Hello.
I’m a novice in ML field and particulary in Edge Impulse so my question may seem stupid, sorry. I tried to find related topics here but looks like I’m the only who faced such problem.
I have successfully built the model for the custom type of sensors. Reported memory estimation is pretty good for me, however when I deloyed model on the real HW I found out that the real RAM usage is much bigger than expected. Below the details.
Expected memory usage as follow:
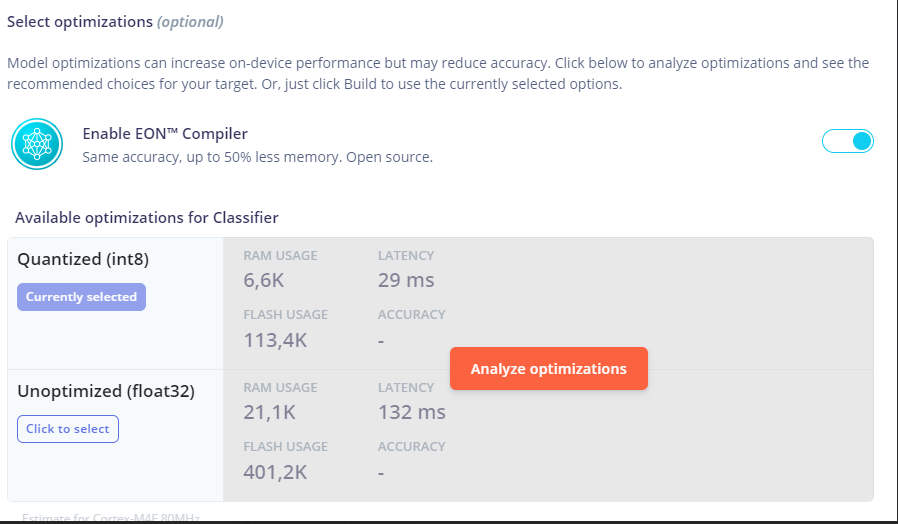
Attempting to run the model by run_classifier() function invocation fails with an error:
ERR: Failed to run DSP process (-1002)
run_classifier returned: -5
I dig deeper and found that error relates to insufficient memory, so I set beakpoint on memory allocation function call:
__attribute__((weak)) void *ei_calloc(size_t nitems, size_t size) {
/* ei_printf("Callocing-ing %u\n", nitems * size); */
return calloc(nitems, size);
}
Appeared that classifier two times tries to allocate 19864 bytes of memory which is too much, I don’t have enough RAM in system (nRF52832 SoC with BLE enabled).
Can anyone explain why this happened and what I did wrong? Any help is appreciated!
Another one question is about memory optimization. According to the picture above model is optimized for using int8 data type, however I did not found where I can provide data in int8 or int16. Standard callback which fetches data from user buffer accepts only float32, so I have to cast int16 to float32 which definetely affects memory footprint,
Thanks!