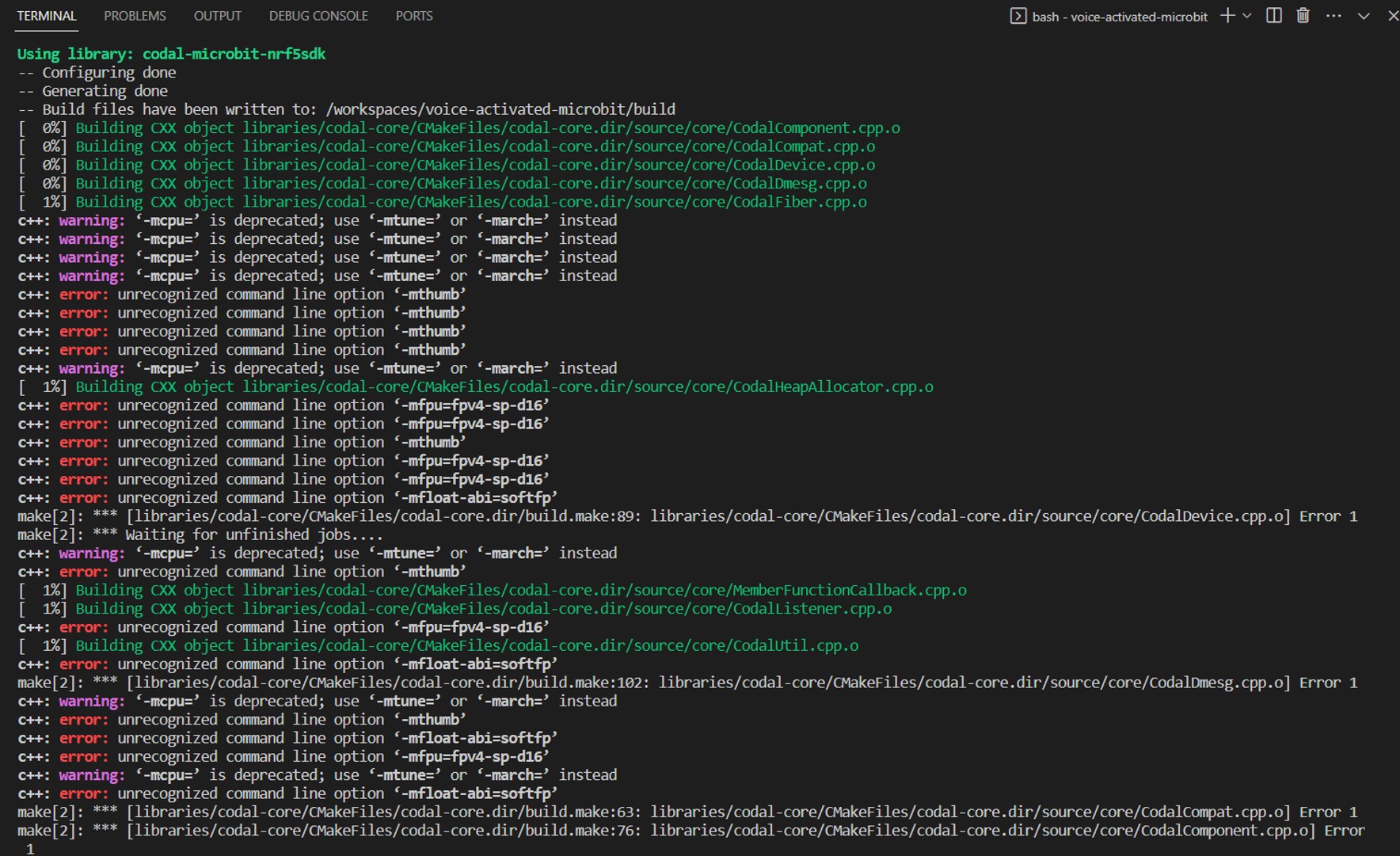
Hi @janjongboom, you did a great tutorial but no one has been able to make it work ! I could compile your code and had a working example, however if I replace your code my the one generated with Edge Impulse studio, it doesn’t recognize the keyword. 100% working with the classification test inside studio. Any idea @janjongboom? I have 1min14 seconds of microbit keyword audio.
Hi @Juph, Apologies for the delay, I am in the EU timezone.
You can view the serial output of the microbit example and see exactly what the model is classifying from the incoming audio data by opening up a serial terminal (like Putty) that your microbit is connected to on your computer to baudrate 115200
@janjongboom Also notes some model troubleshooting steps for improving model performance in the README of this repository, here: https://github.com/edgeimpulse/voice-activated-microbit#poor-performance-due-to-unbalanced-dataset
Hi @jenny,
Effectively, when I say microbit, it classes microbit with 49% of confidence. Where in the code that I can adjust acceptation level lower to see if it works before adding more keyword dataset ? Thanhs for yr support. My time zone is Paris.
Predictions (DSP: 107 ms., Classification: 4 ms.):
microbit: 0.49804
noise: 0.00781
unknown: 0.49414
Now i have 5 minutes of microbit dataset, but it still doesn’t work. I have a warning in the data acquisition section, see below. How to improve it ? Thanks, Julien
Dataset train / test split ratio
×
Training data is used to train your model, and testing data is used to test your model’s accuracy after training. We recommend an approximate 80/20 train/test split ratio for your data for every class (or label) in your dataset, although especially large datasets may require less testing data.
SUGGESTED TRAIN / TEST SPLIT
80% / 20%
Labels in your dataset
Some classes have a poor train/test split ratio: microbit, noise, unknown. To fix this, add or move samples to the training or testing data.
MICROBIT
97% / 3% (5m 4s / 10s)
NOISE
100% / 0% (15m 48s / 0s)
UNKNOWN
100% / 0% (15m 42s / 0s)
Perform train / test split
Use this option to rebalance your data, automatically splitting items between training and testing datasets. Warning: this action cannot be undone.
Perform train / test split
Dismiss
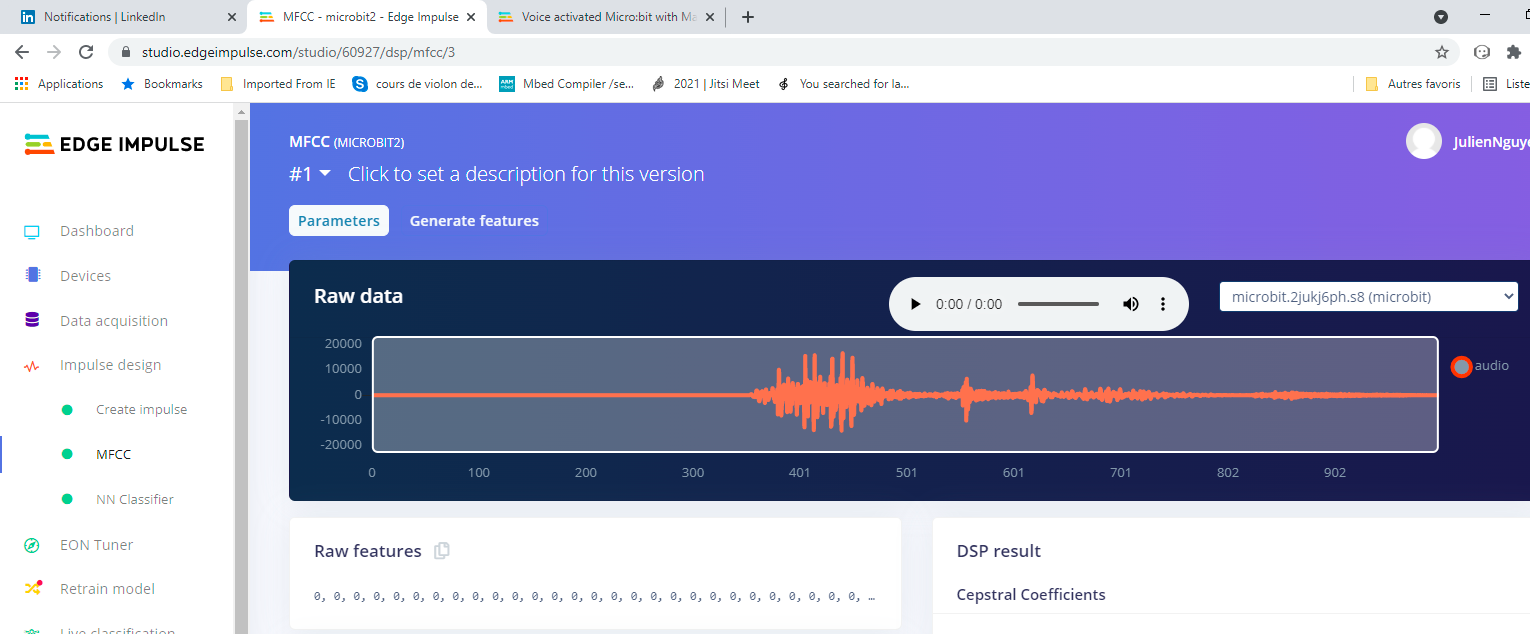
Do you have any idea why my audio data has Raw features always 0, 0, 0, 0, 0, … I m using the microphone from Samsung A50. I can hear the sound but raw features = 0, 0, 0, 0, 0, 0. I think it is the reason why the audio classification doesn’t work at the end on the micro:bit ? Thanks
Hi @Juph,
For better visibility, for future posts can you please create a new topic on our forum? https://forum.edgeimpulse.com/
Your audio sample’s first few raw features are 0,0,0,0… because the sample you have selected doesn’t have any audio until around the 350 time mark.
To copy the entire raw features array, click on the “copy” icon next to the “Raw features” heading.
Jenny
hi, i am using the steps for a project. I keep getting this error the cmake is not found but I have installed it please help
Hi @janjongboom,
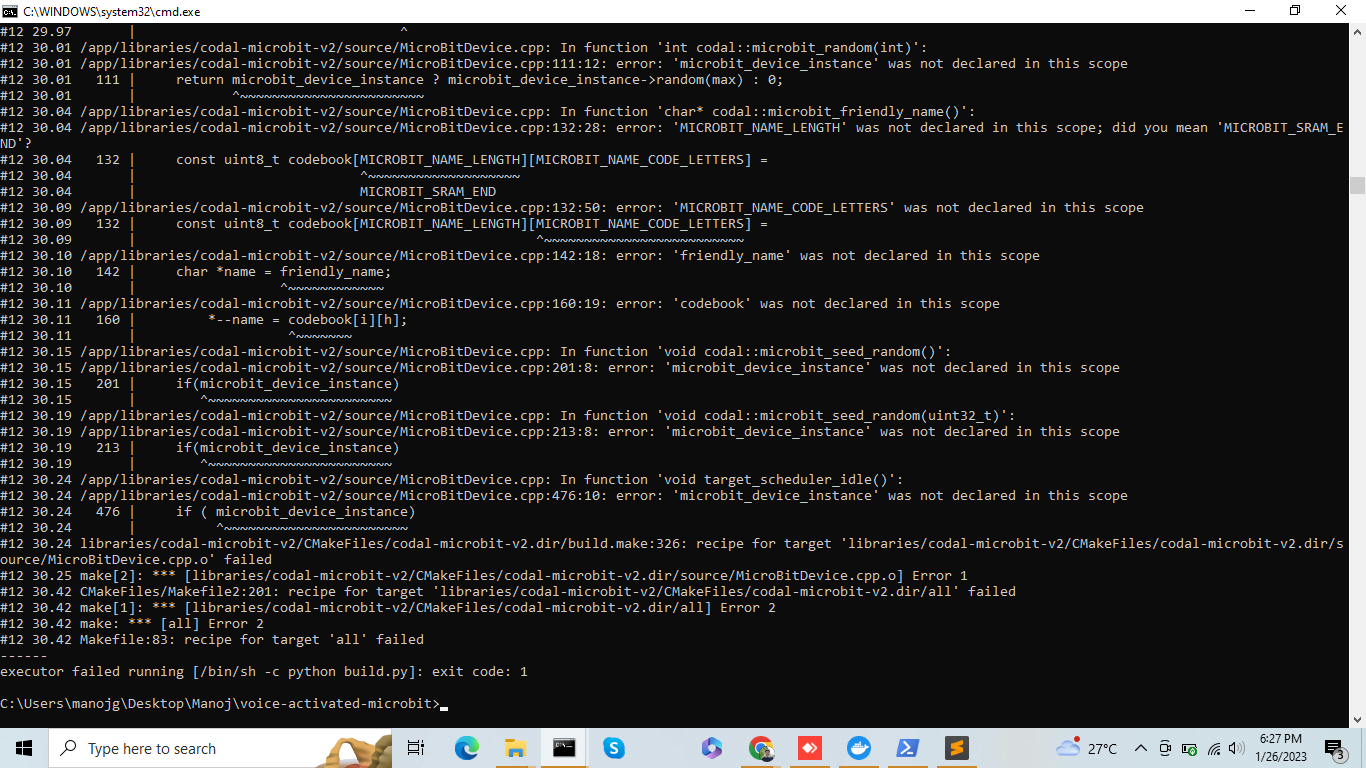
This is great. I’m learning a lot and having fun with this project. I am, however, getting an error when following the Docker build instructions (see Feb 13 reply). The error seems to occur on the “RUN python build.py” step - executor failed running [/bin/sh -c python build.py]: exit code: 1. I am using a MacMini with M1 processor. Details are below. I would appreciate any advice. Thanks!

Hello! I am loving this project as I had a microbit v2 lying around already.
I also get the error message when I try to compile on my windows machine. Any ideas how I can fix this? I downloaded ninja and added the folder it is located in, in my windows env path. Also installed python 2.7, latest c-make and the version 9 of the arm tools.
Here is my error message:
C:\data\voice-activated-microbit>python build.py
codal-microbit-v2 is already installed
Set target: codal-microbit-v2
Using target.json (dev version)
Targeting codal-microbit-v2
CMake Error: CMake was unable to find a build program corresponding to “Ninja”. CMAKE_MAKE_PROGRAM is not set. You probably need to select a different build tool.
– Configuring incomplete, errors occurred!
See also “C:/data/voice-activated-microbit/build/CMakeFiles/CMakeOutput.log”.
I am not a programmer, Im a design student, but I do know a bit about computers. So anything you can do to help will be very much appreciated! Thank you 
Tried to install docker, but my laptop doesnt have virtualization enabled and I couldnt figure it out unfortunately.
Cheers, and thanks/J
Hi @Instant_exit,
It looks like you are running the docker build command from the C:\WINDOWS\system32 directory rather than from the C:/data/voice-activated-microbit/ directory
1 Like
Hooray! I managed to get it compiled with your help Jenny.
Im having some problem with it triggering correctly to my keyword though. Maybe I need more/better data? I collected about 5 minutes from 8 different persons. It is definately ”sort of” working though, listening in on its surroundings.
In the youtube tutorial it was stated that you could control things with the microbit using voice activation. I tried for a long time to find resources on how, but I am a bit lost. How could I for instance modify the code so that I can control a relay using one of the output pins?
Say: pin changes state+ a timer for n seconds when microbit recognizes the key word?
I would be very happy if someone could point me in the right direction ! Thanks/J
Still searching. Is this the resource I need to make changes in the code so I can control output pins? https://lancaster-university.github.io/microbit-docs/ubit/io/
for instance (not at all sure if this is correct?)
uBit.io.P0.setDigitalValue(1);
uBit.sleep(1000);
uBit.io.P0.setDigitalValue(0)
Also, Is there a way to control microphone gain for the voice activation?
Also still havenr been able to make the word trigger reliably. Im using the word ”data” is there better success with different phonems or wordlenghts etc, or doesnt it matter much?
Thanks,
J
Hi again, im sorry to ask so many questions  but im still having issues, even after reading up on the subject of voice recognition on your webpage. I added a lot more data, recorded about 18 minutes of me and my friends saying the word “DATA” in swedish, and also more of the unknown audio class in case it would help.
but im still having issues, even after reading up on the subject of voice recognition on your webpage. I added a lot more data, recorded about 18 minutes of me and my friends saying the word “DATA” in swedish, and also more of the unknown audio class in case it would help.
The model works fine on the website and If i record test data it classifies correctly over 90% of the time, but not on the microbit.
It sometimes triggers, but most of the times not. Maybe one in four works. I feel like an idiot talking to a microbit that doesnt respond 
I tried following the advice to disable moving average like @janjongboom wrote above.
Still no success. Any ideas? Add even more data? Change the keyword? I tried increasing the learning cycles in 100 increments to see if that would make any meaningful difference. I also tried changing the distance to the mic, and changing rooms, power supply (in case there is noise bleeding into the unit from usb power).
Any ideas or tips on how to make this work better would be greatly appreciated. Or am I expecting too much from a microbit? I could of course try another hardware platform, I just happen to have a microbit on hand.
Thank you/Jonas
I got it to work! I did not realize it but my changes werent being compiled. I cloned the project into a new folder, added my files, then built with docker (instead of just overwriting my files in the original folder), and now it is much much better at recognizing my keyword. Now I just need to learn how to write pwm to servos and to control a relay for my projects. I should be fairly simple, right?
Is the microbit limited to just one keyword, or can you in theory do two?
cheers,Jonas
Hey community! I keep getting an error message after trying for a long time. I installed the correct GNU ARM I think. Is there a solution for this?
Thanks very much!
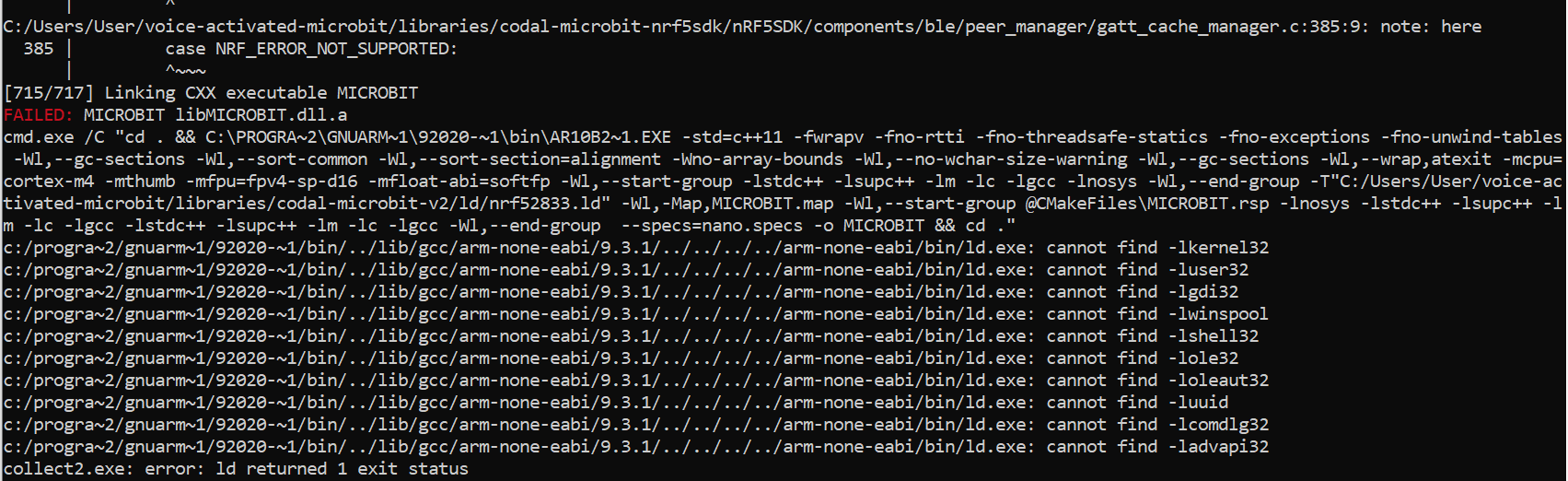
Addendum: I tried to create the hex file with Docker on my Raspberry. I also get a similar error message. Thanks for the help!
I am trying to compile the github repo with the docker and it was working smoothly on a previous build of Codal_Microbit_V2 from landerbilt, but it suddenly stopped building on a latest built for the codal dependencies.
Can someone please help me with this : - Thanks a lot.
~ Manoj
Hi, an error with a function named ‘getSamplerate()’ keeps occurring. The required dependencies are installed and discoverable i.e., cmake, arm-none-eabi-gcc, and executing build.py on python 2. Is there a solution for this?
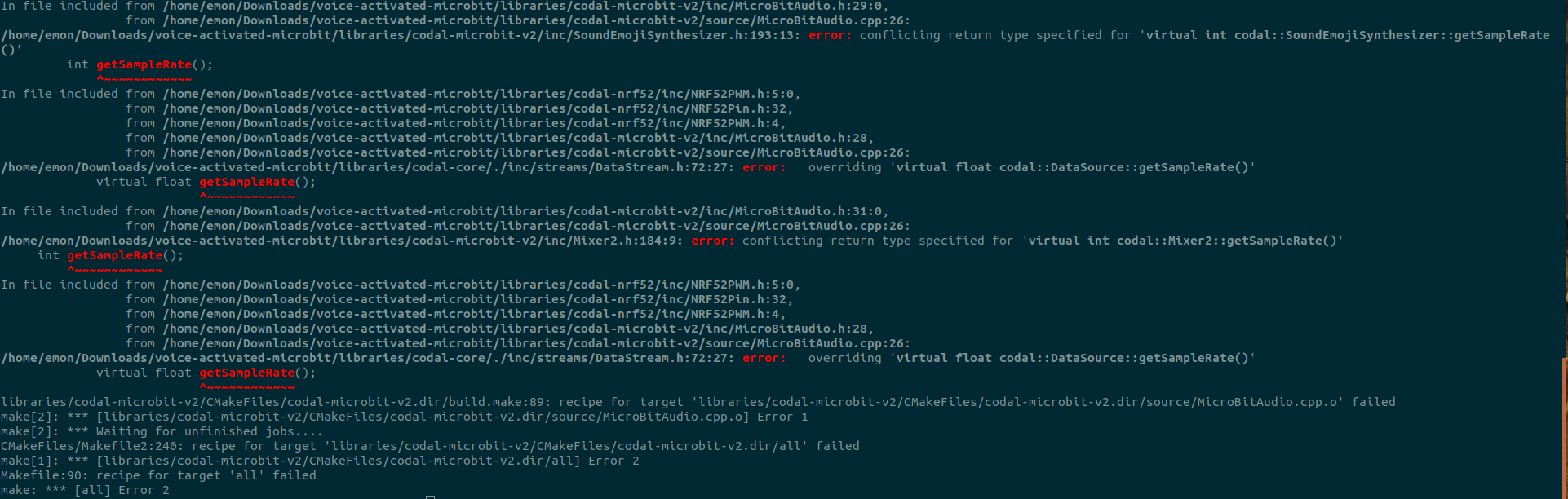
Hello,
Not 100% sure but by reading the issues, it seems that one getSampleRate() is declared to return int values and the other is declared to return float values.
Best,
Louis