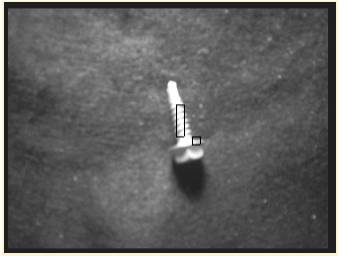
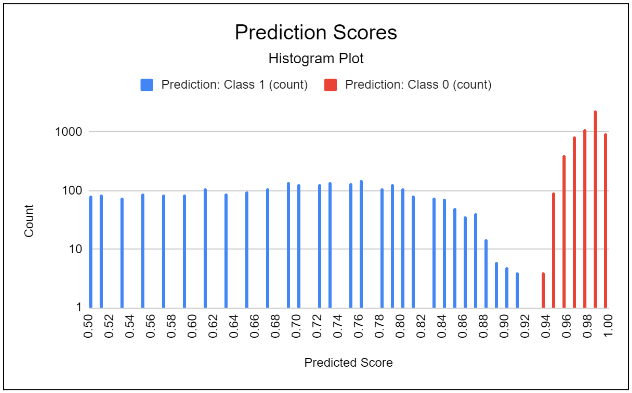
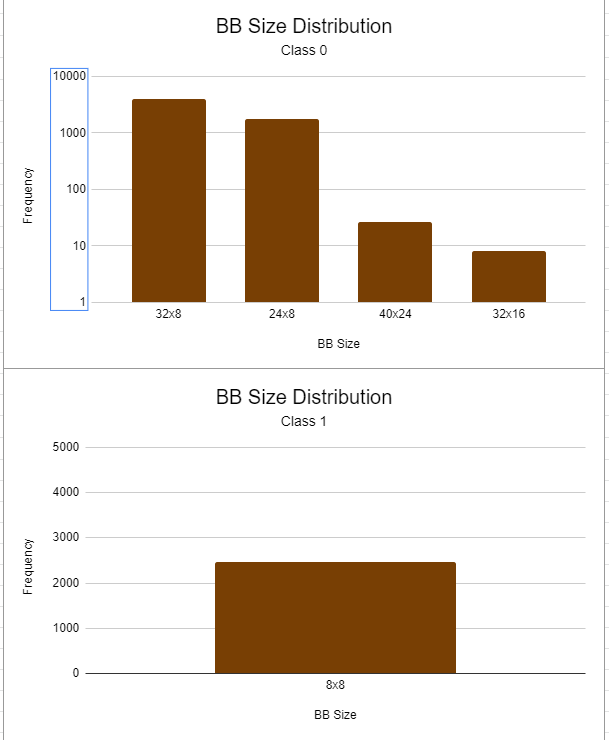
Yes, it seems the Class 1 should be part of Class 0.
To answer your question regarding, “we’re not sure what have you labelled as class 1?”, I will explain with an example. Note that my Impulse only has one output called screw.
Given this code:
run_classifier(&signal, &ei_result, debug);
FOMO_Count = 0;
for (ix = 0; ix < EI_CLASSIFIER_OBJECT_DETECTION_COUNT; ix++)
{
if (ei_result.bounding_boxes[ix].value > 0)
{
FOMO_Count = FOMO_Count + 1;
}
}
Then FOMO_Count is the number of Classes found, i.e., is the count of Bounding Boxes (BBs) or screws that FOMO found.
If FOMO_Count = 1, then only Class 0 exists.
If FOMO_Count = 2, then only Class 0 and Class 1 exists.
If FOMO_Count = 3, then only Class 0 and Class 1 and Class 2 exists.
Etc.
Class in this context allows us to reference the various BBs in the FOMOed image.
The code under fill_result_struct_from_cubes() helped explain the BB sizes being returned from a FOMO model.
FYI: The code at fill_result_struct_from_cubes() also explains why bounding_boxes_count is always equal to 10 when the number of FOMOed objects is less than EI_CLASSIFIER_OBJECT_DETECTION_COUNT. Likewise, the doc stating, "The exact number of bounding boxes is stored in bounding_boxes_count field of ei_impulse_result_t" is not completely accurate.
Regarding the size of the BBs found by FOMO, consider that part of this issue resolved. I ass-u-me-d that when I saw the Edge Impulse images of Jan’s beer bottles and the image of bees that FOMO was returning a single centroid but I now believe that FOMO is returning one or more fused Bounding Box(s) located around a central centroid.
My assumption was that the beer bottle image and the image of bees was a direct output of FOMO. This is not the case. The images have circles placed on a centroid that was derived from the FOMO Bounding Box output.
My original question still stands. How do I stop FOMO from counting the same screw more than once which is happening about 1/2 of the time in the referenced dataset?