Hello EI Team,
I like to notify the following bug?.
(Project ID = 77655)
I had trained a model (yesterday).
Today, I try to retrain the model.
However I obtain the following error:
ValueError: Cannot load file containing pickled data when allow_pickle=False
STEP 1
To only way to solve this (so far I see) is by recalculating the features. What I have done is modify the scaling from 1 to 0.5 => recalculating the features => modify scaling from 0.5 back to 1 => recalculate the features
I was able to retrain the model. However, if I perform model testing and I obtain a complete different result, compared to yesterday. Result model testing:
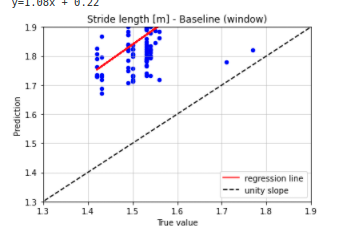
During model testing, I notice the following Not generating new features
Creating job... OK (ID: 2204852)
Generating features for Raw data...
Not generating new features: features already generated and no options or files have changed.
Classifying data for Regression...
Classifying data for float32 model...
Scheduling job in cluster...
Job started
STEP 2
I have done the following steps: scaling from 1 to 0.5 => recalculating the features => modify scaling from 0.5 back to 1 => recalculating the features. Retrain the model and perform model testing. And I obtain:
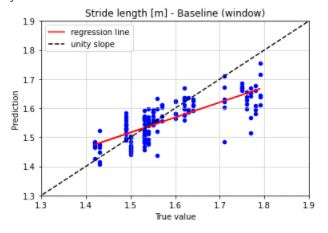
Same as yesterday!
I have some doubt about the selected features (training vs. model testing).
- If I recalculating the features, does it only recalculate the features for only the training set?
- Is it possible, during step 1, that different features are selected, during training and model testing. For example during training the features scale 1 but during testing still these of scale 0.5.
I also provide you the Traceback for the ValueError
Creating job... OK (ID: 2204586)
Job started
Splitting data into training and validation sets...
Traceback (most recent call last):
File "/home/train.py", line 364, in <module>
main_function()
File "/home/train.py", line 148, in main_function
X_train, X_test, Y_train, Y_test, X_train_raw = ei_tensorflow.training.split_and_shuffle_data(
File "/app/./resources/libraries/ei_tensorflow/training.py", line 74, in split_and_shuffle_data
Y = np.load(os.path.join(dir_path, y_train_path), mmap_mode='r')[:,0]
File "/app/keras/.venv/lib/python3.8/site-packages/numpy/lib/npyio.py", line 445, in load
raise ValueError("Cannot load file containing pickled data "
ValueError: Cannot load file containing pickled data when allow_pickle=False
Application exited with code 1 (Error)
Job failed (see above)
Regards,
Joeri