Listening on host 0.0.0.0 port 4446
Failed to handle request Object of type ndarray is not JSON serializable Traceback (most recent call last):
File “dsp-server.py”, line 134, in do_POST
single_req(self, generate_features, body)
File “dsp-server.py”, line 43, in single_req
body = json.dumps(processed)
File “/usr/lib/python3.8/json/init.py”, line 231, in dumps
return _default_encoder.encode(obj)
File “/usr/lib/python3.8/json/encoder.py”, line 199, in encode
chunks = self.iterencode(o, _one_shot=True)
File “/usr/lib/python3.8/json/encoder.py”, line 257, in iterencode
return _iterencode(o, 0)
File “/usr/lib/python3.8/json/encoder.py”, line 179, in default
raise TypeError(f’Object of type {o.class.name} ’
TypeError: Object of type ndarray is not JSON serializable
Failed to handle request Object of type ndarray is not JSON serializable Traceback (most recent call last):
File “dsp-server.py”, line 134, in do_POST
single_req(self, generate_features, body)
File “dsp-server.py”, line 43, in single_req
body = json.dumps(processed)
File “/usr/lib/python3.8/json/init.py”, line 231, in dumps
return _default_encoder.encode(obj)
File “/usr/lib/python3.8/json/encoder.py”, line 199, in encode
chunks = self.iterencode(o, _one_shot=True)
File “/usr/lib/python3.8/json/encoder.py”, line 257, in iterencode
return _iterencode(o, 0)
File “/usr/lib/python3.8/json/encoder.py”, line 179, in default
raise TypeError(f’Object of type {o.class.name} ’
TypeError: Object of type ndarray is not JSON serializable
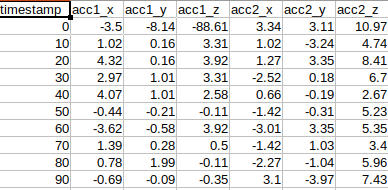
got this error when creating a custom DSP, what could be the issue? @louis
import numpy as np
def generate_features(implementation_version, draw_graphs, raw_data, axes, sampling_freq, scale_axes):
# features is a 1D array, reshape so we have a matrix
raw_data = raw_data.reshape(int(len(raw_data) / len(axes)), len(axes))
features = []
labels = []
graphs = []
an_array=[]
# split out the data from all axes
for ax in range(0, len(axes)):
X = []
for ix in range(0, raw_data.shape[0]):
X.append(float(raw_data[ix][ax]))
# X now contains only the current axis
fx = np.array(X)
# process the signal here
fx = fx * scale_axes
an_array.append(fx)
features.append(np.correlate(an_array[2],an_array[3]))
features.extend(np.correlate(an_array[1],an_array[2]))
features.extend(np.correlate(an_array[1],an_array[3]))
labels.append('Correlation')
return {
'features': features,
'graphs': [],
'labels': labels,
'output_config': { 'type': 'flat', 'shape': { 'width': len(features) } }
}
if __name__ == "__main__":
parser = argparse.ArgumentParser(description='Flatten script for raw data')
parser.add_argument('--features', type=str, required=True,
help='Axis data as a flattened array of x,y,z (pass as comma separated values)')
parser.add_argument('--axes', type=str, required=True,
help='Names of the axis (pass as comma separated values)')
parser.add_argument('--frequency', type=float, required=True,
help='Frequency in hz')
parser.add_argument('--scale-axes', type=float, default=1,
help='scale axes (multiplies by this number, default: 1)')
args = parser.parse_args()
raw_features = np.array([float(item.strip()) for item in args.features.split(',')])
raw_axes = args.axes.split(',')
try:
processed = generate_features(1, args.draw_graphs, raw_features, raw_axes, args.frequency, args.scale_axes)
print('Begin output')
print(json.dumps(processed))
print('End output')
except Exception as e:
print(e, file=sys.stderr)
exit(1)
Files in my dsp.py are this. i am trying to compute correlation between two axis Y and Z from an accelerometer. the other files i downloaded from the github example of custom dsp block are unchanged kindly help
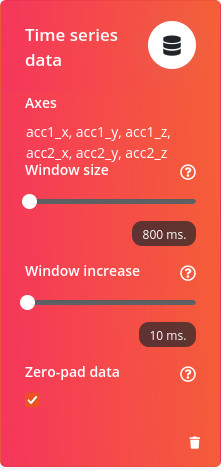
i have this data, its not motion rather key presses, say one key press takes 90ms, i found a research saying computed correlation between y1 and y2 and z1 and z1 served as useful features for the multilayered ML. now i want to do that with edge impulse. i gain separation of features for classes with a higher sampling rate but that is inefficient, one key press lasts only 90ms (for example), if i pick my window size to be say 450, i have to feed the same amount of data when i am deploying since inference expects the same number of raw data you used for training
thanks for the additional insight. It should be possible to reduce the window increase size to let’s say 80ms to get more training windows. 80ms is used for our accelerometer demo. If we make the window increase size much larger we see the same result, not enough features.
if i increase window size i gain more features, but i only want to learn from 800ms, but the feature generator is not seeing patterns in data until i iincrease window size, but if if i can increase it and still read data from one observation in my embedded device, then that will be a solution
Yes, I think that would be the idea. You could try a window size of 2000 ms to give it enough “body of work”. I can see a similar thing with our default acc demo if I decrease the window size to 800ms. You could also perhaps try the spectrogram block.
For anyone stumbling onto this: ‘Object of type ndarray is not JSON serializable’ is an error you get when you return a numpy array in the generate_features function rather than a Python array.