Hi, Question/Issue:
What kind of photos are better to use as data set and label the digits on LCD?
The large photo with everything on the table or the smaller photo with the LCD display only? (see below images)
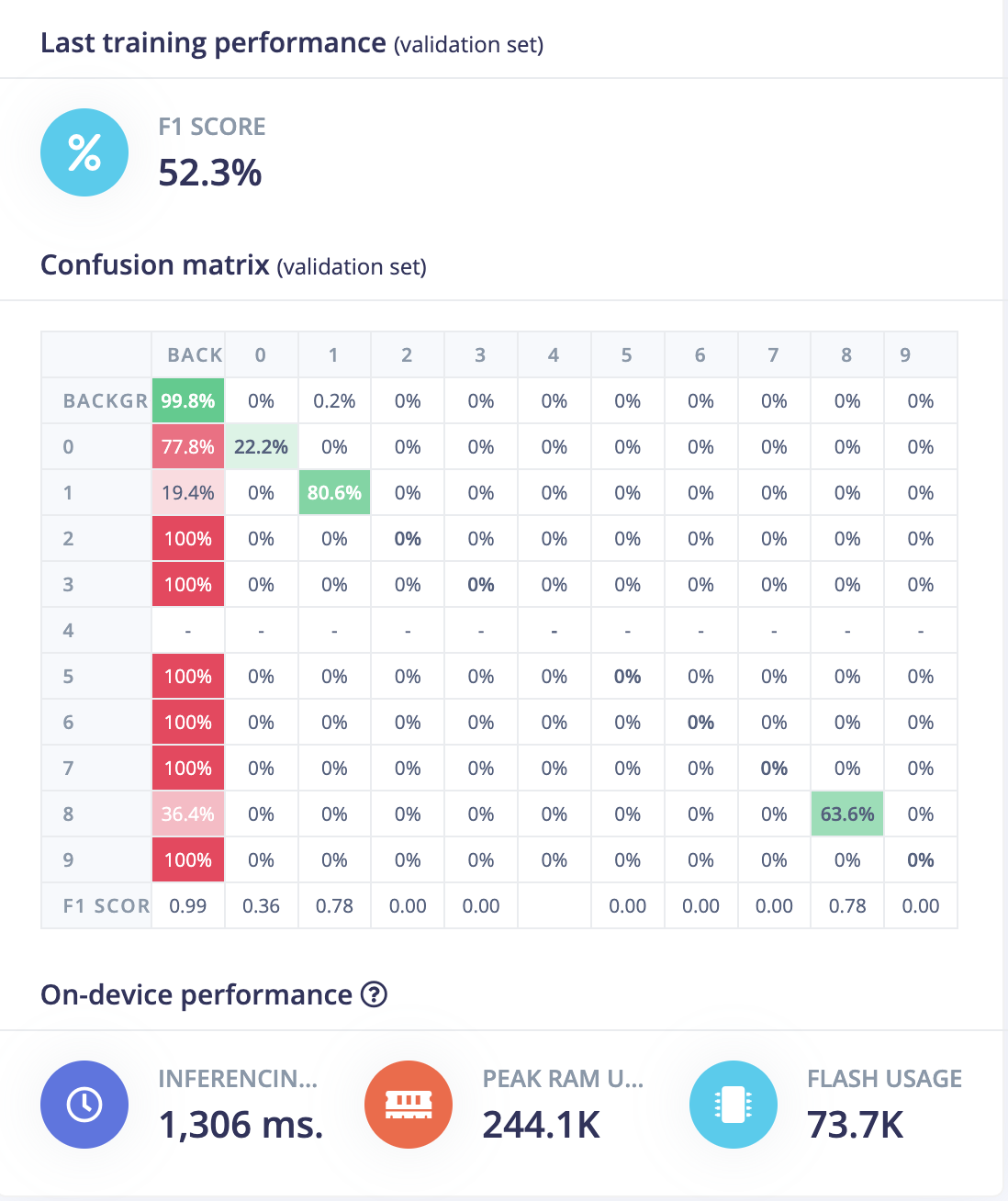
On this project, I’ve tried to upload very large photos and label the digits in the display. So the square region in the entire photo were very small. After the ML process, the results is not useable. (See how I label the numbers in this image)
Context/Use case:
I would like to take a photo of the figures(digits) from a blood pressure machine and then use ML to get readings and send the readings to Google sheets.
The easiest for the ML model would definitely be the second picture. However, this will probably require some pre-processing on the image size to detect the region of interest.
Alternatively, you can “force” the camera to always have a similar view by creating a setup around the blood pressure machine.
I can see in your dataset that some of the samples are not labelled. Make sure to disable them or label them before training your model otherwise, the model will use these pictures to train the “background” class, which will contain your digits. Thus decreasing a lot your model performances.
The best one to use is → you mean the “LCD only” pictures right?
Correct
“probably require some pre-processing on the image size to detect the region of interest.” Do you have an example for me to reference.
I think I remember seeing a video on the OpenMV cam that was doing something similar.
Also, I noticed that your dataset is probably not labelled correctly.
e.g. scene02821_result sample (same as your third picture on your post) is missing label 9, 8 and probably 7 and 3.
If the labels are not set, the model will learn as being a background class.
Hi Lous,
After re-cropping and re-labeling the images, the result still not very good.
How can I improve the ML accuracy? Do I need more images for ML?
Project ID: 188804
Here are the images I uploaded and labeled as well as the ML results for your reference.
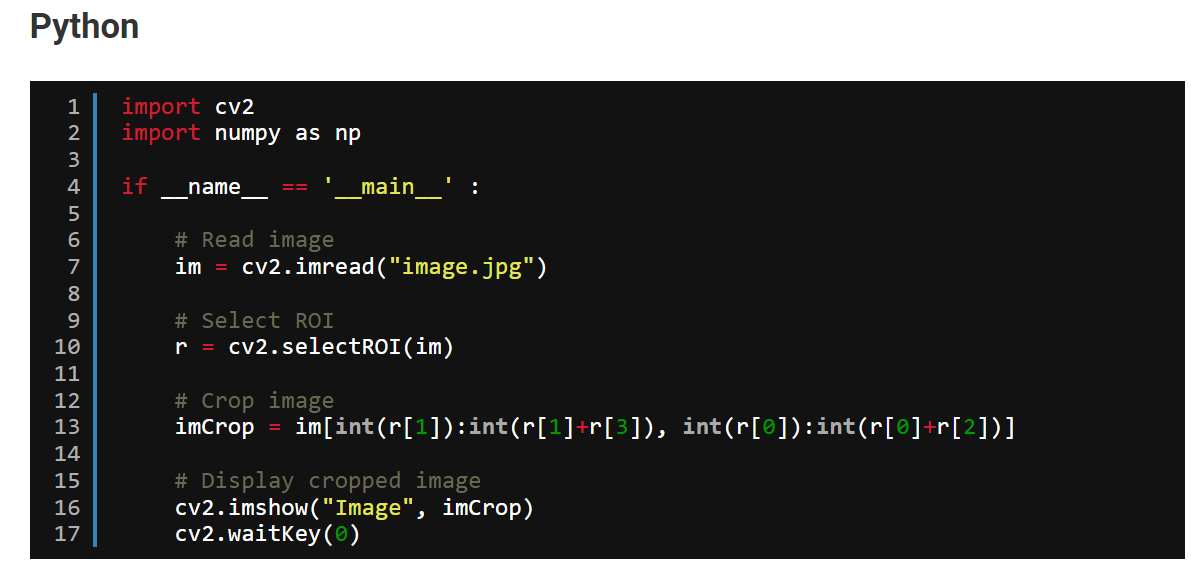
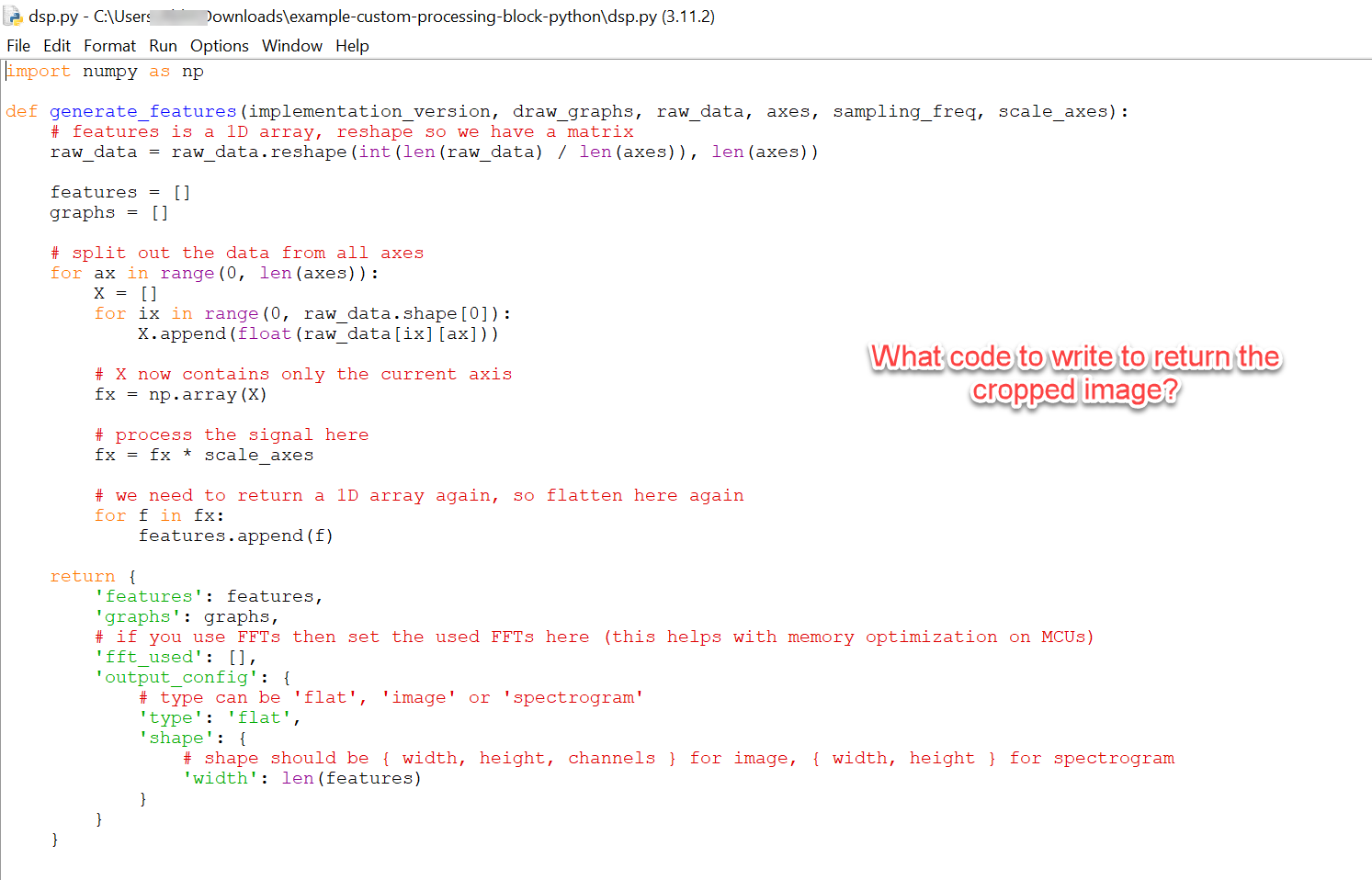
Hi there @Joeri and @louis, I read through this discussion and went through some of the suggested links for the creation of a pre-processing block to define a region of interest. I have a similar issue as @stonez56 that I am struggling with, wherein I have to say if the water is on/off (not so much to read the digits). My initial model was only giving me 66% accuracy. Therefore, I needed to reduce the noise and focus and crop the image to only to the digits. I have tried the examples from GitHub - edgeimpulse/example-custom-processing-block-python: Example of a custom processing block in Python. But I am looking for an example to crop images (or to define roi?).
In OpenCV I know this is possible. Can we do the same in Edge Impulse and if so do you have an example for it? Thanks for your time in advance.
@stonez56 What images you use to train depends on your end goal, aka your production model. If you want to build a generic blood pressure reader then the 1st photo is better. For example, YOLOv7 uses image collages for training because it can help improve the performance of the object detection model. The idea behind image collages is to combine multiple smaller images into a larger single image, which can then be used as input to the model. By doing this, the model is able to learn to detect objects at different scales and locations within a single image. This can help improve the model’s ability to detect small objects, as well as objects that are partially occluded or appear at the edge of an image.
If you are designing a Model for a single blood pressure machine where you can also control the camera then I agree with Louis, that the 2nd photo is better.
@MMarcial Thanks for the reply! A generic blood pressure reader is what I had in mind. I had labeling the data in few different ways and trained few times, but non of them worked.
Can you suggest a good tutorial using YOLOv7 with EdgeImpulse for Blood pressure machine digits readings?
Hello,
Did you manage to do something now? Im also want to reconise multiple number at the same time and continuously. My main concern are if i only need edge impulse or its better to use opence cv in python. The number i want to read are like on 7 segment digit.
Thanks you