Question/Issue:
I’m using Edge Impulse’s Python SDK to make a design-space exploration of my TF-Lite 8-bit quantized model on multiple hardware devices: [‘raspberry-pi-rp2040’, ‘cortex-m4f-80mhz’, ‘cortex-m7-216mhz’, ‘st-stm32n6’, ‘raspberry-pi-4’, 'jetson-nano’].
My model is a trivial 4-layer multi-layer perceptron model trained in Keras.
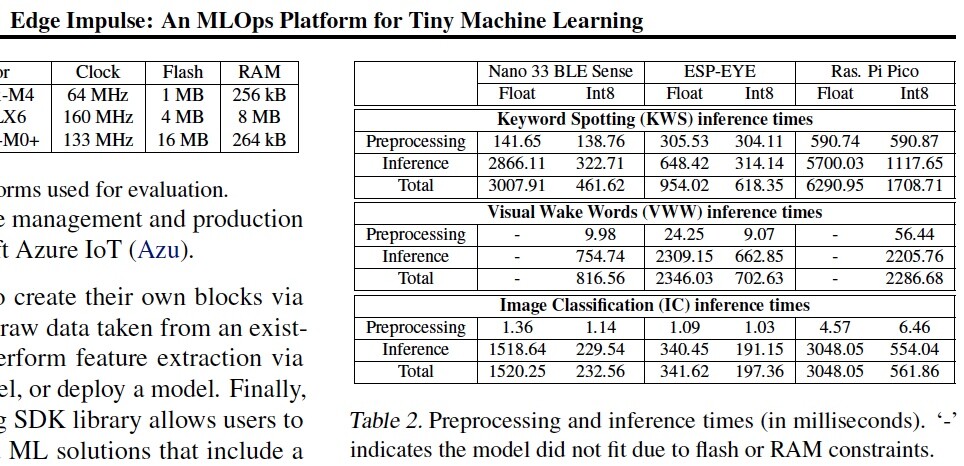
My goal is to make a table similar to Table 2 reported in [1] (see the attached pic).
Every time I run a profiling using
profile = ei.model.profile(model=model_to_profile, device=device_type)
I get similar but different timePerInferenceMs results.
I read that Edge Impulse is using Renode and device-specific benchmarking for inference time estimations [1].
My questions are:
- Is Edge Impulse profiler ALWAYS using Renode for inference time estimations?
- Is it normal that timePerInferenceMs is never the same value beteween consecutive profiling runs?
- Does it make sense to average the timePerInferenceMs results over multipler profiling runs (e.g., 10 runs) to get rid of these differences?
- If I’m setting “cortex-m7-216mhz” as “device” in ei.model.profile(), is it normal that I get, let’s say, 100ms, while under ‘highEndMcu’ (“description": "Estimate for a Cortex-M7 or other high-end MCU/DSP, running at 240MHz”) I get 446ms? They are the same processor with similar clock frequencies. Basically my question is: are the results under “Target results for int8:” coparable with those under “Performance on device types”?
Environment:
conda with:
edgeimpulse 1.0.18 pypi_0 pypi
edgeimpulse-api 1.71.58 pypi_0 pypi
python 3.12.9 h5148396_0
- OS Version: Ubuntu 24.04.2 LTS
Logs/Attachments:
- I attach Table 2 reported in [1].
- I attach two profile.summary() outputs of two consecutive profile runs using the same target processor "cortex-m7-216mhz”.
[1] S. Hymel et al., “Edge Impulse: An MLOps Platform for Tiny Machine Learning,” Apr. 28, 2023, arXiv: arXiv:2212.03332. doi: 10.48550/arXiv.2212.03332.
profiling_cortex-m7-216mhz_int8_run1
Target results for int8:
========================
{
"variant": "int8",
"device": "cortex-m7-216mhz",
"tfliteFileSizeBytes": 26503768,
"isSupportedOnMcu": true,
"memory": {
"tflite": {
"ram": 12902,
"rom": 26528840,
"arenaSize": 12774
},
"eon": {
"ram": 9584,
"rom": 26368672,
"arenaSize": 8496
}
},
"timePerInferenceMs": 100,
"customMetrics": [],
"hasPerformance": true
}
Performance on device types:
============================
{
"variant": "int8",
"lowEndMcu": {
"description": "Estimate for a Cortex-M0+ or similar, running at 40MHz",
"timePerInferenceMs": 25699,
"memory": {
"tflite": {
"ram": 12748,
"rom": 26524280
},
"eon": {
"ram": 9456,
"rom": 26368064
}
},
"supported": true
},
"highEndMcu": {
"description": "Estimate for a Cortex-M7 or other high-end MCU/DSP, running at 240MHz",
"timePerInferenceMs": 446,
"memory": {
"tflite": {
"ram": 12902,
"rom": 26528840
},
"eon": {
"ram": 9584,
"rom": 26368672
}
},
"supported": true
},
"highEndMcuPlusAccelerator": {
"description": "Estimate for an MCU plus neural network accelerator",
"timePerInferenceMs": 75,
"memory": {
"tflite": {
"ram": 12902,
"rom": 26528840
},
"eon": {
"ram": 9584,
"rom": 26368672
}
},
"supported": true
},
"mpu": {
"description": "Estimate for a Cortex-A72, x86 or other mid-range microprocessor running at 1.5GHz",
"timePerInferenceMs": 60,
"rom": 26503768.0,
"supported": true
},
"gpuOrMpuAccelerator": {
"description": "Estimate for a GPU or high-end neural network accelerator",
"timePerInferenceMs": 10,
"rom": 26503768.0,
"supported": true
}
}
profiling_cortex-m7-216mhz_int8_run2
Target results for int8:
========================
{
"variant": "int8",
"device": "cortex-m7-216mhz",
"tfliteFileSizeBytes": 26503768,
"isSupportedOnMcu": true,
"memory": {
"tflite": {
"ram": 12902,
"rom": 26528840,
"arenaSize": 12774
},
"eon": {
"ram": 9584,
"rom": 26368672,
"arenaSize": 8496
}
},
"timePerInferenceMs": 124,
"customMetrics": [],
"hasPerformance": true
}
Performance on device types:
============================
{
"variant": "int8",
"lowEndMcu": {
"description": "Estimate for a Cortex-M0+ or similar, running at 40MHz",
"timePerInferenceMs": 31891,
"memory": {
"tflite": {
"ram": 12748,
"rom": 26524280
},
"eon": {
"ram": 9456,
"rom": 26368064
}
},
"supported": true
},
"highEndMcu": {
"description": "Estimate for a Cortex-M7 or other high-end MCU/DSP, running at 240MHz",
"timePerInferenceMs": 552,
"memory": {
"tflite": {
"ram": 12902,
"rom": 26528840
},
"eon": {
"ram": 9584,
"rom": 26368672
}
},
"supported": true
},
"highEndMcuPlusAccelerator": {
"description": "Estimate for an MCU plus neural network accelerator",
"timePerInferenceMs": 92,
"memory": {
"tflite": {
"ram": 12902,
"rom": 26528840
},
"eon": {
"ram": 9584,
"rom": 26368672
}
},
"supported": true
},
"mpu": {
"description": "Estimate for a Cortex-A72, x86 or other mid-range microprocessor running at 1.5GHz",
"timePerInferenceMs": 74,
"rom": 26503768.0,
"supported": true
},
"gpuOrMpuAccelerator": {
"description": "Estimate for a GPU or high-end neural network accelerator",
"timePerInferenceMs": 13,
"rom": 26503768.0,
"supported": true
}
}