I am still researching this topic, but a couple of questions:
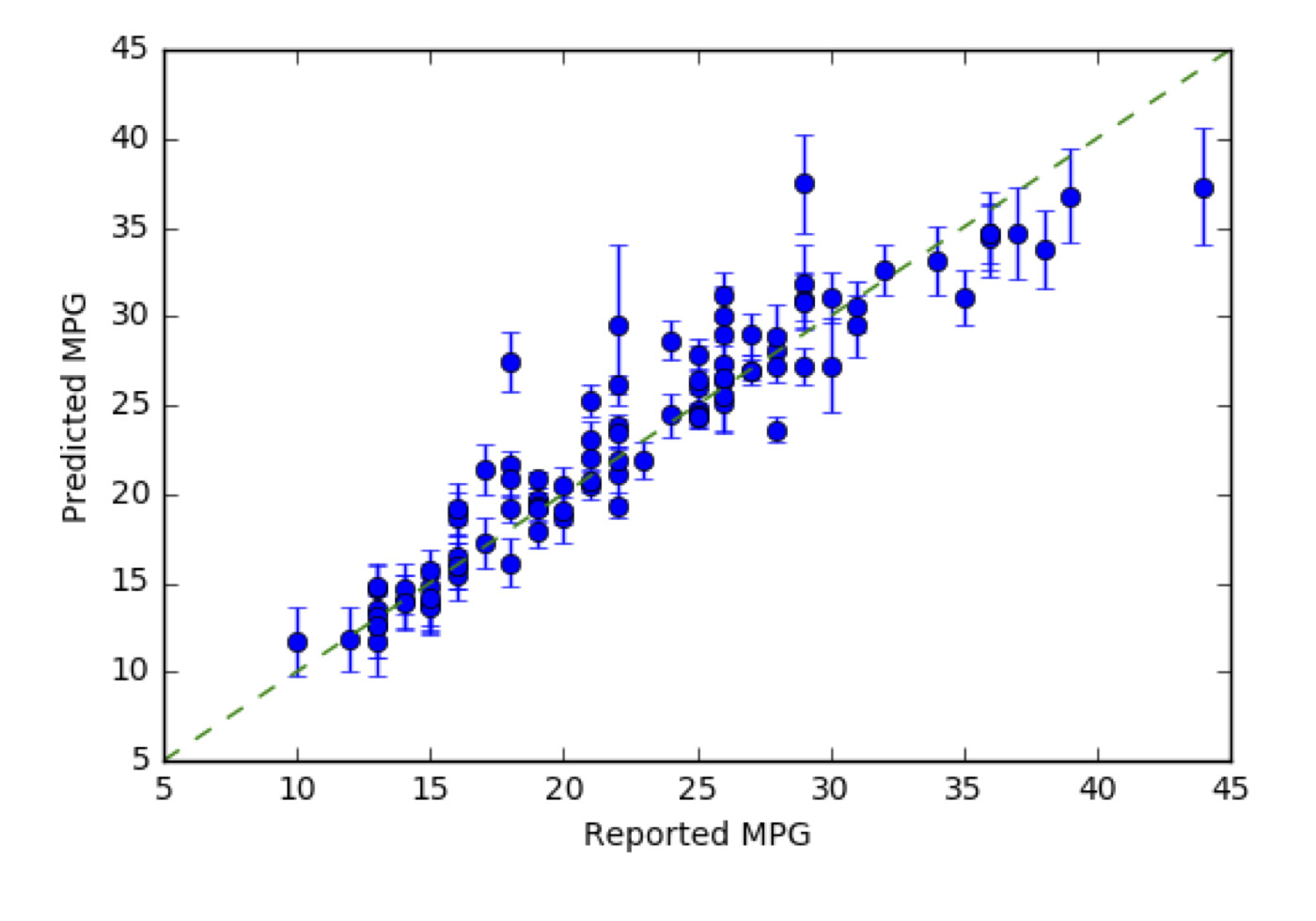
If we retrain the same model for example 10 times and test these models 10 times on the same test dataset, can it already give a “good” first approximation, a measure of uncertainty of the prediction (obtain an idea about the epistemic uncertainty)?
Do we need to go to a Bayesian approach, Bayesian Neural Networks? Use tools such as TensorFlow Probability?
I know there is some literature out there but maybe there are people on this forum who have practical experience, suggestions are welcome.
I am having a similar issue/question regarding the error for regression.
My project works with 4 sensor signals and attempts to output a heart rate value.
When classifying the data on a trained model, changing the confidence threshold (maximum error percentage) to a number as small as 1e-10 still changes nothing.
For example it will say that any expected - result > 50 is incorrect, but make everything else correct. This range is a little extreme when dealing with heart rate (BPM), and it should call anything >5 bpm incorrect.
Maybe I am not correctly understanding how the error is predicted/obtained. If anyone can point me into the right resources as well it would be much appreciated!
@jsindorf in your case, your goal is to obtain an error = difference between the prediction and the true value is < 5. Correct?
My goal is to get a confidence interval for the prediction. To give an example, in your regression problem, you make a prediction for the heart rate. Given some input features the neural network predicts that the heart rate is 65bpm (+/- ? bmp). I like to have an idea about the +/-? bpm.
For a deep learning model, the approach you mention—retraining the same model multiple times from different initial states, and looking at the range of results—is a reasonable one. Here’s a good tutorial that talks about how to do this:
It would be interesting to add this to Edge Impulse—I’ll log it as a feature request. For now, you could try exporting your regression block to a Jupyter notebook and following the linked guide to create some error bars.
Thanks for reaching out! The maximum error percentage determines how much error is acceptable as a fraction of the target value. For example, if the maximum error percentage is set to 0.1, the prediction may be within 10% of the target value and be considered correct.
The smaller you set this number, the less error will be tolerated. If a heart rate in your dataset is an average of 70bpm, to get a tolerance of ~5bpm you’d need to specify a maximum error percentage of 0.07, since 7% of 70bpm is 4.9.
The naming and units in this part of the UI are a certainly bit confusing—we’ll take some time to improve them!
@dansitu I have some doubt about where you can set the confidence interval. Currently, it is in the Model Testing window tab. Is it not better to check this on the validation set?
If you are not careful you will indirectly use the information from the test set (leakage information from test set to training set) to improve your model. What can happen is that you set the confidence interval and if you are not happy you tune the model parameters and retrain the model until you reach the confidence threshold target, which is calculated based on the test set. A better approach is to do this on the validation set. I don’t think this is today possible on the EI platform.
Finally, you will check on the test set (model generalisation).
Currently, I am following a different approach. I perform some hyperparameter tuning (on a local machine) and track the experiments using wandb. At the end of the experiments I download all the metrics (MSE, model size float & model size int, …) and perform some extra analysis. If I am happy with the model I retrain the model (for example 10-times), as explained in the link you have provided. Also this info is tracked by wandb (in another sweep) so I can analyze this. Final, I select one of the models (I also track the tf models in wandb) that I retrain in the EI platform, check the memory and latency (EON Combiler on). I know you can add a custom learning block, but I have not yet implemented it.
If you have ideas about improving this workflow, all information is welcome.
I see that makes sense! I am still getting a really high accuracy, however, even with an error percentage as low as 1e-15. The dataset has a 50-150 BPM range, and I have tested this with an even and uneven data distribution across the label range. Both times even with a low percentage I still receive correct guesses for predictions that are as far as 40 BPM from the actual. What would the average HR value be based on in this instance? It would seem regardless of the error value I set, only predictions > 50 are being flagged as incorrect.
Thank you for the help,
Jacob
You make a great point that it’s important to avoid having your test data contribute to your iterative model development process. Instead, it’s best to use it as a final check to make sure your model is not overfit to the validation dataset.
We’re actually working on a ton of improvements in this space, including our Performance Calibration feature which will automatically tune a post-processing algorithm for you. We’ll also be announcing some very relevant workflow-related stuff at Imagine, so stay tuned!
Hello,
The one with an uneven data distribution can be found here: 118195
The one with a more even distribution of data labels can be found here: 120514
Hello,
I was wondering if there has been any updates to this issue?
I am still receiving incorrect accuracy when testing.
The regression value range is 48-149, and even with a confidence threshold of 1*10^-10, it still has a 99+% accuracy. The only incorrect values are when the output is a difference greater than 50.
Hello,
I noticed the change in model testing, and the accuracy works very well!
However, I think a similar problem occurs during regression under the model’s data explorer graphic. From the trends I have seen, it seems to label all estimations under the threshold as correct as well as any within the set error range (ex:true: 143, est: 73, and true: 65 est: 64.5 are both considered correct). I think only estimations over are correctly evaluated.