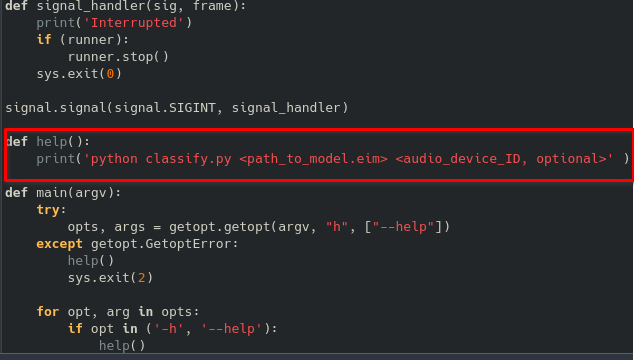
Question/Issue:
hello, I am a beginner and learning about voice/audio classification with Raspberry Pi. and I found the edge impulse python Linux SDK, I can run inference real time on the RPi board perfectly, thanks for dev team.
but I have concern, here is some of my questions:
where is the math operation for DSP and NN part, because I don’t find it in this file and in the library?
what is the meaning value after result part?
on edge impulse we can see information of performance on the device. but, how do we know the actual performance of the model we have created? in my case the deploy target is Raspberry Pi 4?
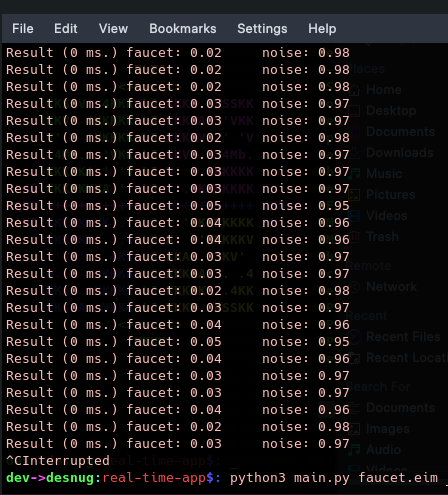
(0 ms.) is the time to run the impulse, faucet 0.XX is the probably your model recognized this class, noise: 0.XX is the probably your model recognized this other class.
Are speaking about the RAM consumption / latency? The RAM you can see it on linux using a tool like top and the latency is given by the inference time ( 0 ms. here in your case, note that we round the results). But you can change the print statement on this line:
can we see the contents of the .eim file? I just want to know and learn how the realtime audio classification process from raw data/unknown sound to getting classification results.
Sorry if I ask a lot of questions, I just want to know the math process behind it. Do you have any reference about it? Because I didn’t find math or equation about DSP in the documentation.
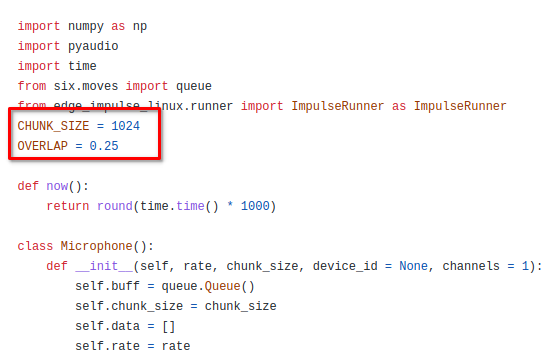
thanks for the explanation. Is chunk_size and overlap here the same as window_size and window_increse in edge impulse studio?
yes, that’s what i meant, about latency and RAM consumption. so is it time inference is the whole process from:
detect sound with microphone → data acquisition → inference/model calculation → result? correct me if i’m wrong.
For the cpp implementation, when you download the cpp library, when you extract the archive, look after this file edge-impulse-sdk → classifier->ei_run_dsp.h.
For example, if you used the mfcc dsp block in the studio, you will find the cpp implementation in the function:
Good question, I’d need to further check, I haven’t used in a while the linux python sdk for audio projects. However, I don’t think that’s the same. I believe it is used to run the inference in a “continuous mode”. See @AIWintermuteAI explanation here The goal of continuous mode is to process one chunk of data (part of the whole window) in less time than it takes to record it. This way continuous inference can be achieved. The time it takes to process one chunk of data depends on a) DSP processing b) NN inference. If it takes more time to process DSP + NN for one chunk of data (that can happen depending on your MFCC/MFE parameters and NN size/complexity) than it takes to record that chunk, you should get an error.
Correct, in the results, if you want to have the split between the dsp and the classification, just print both instead of summing them as in the print statement:
correct me if I’m wrong, based on the explanation window_size > chunk_size? if I have window_size = 1000 ms, the chunk_size value should be smaller than it?
but, to be honest, I still don’t understand in the chunk_size section, what does the value of 1024 and overlap 0.25 mean? if we change these values, will it affect the inference time?
3. thanks again, I can separate the NN and DSP time inference.
last question, I promise. ( )
4. I want to run this python script automatically on startup using crontab. can we shorten the command to run this python sdk:
python classify.py model.eim 1
to:
python classify.py
is it possible for me to call model.eim in the python script. maybe modify this part or which part need to care about.
I am not sure about it, I’ll ask around internally. It won’t change the inference time but more the number of inference occurrences you will run per “window”.
Great
Sure that is up to you how you want to call it, you can remove the expected arguments in the main function and hardcode it in your code.
 )
)