I apologize for being dense but where is the ino file you mention located?
ok I think I found it, you are referring to the samples folder in the zip file downloaded from EdgeImpulse. I’ll explore it. I think I did before but I’ll give it another go because it seems to work for you.
Can you tell me your sample rate? Mine is 96000 and the esp32_microphone. needs sizeof(int16) times that in a malloc call. My esp32 does not have enough memory for that. I have tried the esp_32_microphone_continuous which only needs a short instead of the int16 and it builds and runs fine but the INMP441 still seems to be giving it garbage.
Thanks
My board can only work at maximum
52,920 sample rate.
window size 1200ms ; window increase 200ms
esp32_microphone.ino also use only this. the continuous example always overflows and cant run on my board.
(Don’t exceed this setup)
also before you upload the code,
at the end of the loop ( void loop argument) put a delay of at least 2 sec .
so it the board will have enough time to process the audio without overflowing.
once you have successfully run the model you can play the parameters in Edge Impulse.
You also use 2 processing block and 1 learning block in a single Edge Impulse model.
note that 2 build this more than 2 processing block, you will need to use the free trial offered by Edge Impulse, since building model in free mode has a max time of around 20mins.
if you need help in parameters that work on MFCC I can give you so can run model to your board
For MFCC Parameter you can use this as a guide
Number of coefficients
13
Frame length
0.025
Frame stride
0.02
Filter number
32
FFT length
2048 ( decrease this by dividing by 2 if too much )
Normalization window size
151
Low frequency
400
High frequency
Not set
Pre-emphasis
Coefficient 0.98
this parameter may have exceed the job limit of 20min.
Enterprise plan have no Job limit time.
If you want to be able to have access to enterprise plan of edge impulse you can do this
use a temporary domain email, you can get 1 at wix.com. just create account there and proceed in the creation and generate a website after that, you get the temporary email provided by wix and you can use it at Edge Impulse to have access to Enterprise Plan ( 14 day trial )
You can also refer to this thread I created where I experimented on my own at first while figuring things out with Edge Impulse.
“ESP32 INMP441 Stuck at microphone_inference_record(); – No Error, No Data Received”
Thank you so much with this information. I have successfully got the INMP441 working now. I find that the continuous one works better for me. Where I am at now is trying to figure out how to make my impulse better. Here is my current jamb and maybe you have and idea. I have a 14 word set I’m trying to deal with. 5 of those words are in the Google voice library which has 3 thousand or more wave files for each. These words are working pretty well for my application. The other 9 I’ve had to create using my phone and my wife and I saying them. I only have about 40 files for each. Needless to say these are not being hit very well at all. Do you have any suggestions? Is my problem just the file count causing problems or is there some setting that I need to set when I make my impulse?
Again thank you for your ideas. I’m glad you “forced” me to use an Arduino IDE library approach to my coding. I’ll get that transferred over to platformio once I’m confident I’ve got a working soution.
increasing the accuracy?
On my latest experiment on increasing the edge impulse’s model,
I tried to use 2 processing blocks (MFE and MFCC) and 1 learning block ( classifier)
after tinkering on each o their parameters I successfully increase the accuracy from 60 to 85% in actual testing. this method will require you to have enterprise (I recommend for free trial) plan or the plus( paid ) plan to train since free user only allows up to 20min to 30 min job limit on Edge Impulse.
for the datasets, I suggest an equal amount(minutes) for each sounds to decrease bias.
also set in the classifier tab ( learning Block) increase the training cycles to 100 or 150 and the decrease learning rate 0.001
on my projects , the sounds I use have less to none background sounds as much as possible too.
OK so now I have an impulse that has 92% accuracy,. My dataset is about 1/.2 of the google speech commands database. I’ve used part of the other commands in google speech as unknowns. I’ve added about 1500 noise data clips as well. So yes my dataset is huge and I’ve taken your advice and got a 14-day enterprise account so I can process it. I have played around with the impulse settings to get the accuracy up to 92% so I think I’ve done as well there as I can.
My problem now is this. When I test it with my phone’s speaker the impulse works almost perfectly. I get nearly 1.0 values on all of the 16 commands I have. When I download it to the ESP32 which has the INMP441 microphone it performs very poorly. I can rarely get a hit on several of the commands and others require me saying the command a few times.
So the bottom line here is why is the ESP32 and 441 microphone so bad? Is it just the quality of the microphone? Is it the way data is being collected in the algorithm of the example project esp32_microphone? I’ve not used the continuous example in some time.
I think from my personal experience is that the inmp441 pickup too much noise that affects the classification of audio. you can try to filter that out thru edge impulse to lessen the noise also you can add mic foam to inmp441.
now that you have enterprise try using 2 processing blocks to increase its real-world test accuracy.
I used both MFE and MFCC at same time on my projects and it so far it increases the classification accuracy of my model
Hi, I’m a newbie high school student and I’m also struggling with a similar setup. I’m using an ESP32 Dev Module with an I2S microphone. My problem is that I’m not able to capture sound at a high sample rate.
I’m using the Edge Impulse Data Uploader on my PC, which detects the serial port and sends real-time audio data for data acquisition. But when I try setting the sample rate to 16kHz, the serial output seems to lower it. Then, the real-time data forwarder also reduces it further. In the end, the actual sample rate shown in the data acquisition screen is around 5kHz — not the 16kHz I need.
Because of this lower rate, my model can’t recognize the sounds properly. How did you solve this issue? What method or setup did you use to upload high-frequency audio data? If possible, could you please share your code and explain how you handled the data upload for data acquisition?
I really appreciate any help in advance!
I wished I had an answer for you. I have given up on the project because the quality of the data is just not good enough to get a reliable response. Everything on the edge impulse side works great but the esp32 and it’s microphone falls short.
Hi se732525,
Thank you for taking the time to reply to my question. I appreciate you sharing your experience, even though it wasn’t the answer I was hoping for.
Hi! I also struggled with similar limitations when trying to collect real-time data using an I2S microphone and the ESP32. Capturing clean audio at high sample rates can be tricky due to hardware and serial bandwidth limitations.
Instead of relying on real-time audio acquisition, I used third-party audio conversion software to prepare my dataset. I collected clean audio samples (such as WAV files) with minimal background noise and then manually uploaded them to Edge Impulse for training.
The problem with real-time data is that it often includes too much environmental noise, which can confuse your model and negatively impact accuracy. Using pre-recorded and clean audio clips helped me train the model more effectively.
Unfortunately, the ESP32’s serial bandwidth can’t always handle consistent 16kHz streaming, which explains why you’re seeing a drop to around 5kHz. If high-quality audio is critical to your model, I recommend preparing your dataset separately and uploading it instead of depending on real-time acquisition.
I really was happy with my dataset. I did not use the esp32 to get it. I used the Google speech command dataset. I tested it using my phone’s microphone and it worked great! Where my problem happens is when I downloaded the impulse to my esp32 and then tried to get it to perform with the inmp441 it was terrible. I really suspect the code edge impulse provides for the i2s microphone is just not up to snuff. I’m not an audio expert so I really don’t know how to improve the code.
check the pin configuration on your end. you need to edit that part.
also esp32 have memory alloc limitation take that in mind when training models in edge impulse.
If I remember it correctly its around 52920 raw samples. dont exceed from that point
the result of the accuracy of model in Edge Impulse and in the real word testing is really different.
You need to test and test and test to get the result you want here. no need to modify much on the code. you need to train model non-stop to get result you want on the real world applications
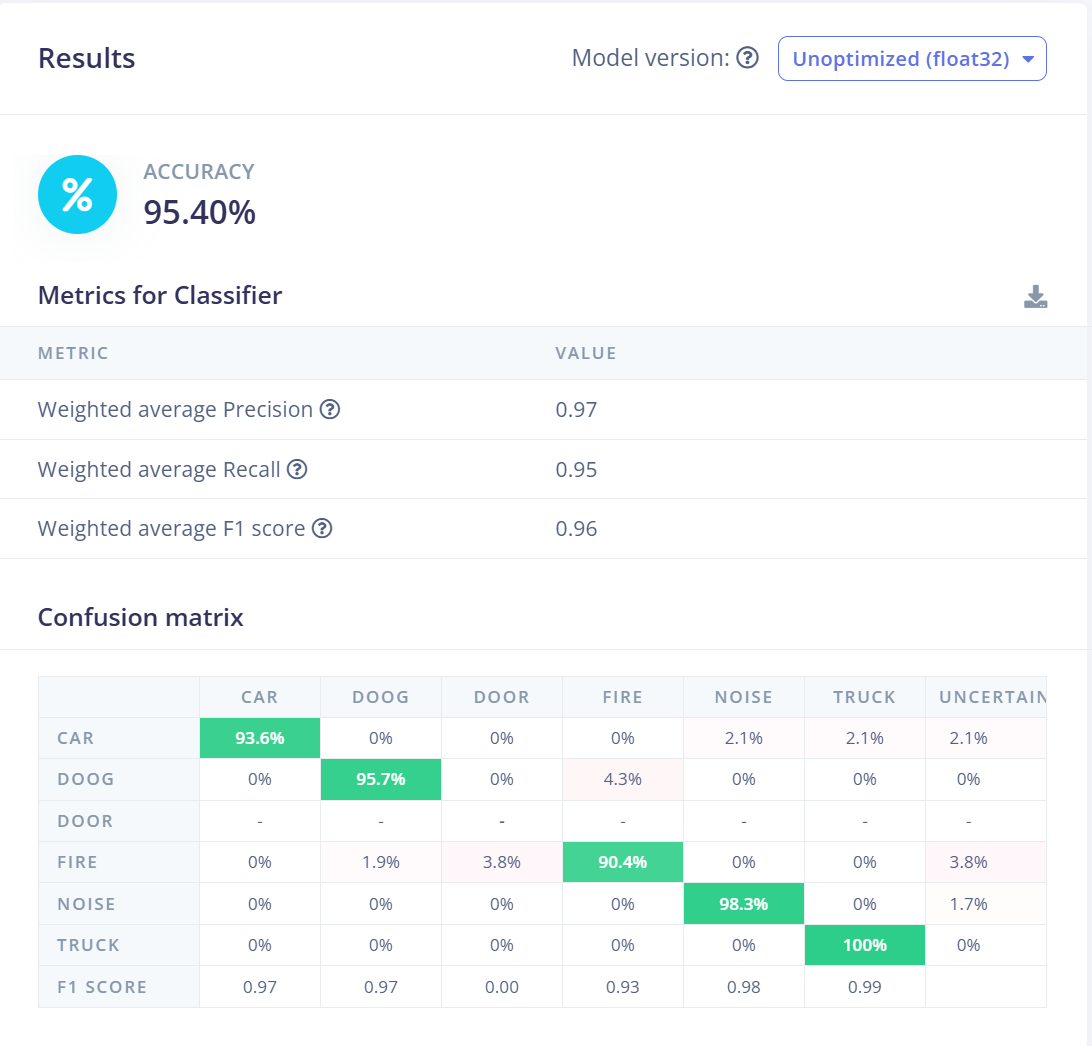
With the 5kHz, I was able to get 95% accuracy in the model testing, But the real time classification was way out. I think my code was not handling the buffer correctly.
use two processing blocks
MFE and MFCC at same time . this increases real world accuracy for me
I did use 2 processing blocks. Again I’ll repeat what I’ve said earlier…I have a great impulse model. When I test it with my phone’s speaker it works flawlessly. It works like crap on my esp32 with its microphone. I seen to be having a hard time making that point.