How to make one object FOMO have fewer false positives?
I have tried lots of methods, just wondering if anyone knows the best technique for reducing FOMO vision false positives.
Background: once a week I teach an after school https://www.gearbots.org/overview/ group of kids with strong Arduino skills and we are working on a ML car. Presently we have it trained on a single object and it works fine, but as we increase the speed of the cars a single false positive can have it turn drastically away from the track of objects.
I can programmatically improve the situation but wondering if anyone has suggestions for reducing the number of FOMO false positives.
I am thinking of trying to train it for the carpet only, but I don’t really want a ton of extra classifications. So can anyone think of an improvement? Basically at speed a 1 in 20 false reading has the car drastically turning away from the track.
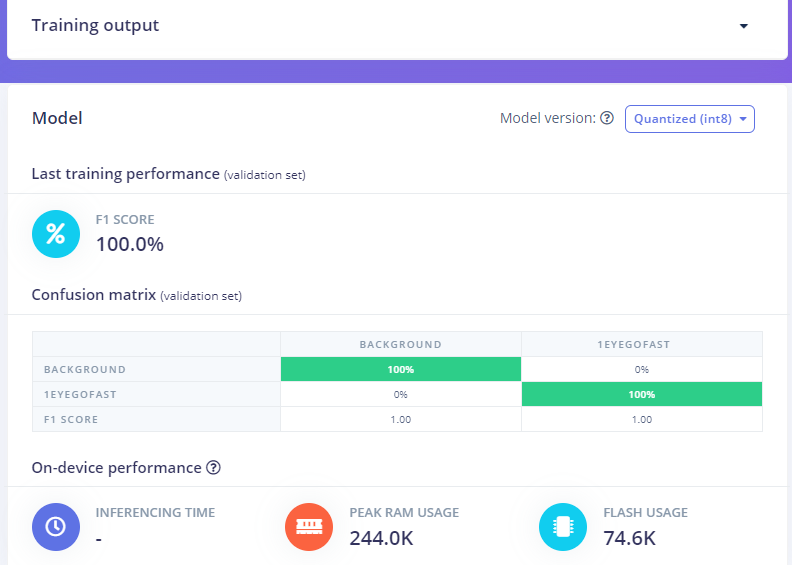
Would you provide more information? the accuracy of the trained model, the F1 Score, the size of the dataset, the accuracy of the testing set, and the distribution of the training set (what kind of images are there and what are the differences, and what is the number of each one of these).
Also, we need to see the images captured from the car during the movement, it would be ideal to capture all of these images, and compare them to the images inside the dataset. (Eventually adding them to the dataset and retrain the model)
If you would like the car to stop going out of the track, what you can do (if this is possible) is buy a wide-angle lens and use them on the camera sensor, this will increase the camera view range. Capture images with all the possible angles and then build a model that detects the location and the object. And use the location on the screen for your car autopilot as you are doing right now.
One additional thing you can do is to increase the number of Frames per second and reduce the speed applied on the motors. This can be possible depending on the type of MCU you are using.
Thanks for the reply @OmarShrit I am really looking for generic things to do to reduce the false positives such as changing the object Weights etc, but since you asked here is more information:
My model is trained on 94 images like the image above. I use the PortentaH7 with LoRa vision shield which has a wide angle grayscale lens. For better image collection I am designing a way to drive the car and collect the images from a website. Just trying to get websockets working so that the image collection is faster. I have recently changed the camera angle which means I need to design a new model and collect new images.
I can increase the frames per second from 30 to 60 so I will probably do that.
As you can see my model is very well trained and that is part of why I ask the question, “Is there anything else I can do to reduce the false positives?” I would prefer false negatives as the car would just keep driving, the random false positive often has the car dramatically changing direction.
The number of images you have is very low, 94 images are really nothing.
I would expect to have at least 3k images for training and 300 for testing.
Here is what I would expect the dataset to have:
-
Having images that contain the background alone without the circle, different background if the car is intended to run on these different surfaces. (Nothing to label here because there is no objects, just add images with no label)
-
Images that contain the circle. However, not only the circle in the middle of the image like above, but instead you need a variety of images, where the circle can be anywhere in the images, top, down, left, right, and also you need images where the circle is half + quarter captured by the camera because in some cases the images are not only in the centre
-
Images that are captured by the Arduino Portenta, let us say e.g,5 ~ 10 percent that you need to capture from the Arduino and add them to your project.
Thanks @OmarShrit I had no idea that FOMO used just background alone images. That will be a big help. I will also try partial images but I originally thought that would cause more false positives so I was not using them. 3K images is quite a goal!
It should be easy to do once I have improved my image collection.
I was thinking to have 100% of the images from the Portenta vision shield camera, but are you saying that is not as important?
Thanks so much for the informed reply @OmarShrit have a great day!
in expert mode there is also the option to set the object_weight=100 which change the weighting in the loss function for non background objects. another way to reduce false positives is to reduce this number.
i can’t remember sorry @rocksetta whether you had tried this?
1 Like
do you have any smoothing across frames? it doesn’t always help but sometimes doing a rolling average can be useful; then you can trade off a small amount of latency in decision to potentially avoid a catastrophic outcome. a rough heuristic of whether it might help is whether you get bouncing FPs; e.g. a sequence of detections like 0,0,0,0,1,1,1,1 is stable but 0,0,0,1,0,1,0,1,0 looks more suspicious
the simplest way to do the rolling average is over the probabilities output. that’s requires no model change.
but the more principled way is to do the rolling average over the logits before the softmax; i.e. take the softmax layer off. collect logits into a rolling buffer. at each step just sum the buffer ( since logits are zero centered ) and softmax that. it’s more principled since the averaging assuming a linear relationship; which holds for the logits, but not the softmax ( because of the exp operations )
2 Likes
you’re working in greyscale yeah? you could pack the current frame, frame before and frame before that as RGB channels into a single PNG and train the model that way. you’d have a video aware model 
1 Like
@matkelcey thanks for all the ideas, I like having lots of options. I did try changing the object_weight and background values with not much change, so I have been fully working on a better data collection system. I am fairly close to having a PNG collection system working using websockets to drive the vehicle and control when to take an image to save on the Portenta vision shield SD card.
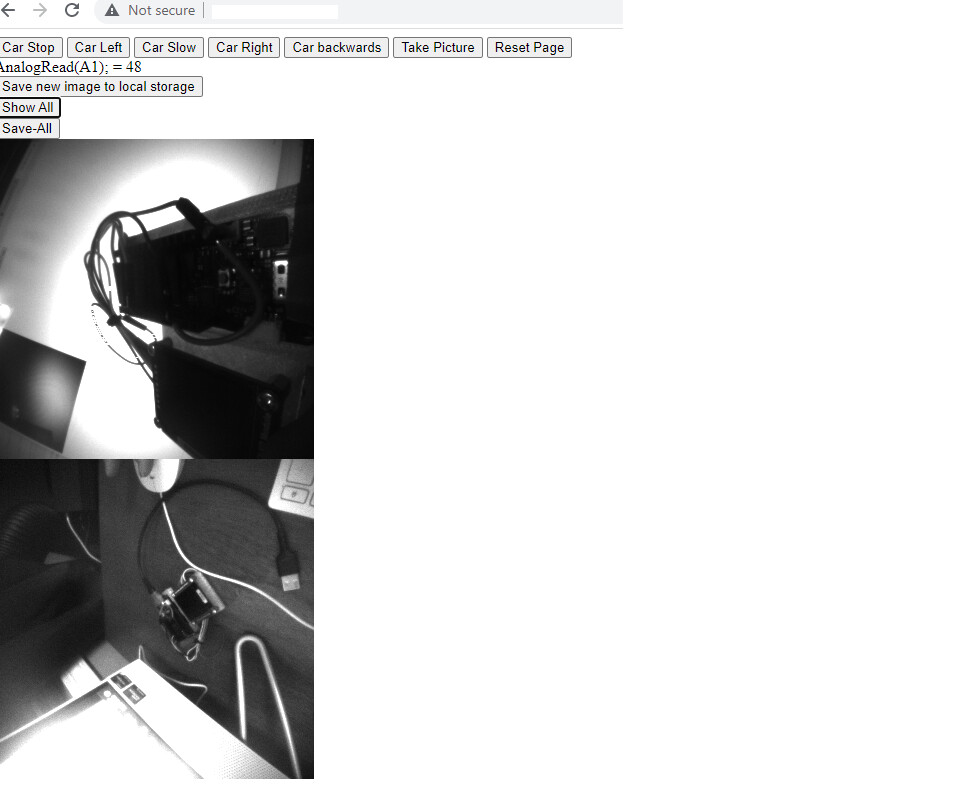
Very little left to do. I have WiFiSSLClient websockets working and converting the Portenta camera image from BMP to PNG working, even have a conversion to Base64 and dump on a webpage, but that is too slow.
I wanted the image to load using websockets onto a webpage so I could use the NiclaVision but that is proving too slow. (The websockets are fast but the Portenta seems slow probably processing the masked data the websocket needs). Actually the NiclaVision only seems to work with my PNG to Base64 to webpage code,but does not seem to work with my websocket code.
I hope collecting better images helps the FOMO model. I did find taking images without my objects in them and selecting the entire window and calling it “background” seemed to help a bit. I will update if I can get my websocket driving data collection PNG to sd card system working.
Here is a shot of the too slow webpage version of what I am trying to make. In this version PNG to base64 images were loaded to the webpage and could be saved to local storage or downloaded as a group.