Excellent analysis! Let me pass this on to the embedded team and see if they can take your observations into account to help get some improvements on those estimations for this target.
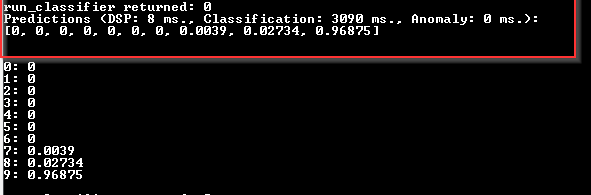
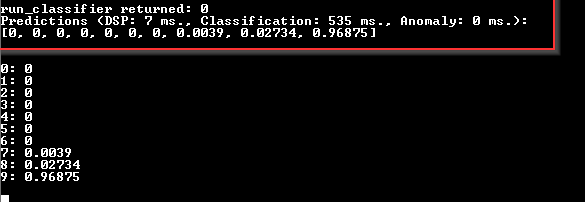
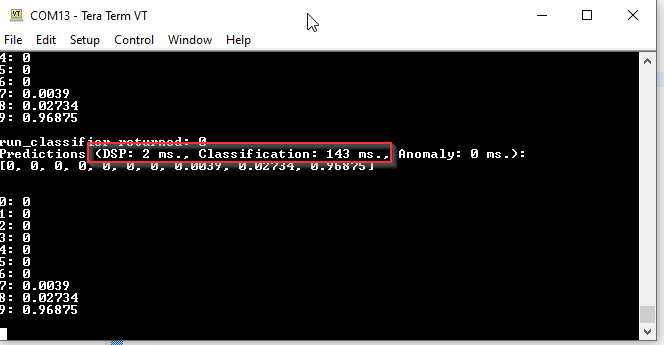
Simulation Accuracy vs hardware in the loop: The simulation might not accurately reflect the real-world conditions of the hardware. We offer hardware in the loop testing for other vendor targets to cross validate against but not this one yet so the estimations may well be different but again model complexity is something that can be at play here too. Not long ago this type of operation was not able to run on anything below SBCs.
Model Complexity: The MNIST model might be too complex for the hardware, leading to longer inference times. This could be a result of the model architecture, the size of the model, or the efficiency of the model’s operations. Again we can only give estimations based on simulated architecture for this device that dont factor in unanticipated hardware specific bottlenecks.
Debug vs Release Mode: Running in debug mode often adds additional overhead due to logging, monitoring, and other debug-related tasks. Further more we have additional latency to consider if you are using via cli.
There are other conversations on this topic in the forum too, please feel free to pick up on one of those that the embedded folks have been discussing on too.
Can you please share the Project ID, and the IDE version that you are using / compiler, OS and any other details you have. So we can reproduce your environment. Thanks!
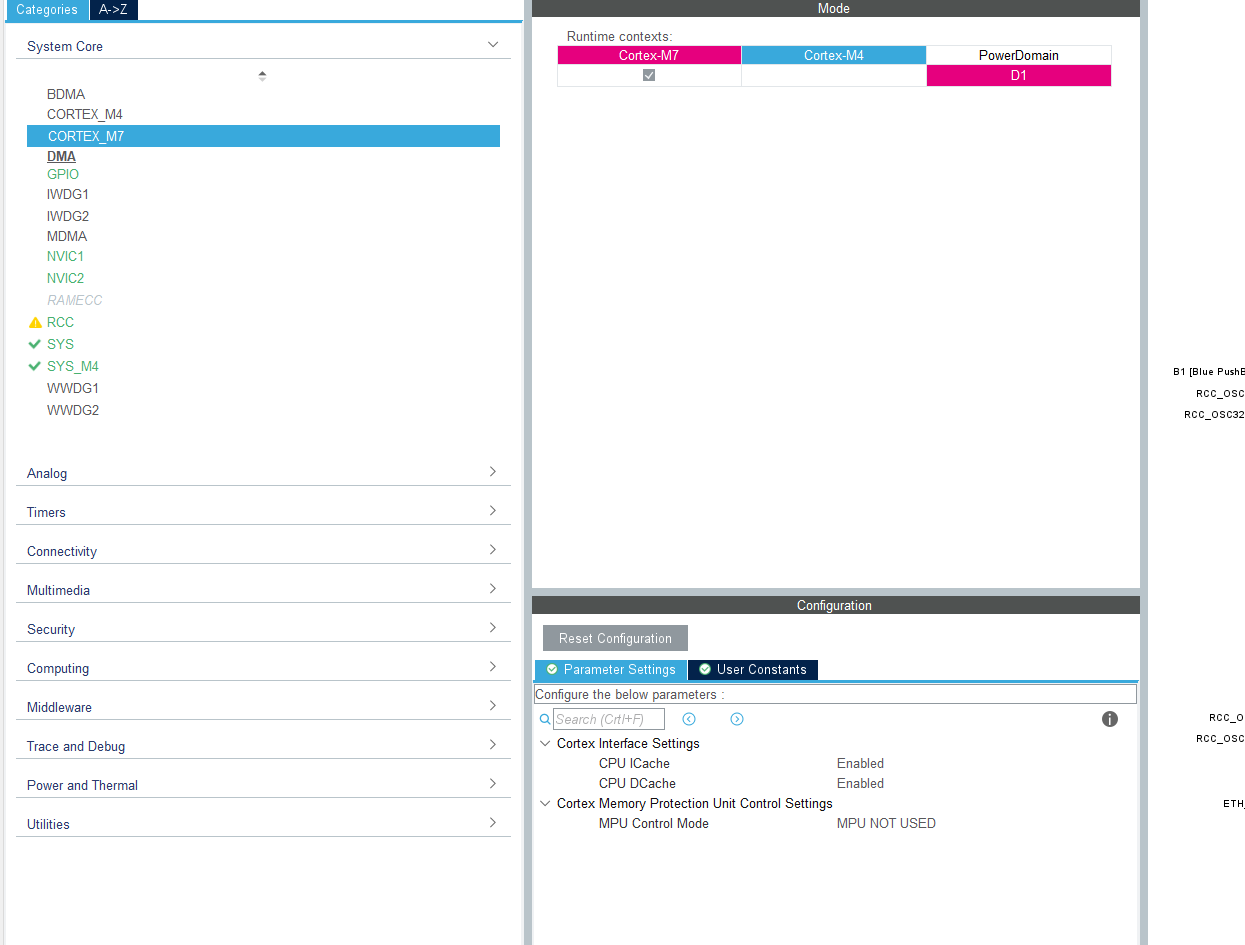
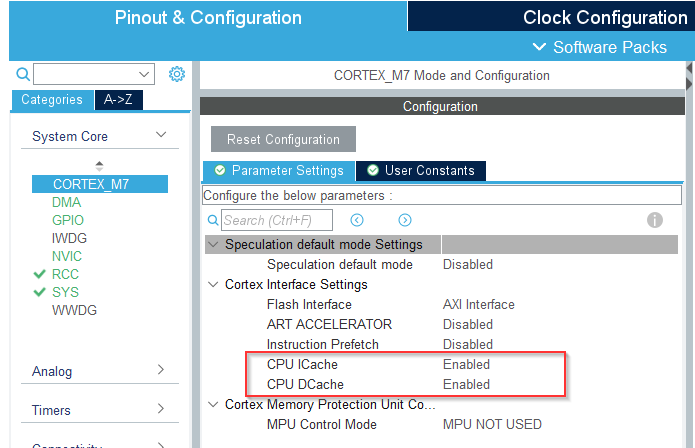
OK great so i-cache d-cache sounds like hardware specific, let me check with embedded, and capture in the issue. Hopefully this is something we can set by default @AlexE@mateusz FYI
We will post here once we get time with holidays and ongoing tasks in motion. Thanks again for all of this analysis super valuable to have this insight from embedded developers! Feel free to keep this thread open for now.
These settings are disabled by default, so users need to enable them to get better results.
This allows the CPU to work more efficiently with MCU memory.