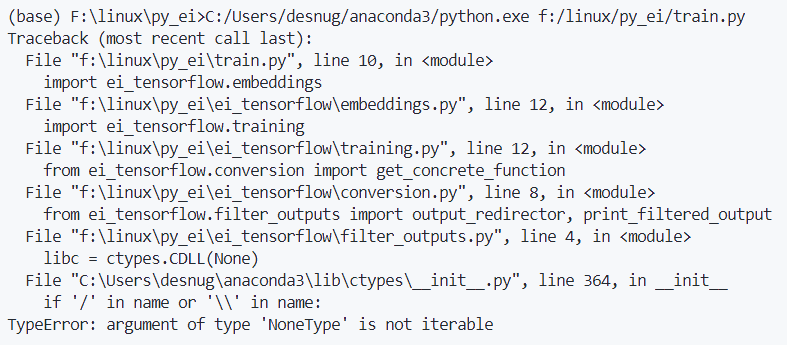
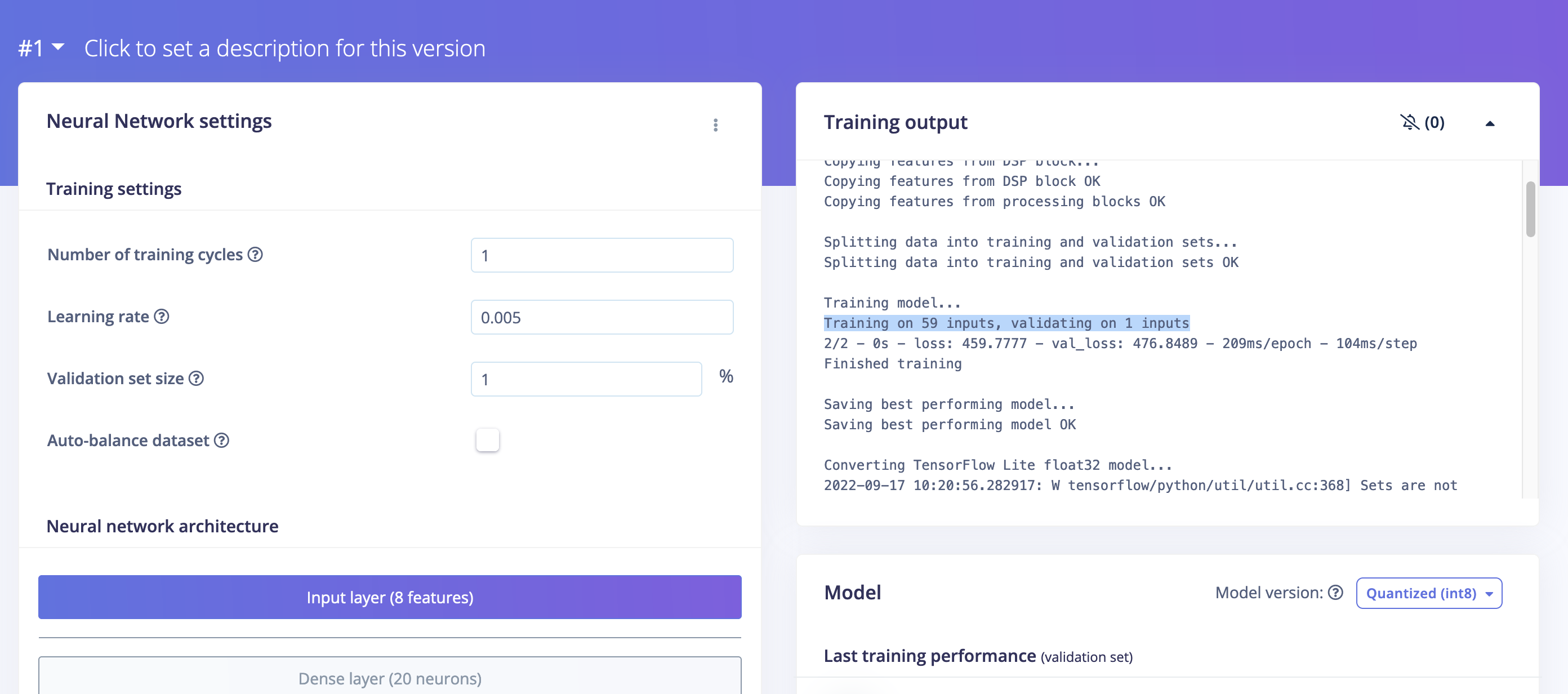
@janjongboom I look forward to this new release. This release will solve my question: Weights & Biases (wandb).
- A question about the data pipeline.
Data is randomly allocated to the training and the validation set. Suppose I understand (ref: Choosing your own validation data]) correct, we can not have complete control over which data is allocated to the training set and which data is allocated to the validation set. For example, in the case of medical applications, if you have different patients, data from the same patient can be assigned to the training set and the validation set. This data split results in data leakage. Correct me if I am wrong. Given the upcoming release, do we have control of the training and validation dataset split inside the studio?
A question about the training pipeline.
I am correct that today a regression in EI studio is solved as a classification problem.
# model architecture
model = Sequential()
model.add(Dense(20, activation='relu'))
model.add(Dense(10, activation='relu'))
model.add(Dense(classes, name='y_pred'))
Will there be a release where you regress directly to the single value?
model = Sequential()
model.add(Dense(20, activation='relu'))
model.add(Dense(10, activation='relu'))
model.add(Dense(1, name='y_pred'))
As an experiment, I have changed in the studio:
model.add(Dense(classes, name='y_pred'))
to
model.add(Dense(1, name='y_pred'))
So far, I see similar results. However, I am not confident if this will be in all cases. Also, because of the following:
Y = tf.keras.utils.to_categorical(Y - 1, classes)
In the new release, do we have more control?
A question (maybe) off-topic. Can we, for example, use TensorFlow Probability inside the EI studio? I am still exploring this topic Regression - Confidence Interval, but, I think, it could be an added value to have some idea about model uncertainty. What is your opinion?
Extra question.
Will the presentations of The biggest embedded ML event of the year. become online for those who can not attend this event?
Regards,
Joeri