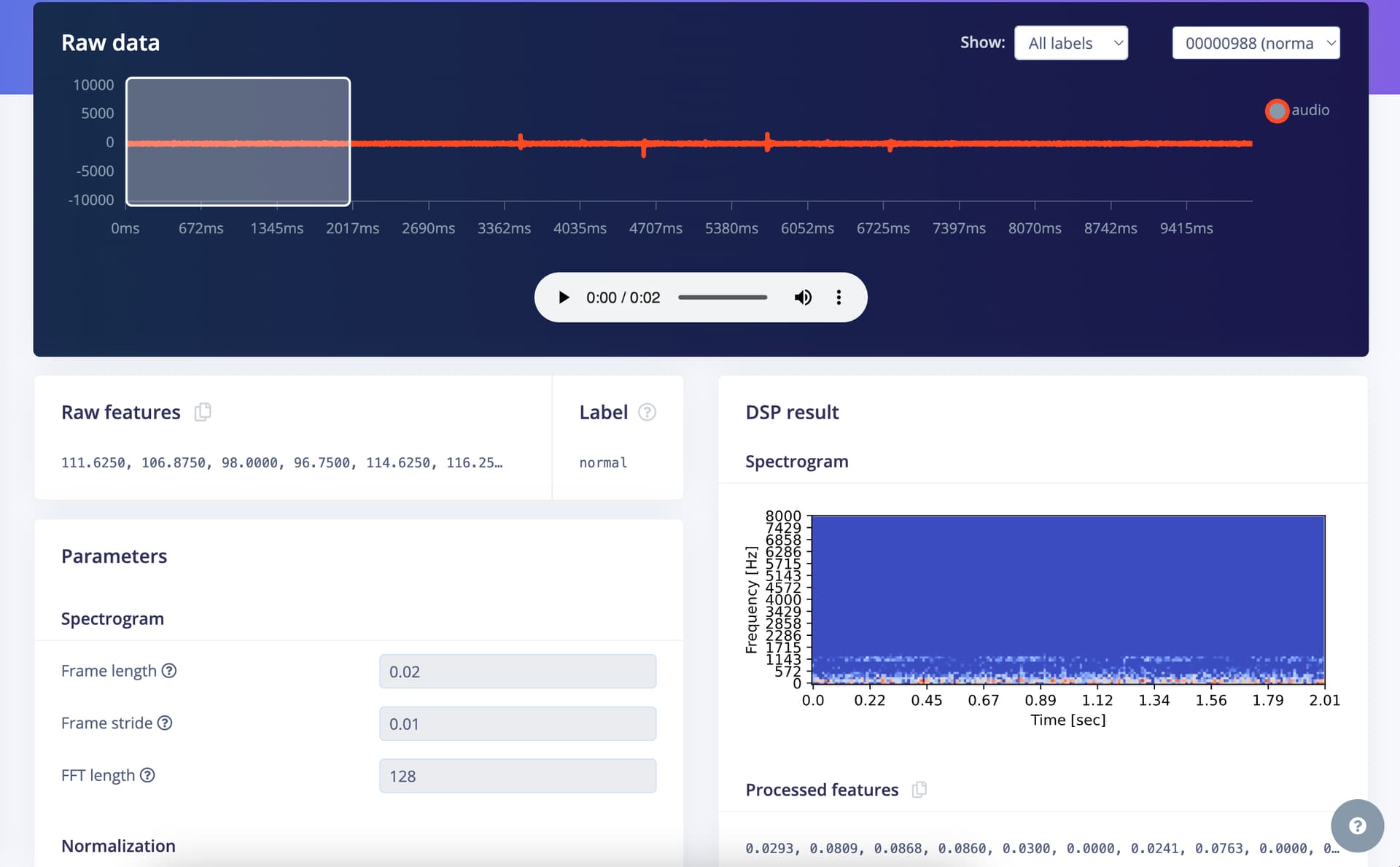
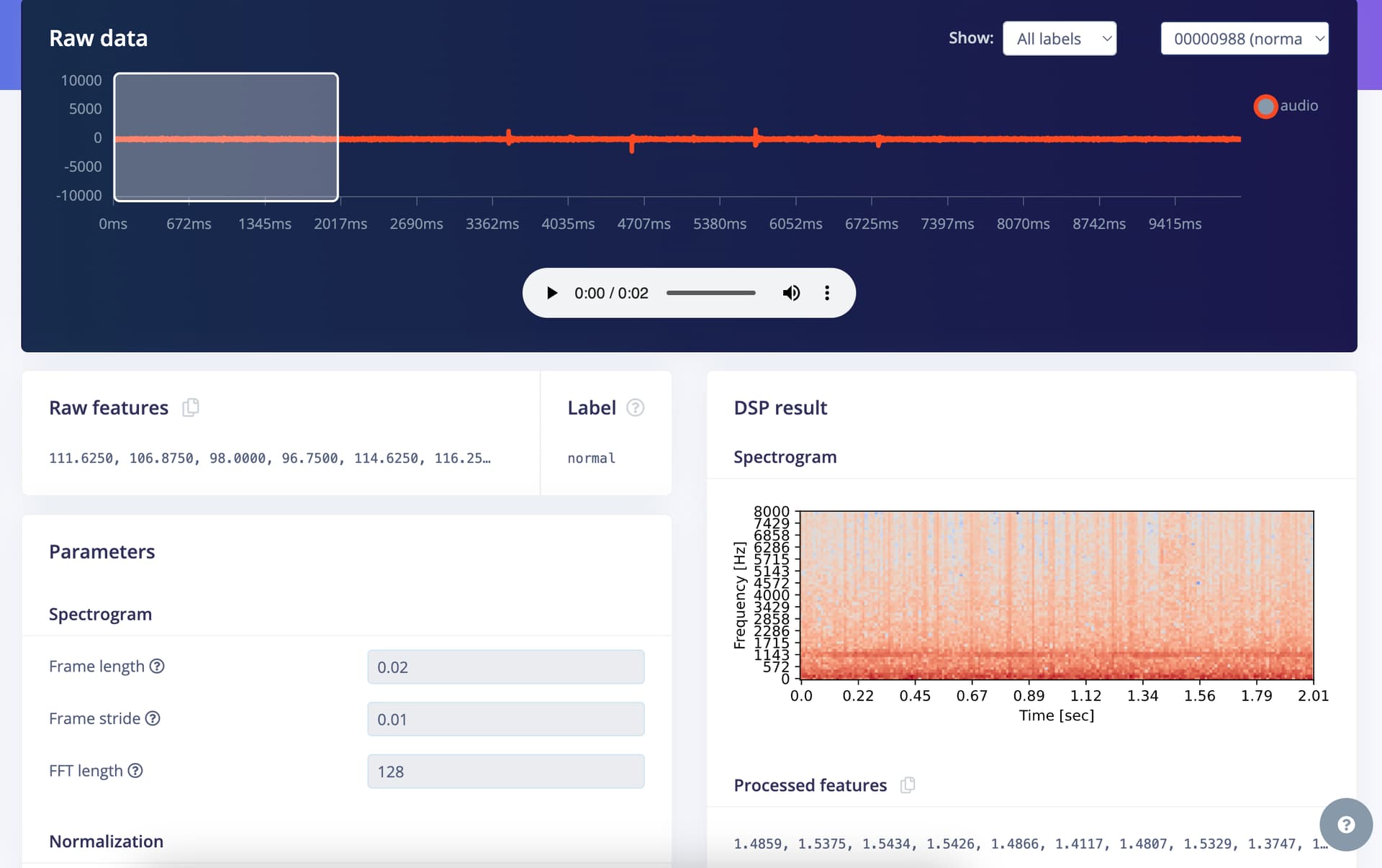
Question/Issue:
I am trying to implement the project from https://www.edgeimpulse.com/blog/predicting-the-future-of-industry/ into ESP32. I am first trying to create a model that is independent of the target device. I thought I constructed the model in a similar way as presented in the project, with the same impulses and parameters, but when I do the model training, I get completely different results, with no change in accuracy at all. I would be grateful if you could confirm where the difference is occurring, as my current knowledge does not allow me to find it. The first project ID is a project that I created from scratch in the same way, and the second project ID is a project that I retrained from an already completed project, only changing the dataset. I am not sure where the exact difference between these two projects is occurring.
Project ID:
first project: 510309
second project: 509816
Context/Use case:
When I do the model training, I get completely different results, no accuracy change.
(in first project. second project has no problem.)
Steps Taken:
I’ve been experimenting with different conditions since yesterday, but the results from the two projects continue to differ.
Expected Outcome:
Maybe same or similar result?
Actual Outcome:
No change in accuracy at all.
Reproducibility:
Always
Environment:
- Platform: will be ESP32-S3
- Build Environment Details: Not build environment yet.
- OS Version: Windows 10
- Edge Impulse Version (Firmware): Not changed yet.
- To find out Edge Impulse Version:
- if you have pre-compiled firmware: run edge-impulse-run-impulse --raw and type AT+INFO. Look for Edge Impulse version in the output.
- if you have a library deployment: inside the unarchived deployment, open model-parameters/model_metadata.h and look for EI_STUDIO_VERSION_MAJOR, EI_STUDIO_VERSION_MINOR, EI_STUDIO_VERSION_PATCH
- Edge Impulse CLI Version: Not changed yet.
- Project Version: Not changed yet.
-
Custom Blocks / Impulse Configuration: I only used spectorgram and classifier keras model.
Logs/Attachments:
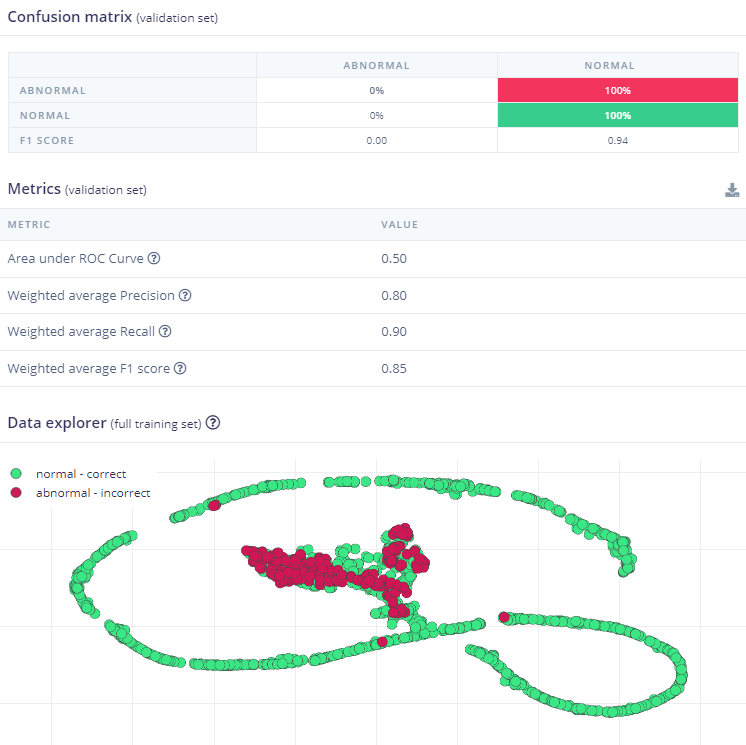
The first project results.
Additional Information:
I used same Keras model
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, InputLayer, Dropout, Conv1D, Conv2D, Flatten, Reshape, MaxPooling1D, MaxPooling2D, AveragePooling2D, BatchNormalization, Permute, ReLU, Softmax
from tensorflow.keras.optimizers.legacy import Adam
EPOCHS = args.epochs or 100
LEARNING_RATE = args.learning_rate or 0.005
If True, non-deterministic functions (e.g. shuffling batches) are not used.
This is False by default.
ENSURE_DETERMINISM = args.ensure_determinism
this controls the batch size, or you can manipulate the tf.data.Dataset objects yourself
BATCH_SIZE = args.batch_size or 32
if not ENSURE_DETERMINISM:
train_dataset = train_dataset.shuffle(buffer_size=BATCH_SIZE*4)
train_dataset=train_dataset.batch(BATCH_SIZE, drop_remainder=False)
validation_dataset = validation_dataset.batch(BATCH_SIZE, drop_remainder=False)
model architecture
model = Sequential()
model.add(Reshape((int(input_length / 65), 65), input_shape=(input_length, )))
model.add(Conv1D(8, kernel_size=3, padding=‘same’, activation=‘relu’))
model.add(MaxPooling1D(pool_size=2, strides=2, padding=‘same’))
model.add(Dropout(0.25))
model.add(Conv1D(16, kernel_size=3, padding=‘same’, activation=‘relu’))
model.add(MaxPooling1D(pool_size=2, strides=2, padding=‘same’))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(20, activation=‘relu’,
activity_regularizer=tf.keras.regularizers.l1(0.00001)))
model.add(Dense(10, activation=‘relu’,
activity_regularizer=tf.keras.regularizers.l1(0.00001)))
model.add(Dense(classes, name=‘y_pred’, activation=‘softmax’))
this controls the learning rate
opt = Adam(learning_rate=LEARNING_RATE, beta_1=0.9, beta_2=0.999)
callbacks.append(BatchLoggerCallback(BATCH_SIZE, train_sample_count, epochs=EPOCHS, ensure_determinism=ENSURE_DETERMINISM))
train the neural network
model.compile(loss=‘categorical_crossentropy’, optimizer=opt, metrics=[‘accuracy’])
model.fit(train_dataset, epochs=EPOCHS, validation_data=validation_dataset, verbose=2, callbacks=callbacks)
Use this flag to disable per-channel quantization for a model.
This can reduce RAM usage for convolutional models, but may have
an impact on accuracy.
disable_per_channel_quantization = False