Question/Issue:
[Why is my model showing different (and also extremely large) results when deployed to my Raspberry Pico RP2040 device?]
Project ID:
[315617]
Context/Use case:
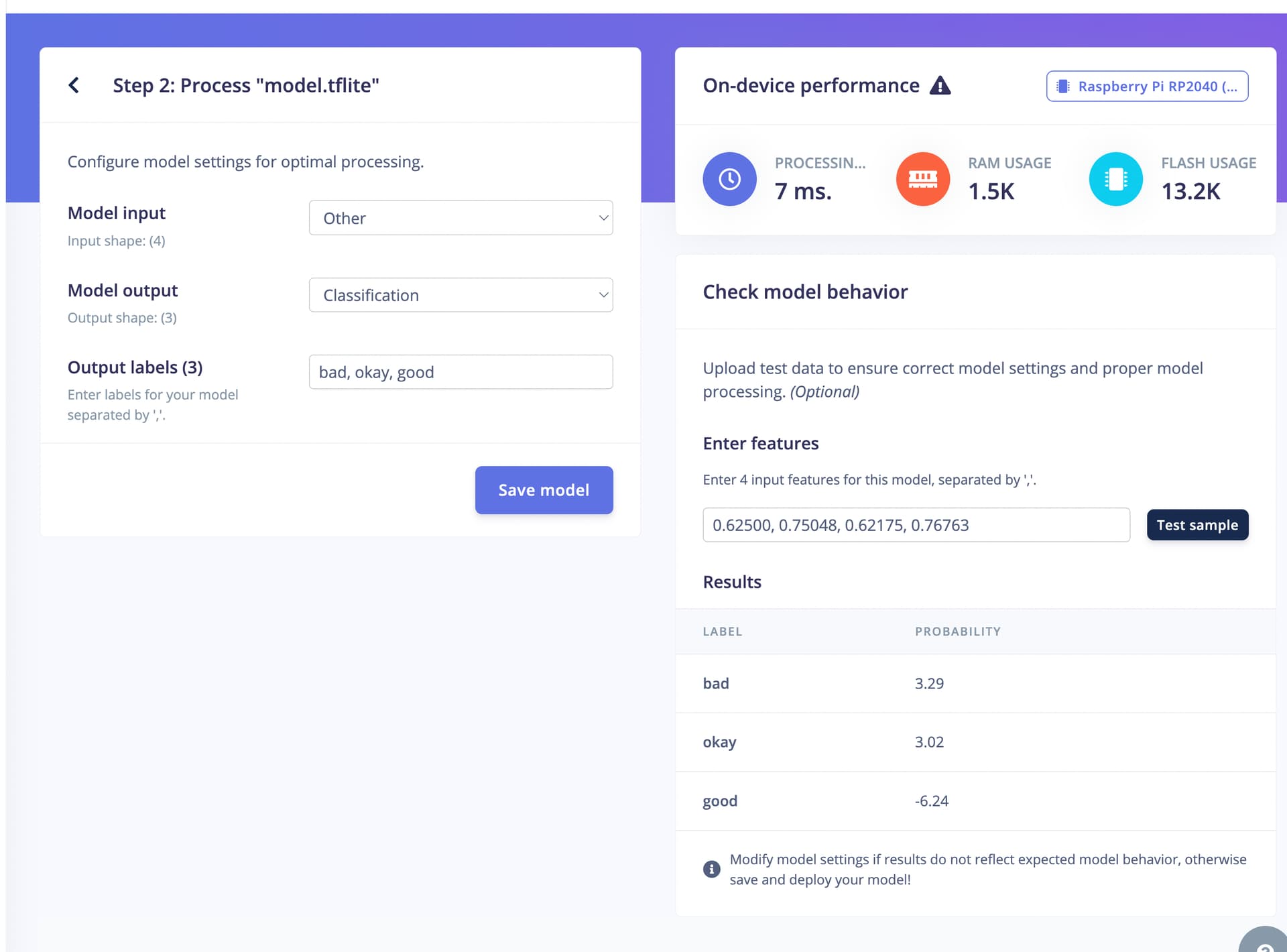
[I have a locally trained tensorflow light model (4 inputs, classified into three outputs) that I have compiled through edge impulse as a standard c++ library, which I am deploying to a Raspberry Pico RP2040. When testing the tflite model locally, and through the edge impulse webpage, I get good results, with probabilities usually between -10 and 10. When I deploy to the RP2040, the category probabilities are massive, and often incorrect. They are anywhere from -105,000 to 60,000. ]
Steps Taken:
I have tried normalizing my model inputs from 0 to 1 with no luck.
I have tried comparing the scale of the larger outputs from the device with the testing outputs, but there is no correlation.
I have reproduced the same issue on multiple RP2040 devices, with multiple model deployments.
Model upload is a tricky one you are using a custom model here, please review our docs for best practices and the troubleshooting here for caveats with preprocessing :
Thanks for your replies. I do not have a solutions engineer reviewing this for me at the moment.
I wasn’t able to run this by exporting the pico firmware, I’m using some custom sensor code on my pico and I couldn’t figure out how to incorporate that while exporting the pico firmware.
I did try the int8 version, and while the results on the pico were far less large, they still were different than the “check model behavior”. It also seemed like there wasn’t much variance in my NN output, even though my input tensor was changing the output was remaining constant.
I also tried running the standalone inferencing, but I could not get it to compile with both make and mingw32-make, I’m getting a [Makefile:110: app] Error 87. I’m a bit more familiar with cmake.
Lastly, I did finally find out how to revert my project back from a BYOM to custom edge impulse blocks, and that showed good success. I trained a similar model through the edge portal, and exported as a C++ library and it worked just fine. For now I will use this model, but I’ll try and get the standalone inferencing to compile.