Everyone, My computer is a Mac with Sequoia 15.6.
The device used is Seeed’s Wio Terminal
I followed the whole process, exported a sound model file and ran one of the simplest official routines and found a very strange framework error.
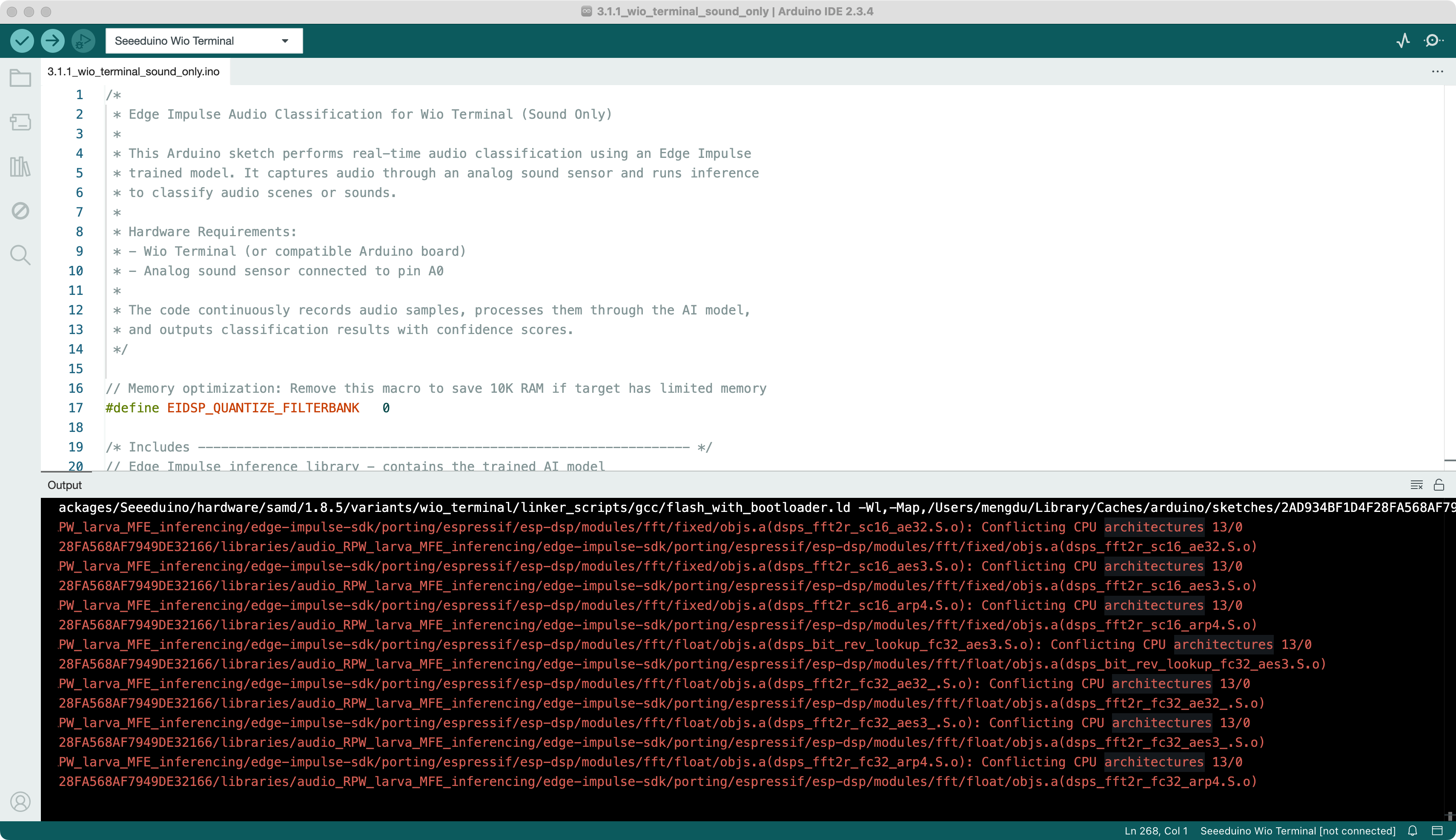
I read this thread and it looks like his mistakes are extremely similar to mine.
On one hand, I cleared the path of the sketch mentioned in the error:

On the other hand, I have also deleted the entire ESP-NN folder inside the model file:
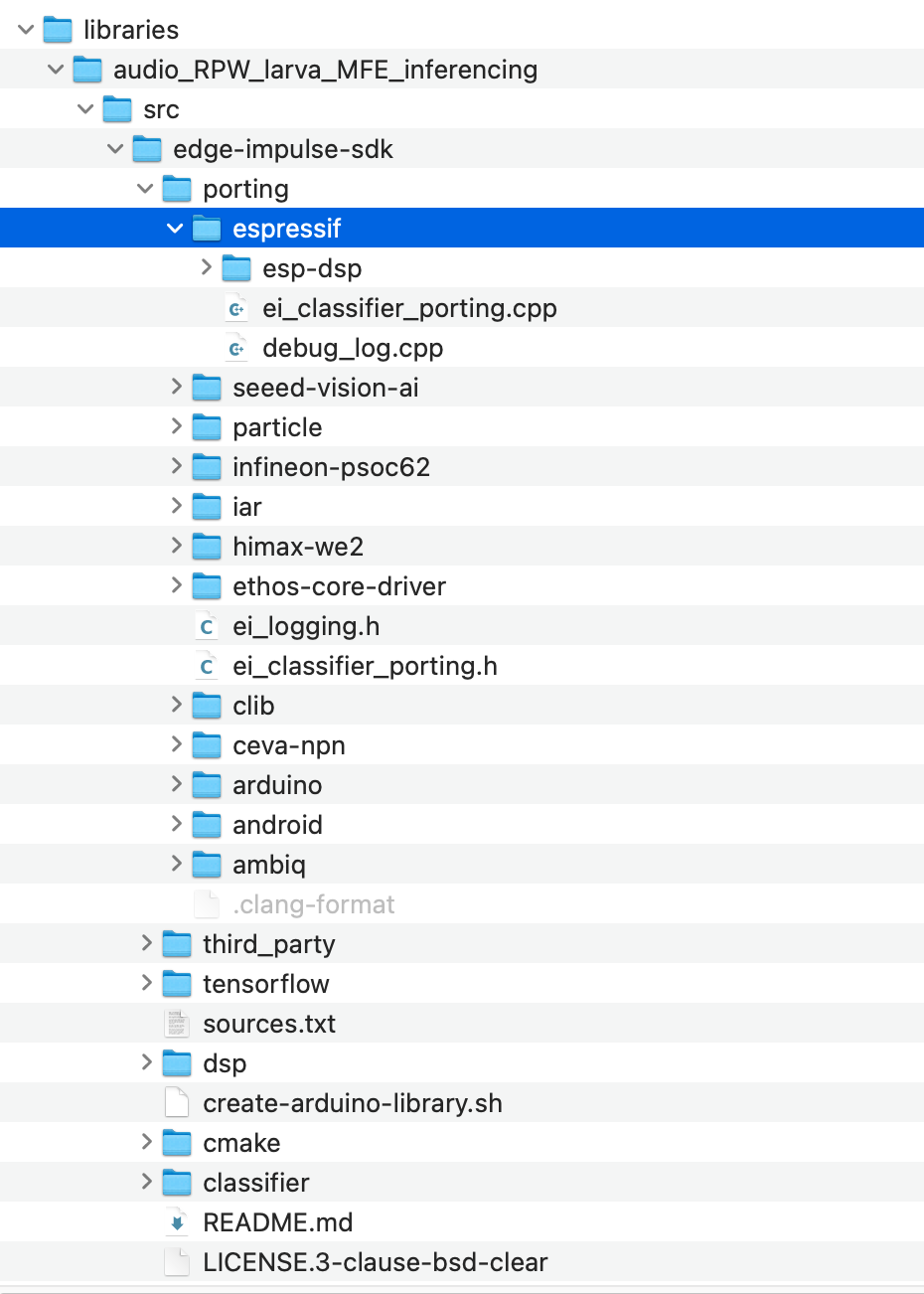
But recompiling, the problem appeared as it did, and I ran into difficulties that prevented the project from moving forward. Does anyone have any other suggestions, please? Below is my code.
// Memory optimization: Remove this macro to save 10K RAM if target has limited memory
#define EIDSP_QUANTIZE_FILTERBANK 0
/* Includes ---------------------------------------------------------------- */
// Edge Impulse inference library - contains the trained AI model
#include <audio_RPW_larva_MFE_inferencing.h>
// Pin configuration for analog sound sensor
#define SoundPin A0
/**
* Data structure for audio inference management
* This struct holds all necessary data for audio sampling and processing
*/
typedef struct {
int16_t *buffer; // Pointer to audio sample buffer (16-bit signed integers)
uint8_t buf_ready; // Flag indicating if buffer is ready for processing (0/1)
uint32_t buf_count; // Current number of samples in buffer
uint32_t n_samples; // Total number of samples needed for inference
} inference_t;
// Global inference data structure instance
static inference_t inference;
// Static buffer for audio samples (alternative buffer, currently unused in this code)
static signed short sampleBuffer[2048];
// Calculate sampling period in microseconds for 16kHz sampling rate
// Formula: (600000 * (1.0 / desired_sample_rate)) = microseconds per sample
unsigned int sampling_period_us = round(600000 * (1.0 / 16000));
// Debug flag - set to true to see detailed neural network processing info
static bool debug_nn = false;
/**
* @brief Arduino setup function - runs once at startup
*
* Initializes serial communication, displays model information,
* and sets up the audio sampling system for inference.
*/
void setup()
{
// Initialize serial communication at 115200 baud rate for debugging output
Serial.begin(115200);
// Print welcome message
Serial.println("Edge Impulse Inferencing Demo");
// Display comprehensive model information and settings
ei_printf("Inferencing settings:\n");
ei_printf("\tInterval: %.2f ms.\n", (float)EI_CLASSIFIER_INTERVAL_MS);
ei_printf("\tFrame size: %d\n", EI_CLASSIFIER_DSP_INPUT_FRAME_SIZE);
ei_printf("\tSample length: %d ms.\n", EI_CLASSIFIER_RAW_SAMPLE_COUNT / 16);
ei_printf("\tNo. of classes: %d\n", sizeof(ei_classifier_inferencing_categories) / sizeof(ei_classifier_inferencing_categories[0]));
// Initialize the microphone inference system
// EI_CLASSIFIER_RAW_SAMPLE_COUNT defines how many samples are needed
if (microphone_inference_start(EI_CLASSIFIER_RAW_SAMPLE_COUNT) == false) {
ei_printf("ERR: Failed to setup audio sampling\r\n");
return;
}
}
/**
* @brief Arduino main loop function - runs continuously
*
* This function performs the complete audio classification workflow:
* 1. Records audio samples from the analog sensor
* 2. Runs the Edge Impulse classifier on the audio data
* 3. Displays classification results with confidence scores
* 4. Repeats the process continuously
*/
void loop()
{
// Notify user that audio recording is starting
ei_printf("Recording...\n");
// Capture audio samples from the microphone/sound sensor
bool m = microphone_inference_record();
if (!m) {
ei_printf("ERR: Failed to record audio...\n");
return;
}
// Notify user that recording is complete
ei_printf("Recording done\n");
// Prepare signal structure for Edge Impulse classifier
signal_t signal;
signal.total_length = EI_CLASSIFIER_RAW_SAMPLE_COUNT; // Total number of samples
signal.get_data = µphone_audio_signal_get_data; // Function to retrieve audio data
// Initialize result structure to store classification output
ei_impulse_result_t result = { 0 };
// Run the Edge Impulse classifier on the recorded audio
// debug_nn parameter controls whether to show detailed processing info
EI_IMPULSE_ERROR r = run_classifier(&signal, &result, debug_nn);
if (r != EI_IMPULSE_OK) {
ei_printf("ERR: Failed to run classifier (%d)\n", r);
return;
}
// Display classification results with timing information
ei_printf("Predictions ");
ei_printf("(DSP: %d ms., Classification: %d ms., Anomaly: %d ms.)",
result.timing.dsp, result.timing.classification, result.timing.anomaly);
ei_printf(": \n");
// Print confidence scores for each classification label
for (size_t ix = 0; ix < EI_CLASSIFIER_LABEL_COUNT; ix++) {
ei_printf(" %s: %.5f\n", result.classification[ix].label, result.classification[ix].value);
}
// If anomaly detection is enabled in the model, display anomaly score
#if EI_CLASSIFIER_HAS_ANOMALY == 1
ei_printf(" anomaly score: %.3f\n", result.anomaly);
#endif
}
/**
* @brief Custom printf function for Edge Impulse library
*
* This function provides formatted output similar to standard printf,
* but routes the output through Arduino's Serial interface.
*
* @param[in] format Printf-style format string
* @param[in] ... Variable arguments matching the format string
*/
void ei_printf(const char *format, ...) {
// Static buffer to hold formatted string (1KB max)
static char print_buf[1024] = { 0 };
// Handle variable arguments using standard library functions
va_list args;
va_start(args, format);
// Format the string into the buffer
int r = vsnprintf(print_buf, sizeof(print_buf), format, args);
va_end(args);
// Output the formatted string via Serial if formatting was successful
if (r > 0) {
Serial.write(print_buf);
}
}
/**
* @brief Initialize inference system and audio sampling setup
*
* This function allocates memory for the audio buffer and initializes
* the inference structure with the required parameters. It also configures
* the analog pin for reading audio data.
*
* @param[in] n_samples Number of audio samples needed for inference
*
* @return true if initialization successful, false if memory allocation fails
*/
static bool microphone_inference_start(uint32_t n_samples)
{
// Allocate memory for audio sample buffer (16-bit integers)
inference.buffer = (int16_t *)malloc(n_samples * sizeof(int16_t));
// Check if memory allocation was successful
if(inference.buffer == NULL) {
return false;
}
// Initialize inference structure parameters
inference.buf_count = 0; // Start with empty buffer
inference.n_samples = n_samples; // Store required sample count
inference.buf_ready = 0; // Buffer not ready initially
// Configure the sound sensor pin as analog input
pinMode(SoundPin, INPUT);
return true;
}
/**
* @brief Record audio samples from analog sensor
*
* This function captures audio data by reading from the analog sound sensor
* at a controlled sampling rate. It converts the 10-bit ADC values (0-1023)
* to 16-bit signed integers (-32768 to 32767) for audio processing.
*
* @return Always returns true when recording cycle completes
*/
static bool microphone_inference_record(void)
{
// Reset buffer state for new recording
inference.buf_ready = 0;
inference.buf_count = 0;
// Record audio samples if buffer is not ready
if (inference.buf_ready == 0) {
// Sample loop - collect up to 8001 samples or until buffer is full
for(int i = 0; i < 8001; i++) {
// Read analog value from sound sensor and convert to 16-bit signed
// map() converts 10-bit ADC (0-1023) to 16-bit audio range (-32768 to 32767)
inference.buffer[inference.buf_count++] = map(analogRead(SoundPin), 0, 1023, -32768, 32767);
// Wait for the calculated sampling period to maintain 16kHz sampling rate
delayMicroseconds(sampling_period_us);
// Check if we have collected enough samples for inference
if(inference.buf_count >= inference.n_samples) {
inference.buf_count = 0; // Reset counter
inference.buf_ready = 1; // Mark buffer as ready
break; // Exit sampling loop
}
}
}
return true;
}
/**
* @brief Retrieve and convert audio signal data for Edge Impulse processing
*
* This callback function is used by the Edge Impulse classifier to access
* the recorded audio data. It converts 16-bit integer samples to floating
* point format as required by the neural network.
*
* @param[in] offset Starting position in the audio buffer
* @param[in] length Number of samples to retrieve
* @param[out] out_ptr Pointer to output buffer for float data
*
* @return 0 on success
*/
static int microphone_audio_signal_get_data(size_t offset, size_t length, float *out_ptr)
{
// Convert 16-bit integer audio samples to float format
// This uses Edge Impulse's numpy-style conversion function
numpy::int16_to_float(&inference.buffer[offset], out_ptr, length);
return 0;
}
/**
* @brief Clean up inference system and release memory
*
* This function should be called when audio inference is no longer needed.
* It frees the dynamically allocated audio buffer to prevent memory leaks.
* Note: This function is defined but not currently called in the main loop.
*/
static void microphone_inference_end(void)
{
// Free the dynamically allocated audio buffer
free(inference.buffer);
}
// Compile-time check to ensure the Edge Impulse model was trained for microphone/audio data
// This preprocessor directive will cause a compilation error if the wrong model type is used
#if !defined(EI_CLASSIFIER_SENSOR) || EI_CLASSIFIER_SENSOR != EI_CLASSIFIER_SENSOR_MICROPHONE
#error "Invalid model for current sensor. This code requires a microphone-trained Edge Impulse model."
#endif