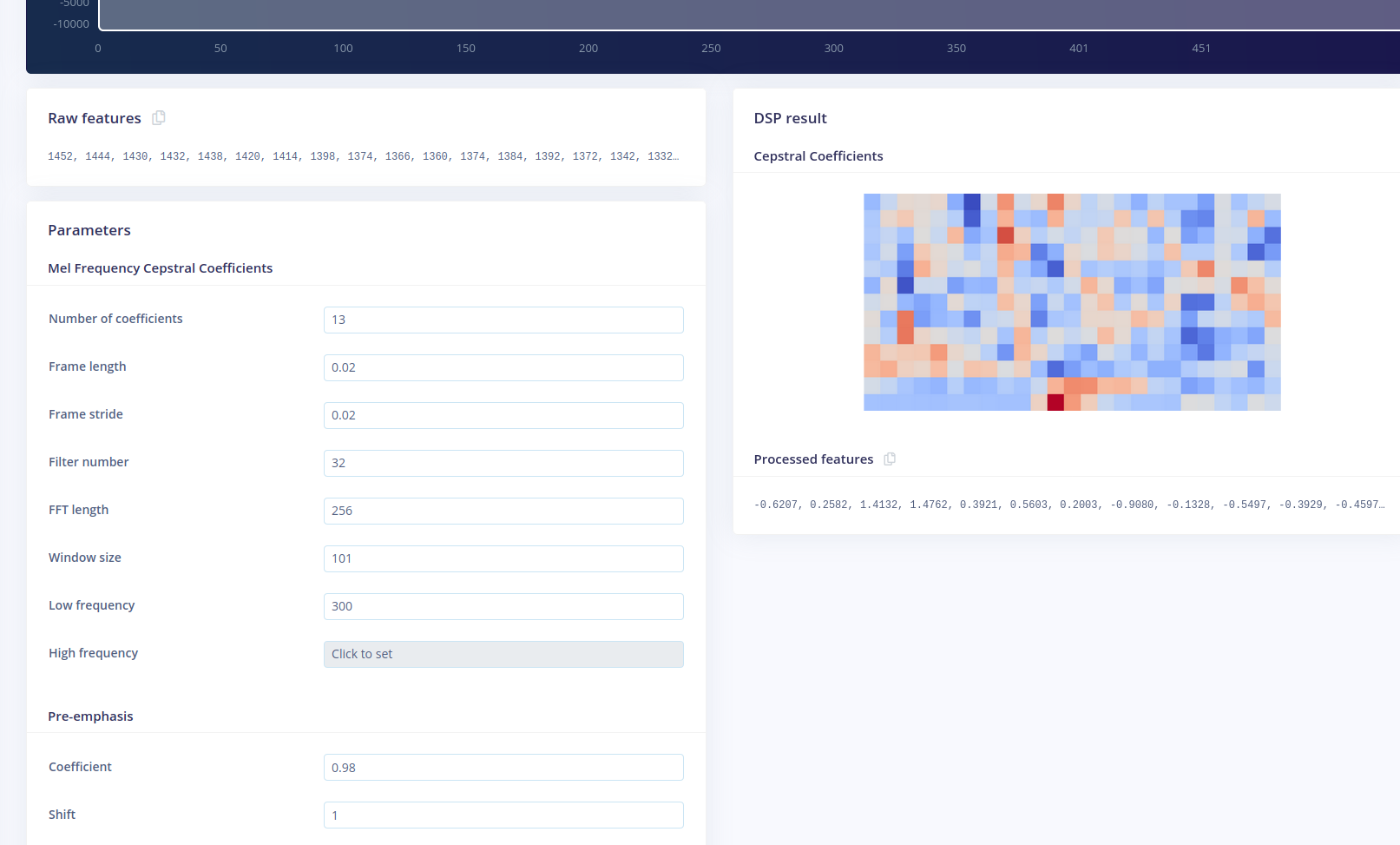
Thank you for your reply, and I was hoping to leverage the DSP (how to enable the DSP ? In genral, looking for the fast and smooth operation…) on eta’s chip, when you say FFT size I am not really sure about which parameter you are referring to, hence I am attaching the picture of the DSP and FFT setup, hope we are talking about the same thing?
(Simple) Project ID 29827
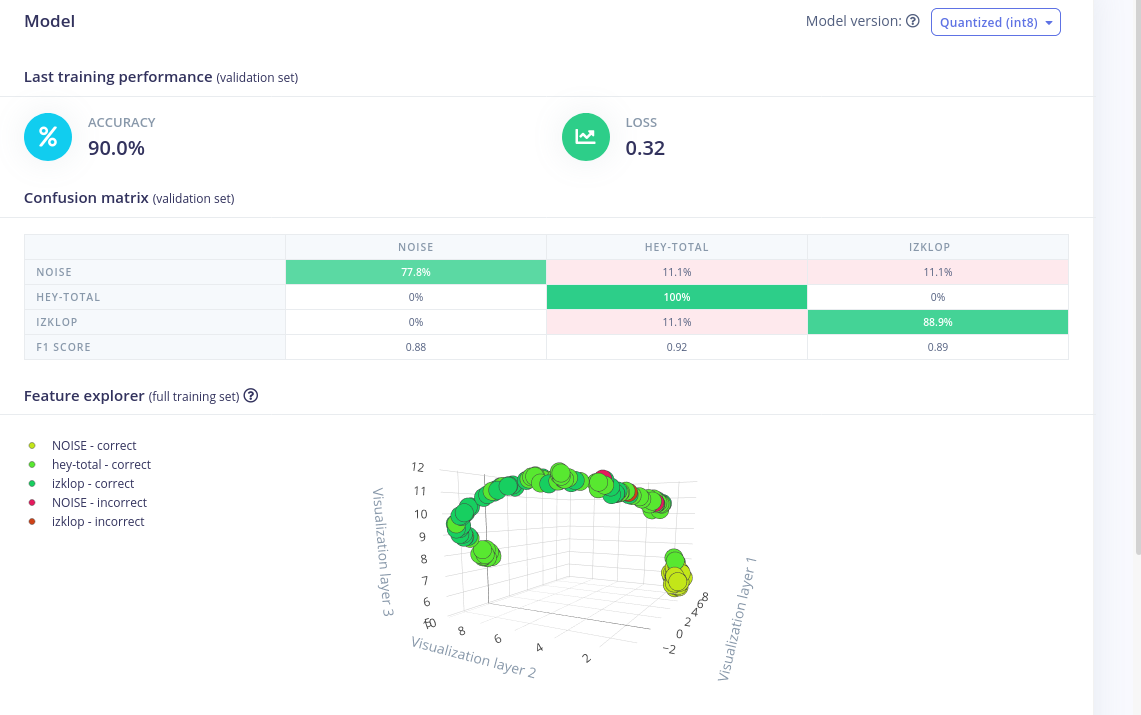
rather very good accuracy “on paper” latest trainings show above 90%
model testing : 75%
data collected : 1m11s (one type of noise and 1 key word recognition)
attaching pic. of MFC
(Complicated) Project ID 28364
less good accuracy, not yet have tested the response in real time, around 59%
model testing : almost 20%
data collected : 3m35s (two types of noise and 5 keywords recognition)
Indeed, please let me know how can I share you the project? Not an enterprise user…
You’ll need to collect more data, especially when you increase the number of classes.
With the 7 classes model, it’d be good to get at least 10 min for each class. Also one thing I noticed in your project is you have different words in a single sample but your window size is shorter than the entire phrase. Ideally you should have the entire phrase within the window (ie: “Hey Jack”) - 2 sec window should be fine.
In the DSP block, you can reduce the FFT length to 128 to improve latency. For now we cannot enable the DSP on the ETA chip as some signal processing instructions are missing.
working on adding more audio, kind of a slow process …
Some of the audio is not long “enough” , for example, hey total has at places also more than a second, while vklop@1 is somewhere even less than a second, how to treat the window of the impulse in this case?
I would select the window size that fits all your samples, so a bit more than a second.
For samples that have less, you can also apply the “pad data with zeros” option on the impulse design so all generated windows will have the same size.
I am slowly building up the audio corpus… meanwhile I am trying the best with what I have, created a new “simple” version, please have a look at the ID 33093, something is strange, at least to me
One the one hand, one word is 100% correct, while on the other hand it is also, the same word, 100% incorrect.…
Any ideas what could be wrong, except the lack of audio data ? Otherwise the model accuracy is 100% hmm…
BR.
Could you point me out to the samples you are referring to?
The dataset is still fairly small so the neural network will overfit quickly to your training data (100% accuracy is usually a sign).
To avoid overfitting and improve test accuracy, you can do:
add more data (try to get 5 min at least by class)
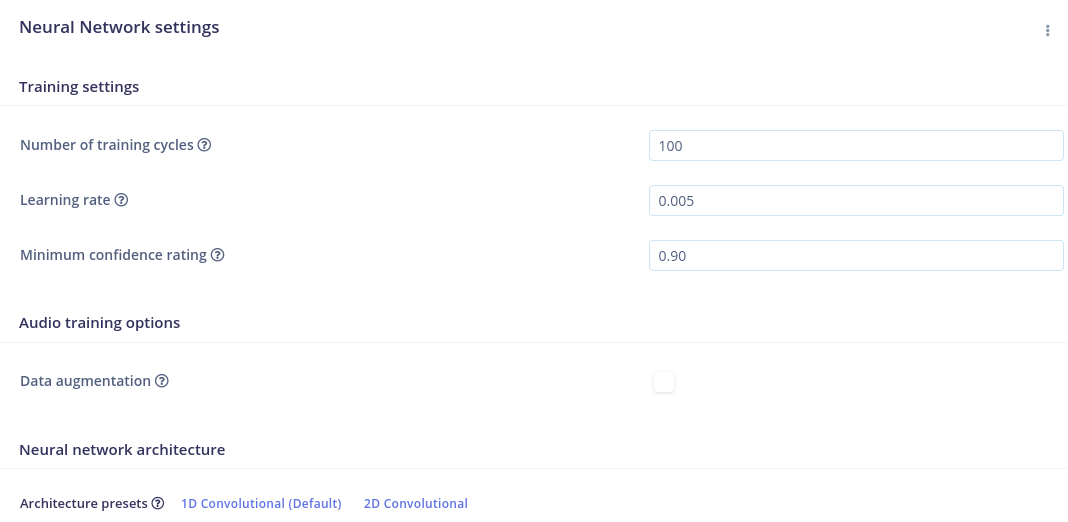
use audio augmentation in the neural network parameters
Also the NN seems to converge quickly so you can reduce the number of epochs to a smaller value like 50 or 100.
I have sorted out the 100% correct/incorrect problem… recent results attached picture, I am not really sure what do you mean by the “audio augmentation”, found “data augmentation”
have a look