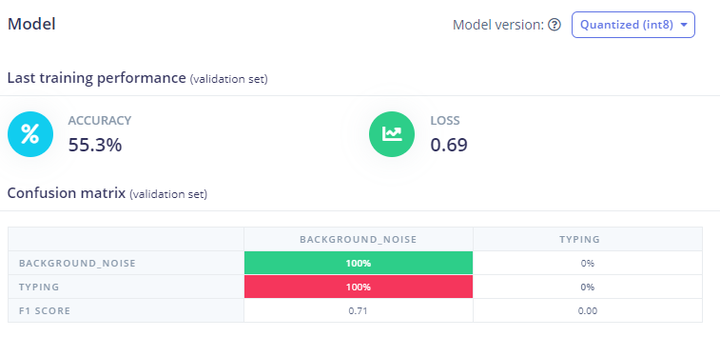
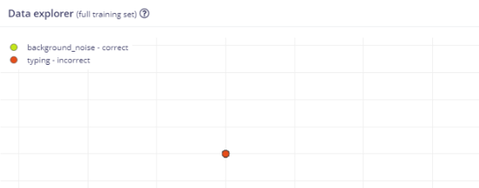
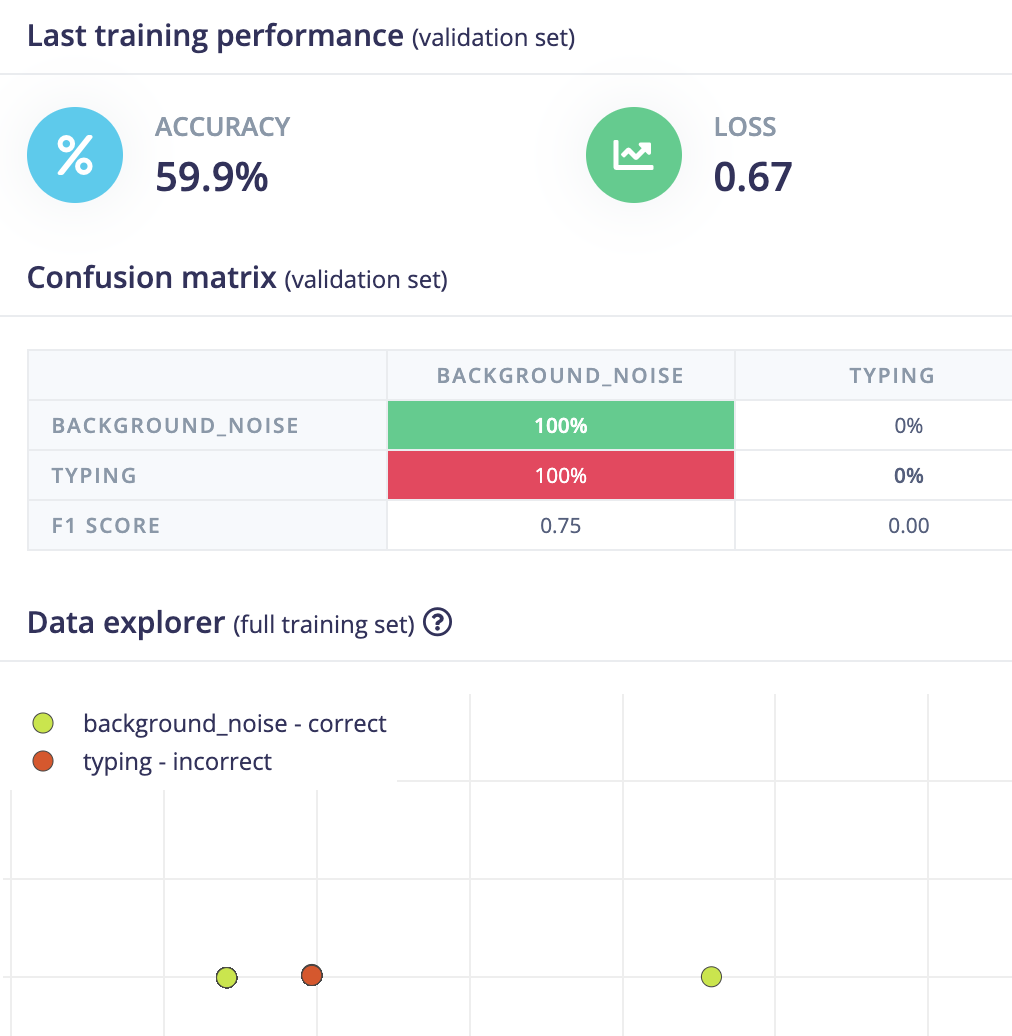
I am currently engaged in the development of audio classification models on Edge Impulse. However, only recently, I have encountered perplexing outcomes during the training process. The confusion matrix of the validation set often displays peculiar results, such as 100% prediction for one class independent of the actual label (see attachment1). Notably, each training iteration (after a few initial steps) consistently yields identical results (some sort of stagnation?) in terms of accuracy and confusion matrix values, without any discernible variation. Moreover, the Data Explorer occasionally exhibits anomalous behavior, indicating a single cluster (data point), which is unusual (no amount of zooming in or out shows any more data points) (see attachment2) .
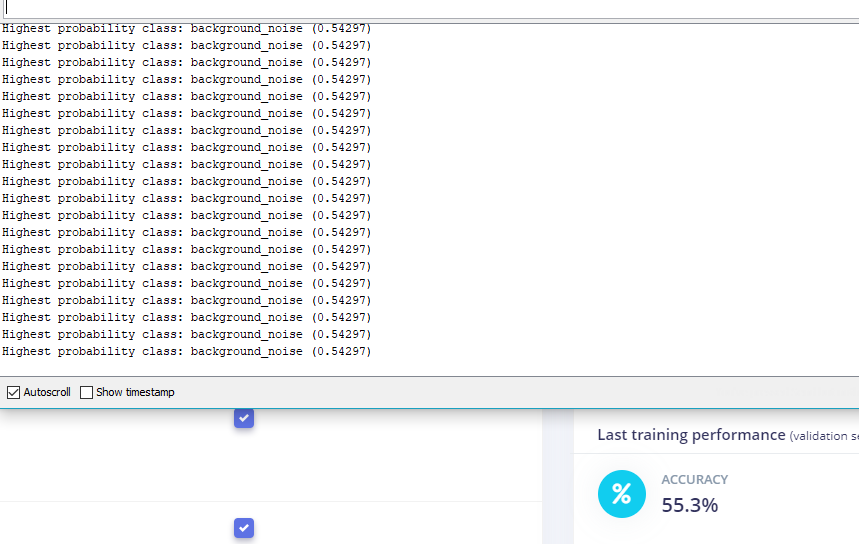
In these ‘strange’ cases the serial monitor shows an output prediction and probability the same each time (e.g., sound_class1 with probability 0.55). This may be a useful piece of information. The result is always the same which could explain the issue with the training and stagnation, possibly pointing at model generation/training as the issue point?
I have observed that it seems(!) to be the case that modifying specific variables, e.g., “validation set size” or “Data augmentation” can sometimes(!) resolve the issue (e.g., validation set size from 20% to 30% and then it is fine, in some cases).
This trend has persisted for the past week (max two) only. I am curious to know if this behaviour may be attributed to the account license type / number of projects / some major user error etc or if there have been updates to the backend functionality of Edge Impulse that could potentially be causing these issues.
Your insights into this matter would be greatly appreciated. Thank you!