Question/Issue:
Is there something I’m missing about quantization option for BYOM?
Project ID:
721531
Context/Use case:
Applying quantization to BYOM
Summary:
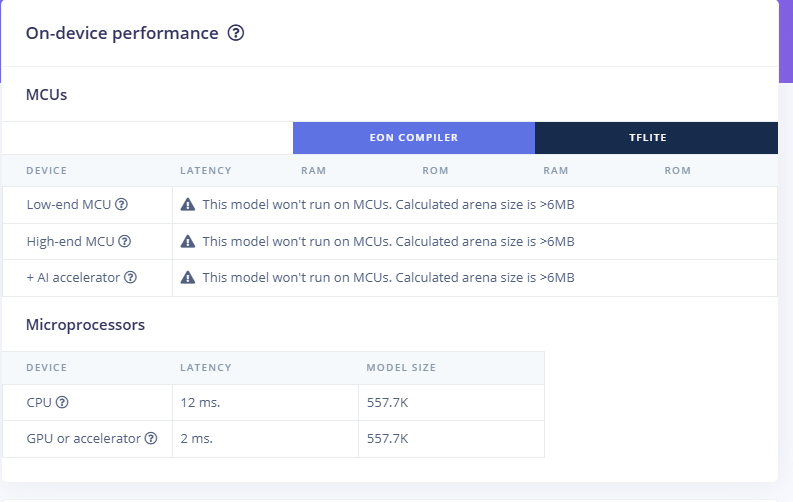
I’ve successfully loaded my model (BYOM) in .tflite format and generated the C++ library for use on my MCU. I’ve also confirmed that inference is working by evaluating the results.
Now I’ve tried to use quantization. I’ve loaded ONNX model and provided representative dataset, but I am getting this warnings/errors:
There can be limitations on quantisation support when using BYOM, as we can only quantise when the ops and activation functions are in Tflite, can you share the ONNX model architecture as a screenshot or do you mind if I pull it from your project to check it out?
You wont see Quantization if:
Your model type isn’t supported by int8 or full-integer quantization (some custom layers aren’t quantizable).
Input data type or preprocessing block prevents quantization.
Ah right ok but then we should see what ops are failing from the logs for quantzation.
Having trouble accessing your project at the moment via our admin panel, but you should be able to see what operations are failing to quantize in the logs. I’ll try again later to access your project and share with our ML team.