Hello all,
I’m trying to classify many keywords to build a speech command interface on STM32. I’ve tried the 1DConv model, training time is about 4s/epoch and the performance is very poor (about 60% accuracy). Therefore I’m trying to increase the model complexity, for example, using the 2DConv.
Is there any way for me to speed up the NN training speed?
The training is a little bit slow (about 18s/epoch) and my computing time is exceeded. The model specifications are as follow:
Project: 20675
DPS: default MFCC
NN:
- number of class: 18
- model: default 2dConv
Thank you!
Hi I’ve upped your compute time limits to 2 hours now 
Is there any way for me to speed up the NN training speed?
For enterprise customers we have GPUs, but it’s a bit too expensive to run it for everyone 
Hi @janjongboom,
I am now being able to train a pretty decent speech model with 13 commands and acc of 83%.
Now I’m having a problem running continuous inference on the device (Project 20675 - STM32l4 Disco board with EI_CLASSIFIER_SLICES_PER_MODEL_WINDOW 3):
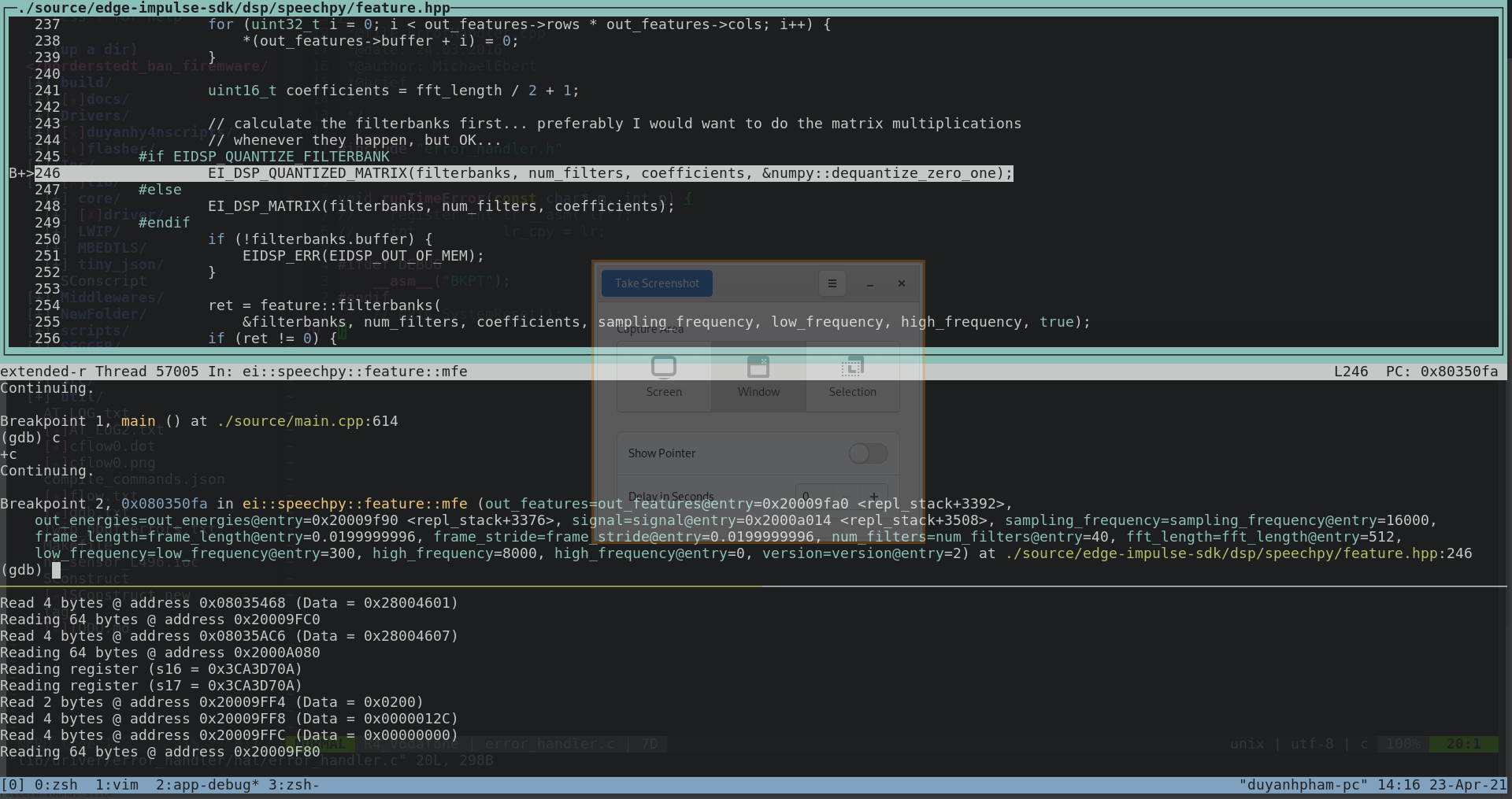
Before that, I have an 18-commands-model with default MFCC features extraction block and it runs just fine. For the new one, I’ve increases the number of MFCC filters up to 40 as well as the FFT length to 512, to improve the feature maps. And this may cause a memory issue ( see the debugging image above).
With EI_CLASSIFIER_SLICES_PER_MODEL_WINDOW 2 it came out with ERR (-8) or EI_IMPULSE_ALLOC_FAILED
My question is, how can I calculate the memory constraint on my device for running CNN inference continuously? Or is there any limit on the MFCC parameters?
Thank you,
Duy Anh
@duyanh-y4n The memory as shown in the MFCC page:
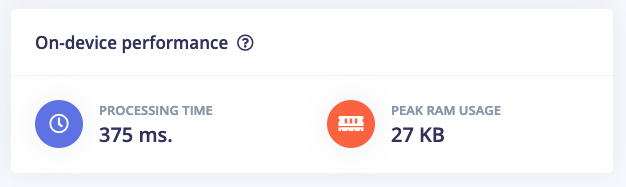
Is a pretty good estimation of peak memory usage in the DSP step, but the continuous classification also adds some extra buffers. How much RAM does your device have? And what’s your frame stride / frame length / window length?