I trained the mobilenet-v3 network under the tensorflow framework for classification and recognition, but the generated model file has a size of 8MB after int8 quantification. It is very difficult to deploy it on openmv-h7 plus. I want to know why the edge impulse online training network model is so small, but the model file I trained is so large?
Hi,
A few factors likely - first off, if you have the EON compiler option selected in the Deployment tab, we are directly compiling the model architecture and weights to source code. Normal tensorflow relies on a flatbuffer and interpreter, which adds overhead. You can read more on that here:
Secondly, you are also likely comparing different mobilenet versions. Our transfer learning blocks use different variants of mobilenet V1 & V2 at 96x96 & 160x160 resolution. We give memory estimates in the description and they vary widely, from 200kb up past 1mb. I’m not super familiar with mobilenetV3, but it does look like its an overall larger model architecture than earlier versions.
Best,
David
1 Like
Continuing the discussion from What is the difference between online training mobilenet network and training network under tensorflow framework?:
First of all, thank you very much for your reply.Why is the accuracy of the neural network model trained by mobilenet-v2-0.35 so different before and after quantization? 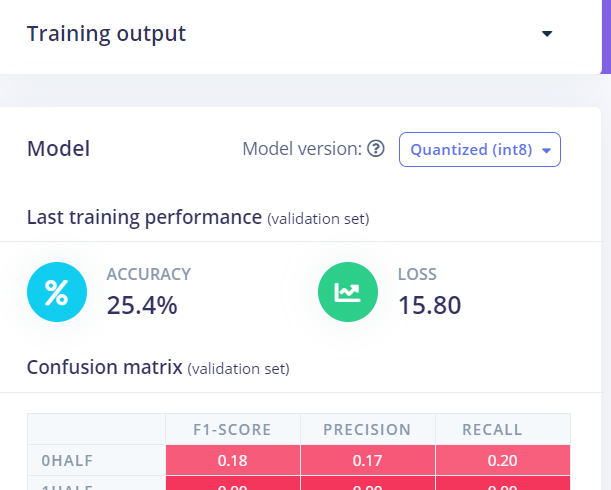 The accuracy difference before and after quantization is about 70%.
The accuracy difference before and after quantization is about 70%.
Also, I would like to ask if the unquantified float32 model I downloaded on the dashboard has been processed by the eon Compiler? The model size of the unquantized float32 is 2MB
That’s something that can typically happen if the objects you are classifying are taking only a small portion of the image. Would be willing to share your project ID?
Also we are working on adding quantization-aware training which could help in this situation.
The model from the dashboard is not processed by the EON Compiler. If you want the TensorFlow model, you can download the TensorFlow SavedModel.
Aurelien
Why can model files that have not been processed by eon compiler in the dashboard be so small?The mobilenetv3 network I trained under the tensorflow framework has a size of 8MB after int8 quantization?
Our MobileNet models are optimized for 96x96 images. We also use an alpha=0.35 or less to reduce the depth of the network.
Which parameters are you using with TensorFlow?
I’m not familiar with MobileNet v3 but it may also explain the difference in size compared to v2.
Aurelien
2 Likes
What optimization operations have you done for mobilenet network to reduce the memory occupied by the generated model?I also used the alpha parameter in mobilenet-v3 network.
Hi @mengmeng,
Great questions! Here’s exactly what we do:
- We start with a base architecture designed for efficiency—the MobileNets are a good example of these.
- We modify the width and depth of the architecture to make it smaller. For MobileNet models the width is expressed as
alpha, which represents a fraction of the original model width—so our 0.35 model is 35% of the original model width. - We train the model as normal.
- We then use post-training quantization to quantize the model (we’ll soon be adding quantization-aware training to combine this with the training step and limit any reduction in accuracy).
- We then use our EON Compiler to generate code that directly implements the model, avoiding the need for any additional overhead beyond the exact kernel implementations and the memory used by the model’s parameters.
This final step results in a model that uses up to 35% less ROM than if you were to use TensorFlow Lite for Microcontrollers. Here’s a blog post with more details.
Hope this helps—let us know if you have any more questions!
Warmly,
Dan
1 Like