I’m missing it in the docs. When I pass four measurements into the Raw Data block I get back twelve, features 0, 1, and 2 for each input. And some of the differences are interesting, except I don’t know what I’m looking at.
Can someone help me understand what those features actually are? I’m guessing that Feature 0 is the ‘raw’ value, but right now that’s just a guess. The others are mysterious to me.
Sorry if I’m being obtuse, but I can’t find this anywhere.
The Raw Data block generates windows from data samples without any specific signal processing. It is great for signals that have already been pre-processed and if you just need to feed your data into the Neural Network block.
Thanks Joeri, but the docs yield no insight on this at all. Which may be my shortcoming, but in any event I still need help. Please let me be more specific:
My training set is five columns wide… timestamp, temp, hum, press, and gas. I would expect, as you describe, that the “raw” pre-processor would simply pass through the four independent columns.
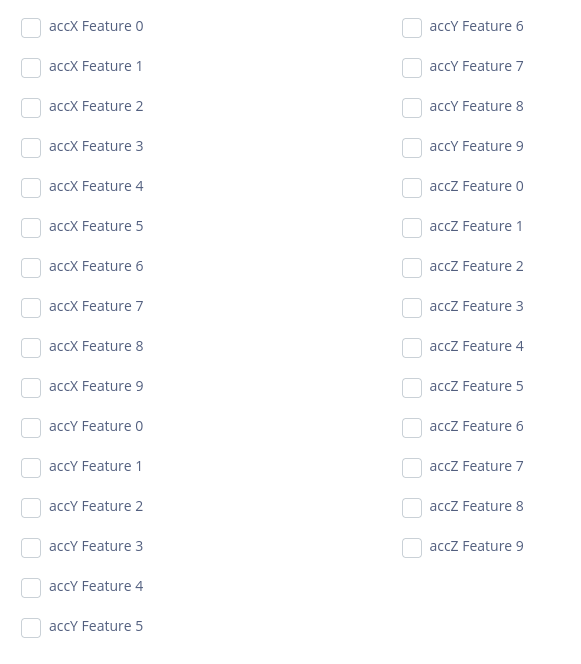
Instead, when I go into the anomaly detection block it offers me twelve features, including “temp Feature 0”, “temp Feature 1”, and “temp Feature 2”. Likewise for hum, press, and gas.
So what I don’t understand, and what the docs don’t seem to tell, is what is the nature of those three features generated for each input?
OK, so I reduced my window size to one seven-second sample, which I’m thinking should reduce the width of the output features… but now the Generate Features function fails:
Scheduling job in cluster...
Job started
Reducing dimensions for visualizations...
ERR: Found array with 0 feature(s) (shape=(2000, 0)) while a minimum of 1 is required.
Application exited with code 1
Job failed (see above)
Would be helpful, I think, if the error specified which array has zero features.
My aim here is to see what I can learn about my raw data before venturing into derived features.
What is your frequency and what is your new window size?
Indeed the error is not super clear, I will create an internal ticket to see how we can improve that.
My frequency is 0.14286 Hz, window is now 28000 ms, increase is 7000 ms.
I’ve run into more than a few unchecked and unexplained Python errors as I’ve been experimenting. I think most of them have to do with dimensionality issues, which I’m thinking might be worth trapping.
I can see that you have only one data sample in your dataset, could you try to split your unique long data sample to several small ones? And make sure they all have the same frequency, you can see the frequency by expanding the data acquisition view, a tooltip will appear when leaving your mouse on the axis:
Right, @louis… What I expect you’re seeing is one-third of my first-round dataset. All the data is sampled every seven seconds, which is 0.142 Hz. Each segment of my dataset is about 45K records… what do you think would be a more amenable set-size? Thanks!
If you are supposed to have a 0.142 Hz frequency, what has been uploaded to the studio shows 0.137 Hz. Can you make sure you don’t have empty “rows” or any missing data? That might explain the ERR: Found array with 0 feature(s).
You can try to split your data sample into smaller files (like 30 min or 1h) instead of one file of 88h.
It might be also easier to spot where you have missing “rows”.


 If you are supposed to have a 0.142 Hz frequency, what has been uploaded to the studio shows 0.137 Hz. Can you make sure you don’t have empty “rows” or any missing data? That might explain the
If you are supposed to have a 0.142 Hz frequency, what has been uploaded to the studio shows 0.137 Hz. Can you make sure you don’t have empty “rows” or any missing data? That might explain the