Hello @aurel
I did that : I have used the python example as a basis, and I have made some progresses
Indeed : The model is correctly downloaded to the RPI4, the example script runs with my image.
But now, I am facing some other issues
The symptom is simple : my image is not classified correctly by the RPI
I use the same image that I use to test my model in the studio.
The model can return “Opened” or “Closed” , depending on my awning (Store banne in French) is closed or open.
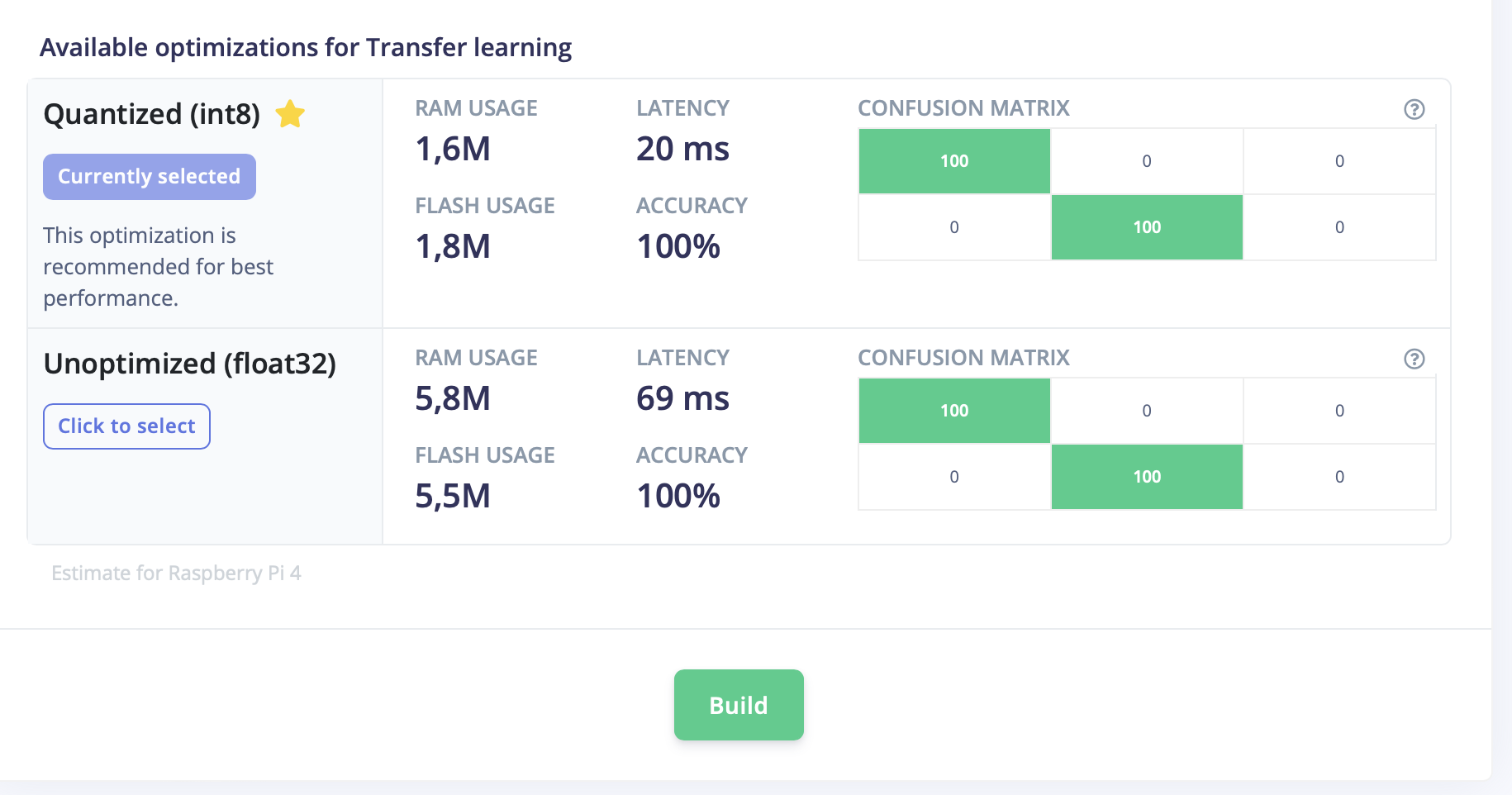
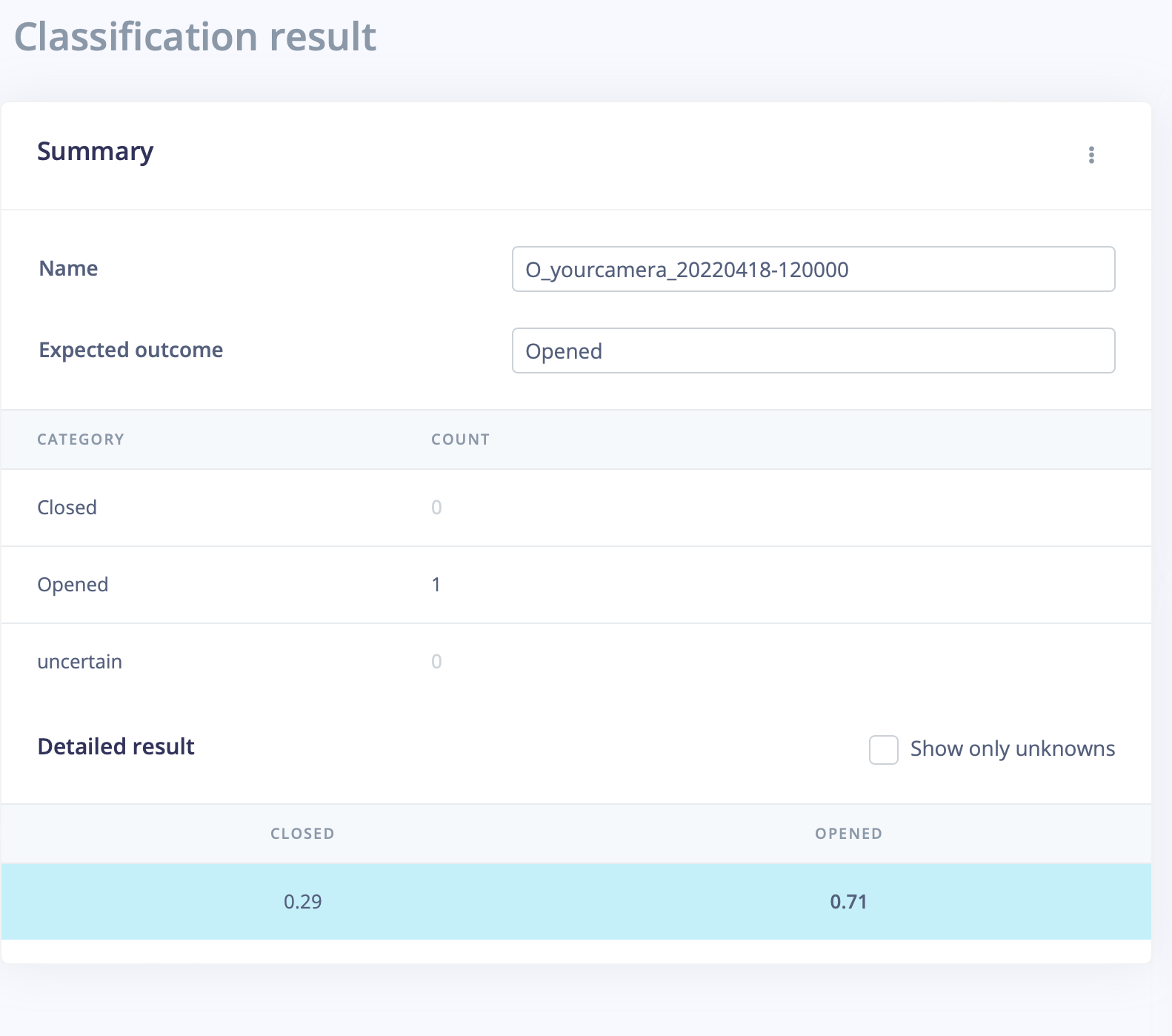
Using studio, I have a very good accuracy, and the test image returns an “Opened” state. But using the RPI, it always returns a Closed State of 100%
So I checked and have seen an issue with the image resizing
In studio, I use the “Letter Box” resize option, to keep the full image even if it has a 16/9 ratio
But this is not implemented in the python SDK
So I have added a python method to resize it the same way
def resize2SquareKeepingAspectRation(img, size, interpolation):
h, w = img.shape[:2]
c = None if len(img.shape) < 3 else img.shape[2]
if h == w: return cv2.resize(img, (size, size), interpolation)
if h > w: dif = h
else: dif = w
x_pos = int((dif - w)/2.)
y_pos = int((dif - h)/2.)
if c is None:
mask = np.zeros((dif, dif), dtype=img.dtype)
mask[y_pos:y_pos+h, x_pos:x_pos+w] = img[:h, :w]
else:
mask = np.zeros((dif, dif, c), dtype=img.dtype)
mask[y_pos:y_pos+h, x_pos:x_pos+w, :] = img[:h, :w, :]
return cv2.resize(mask, (size, size), interpolation)
the method is called in the python script juste before calling
features, cropped = runner.get_features_from_image(img)
Instead, I use
# imread returns images in BGR format, so we need to convert to RGB
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
resized = resize2SquareKeepingAspectRation(img, 160, cv2.INTER_AREA)
# get_features_from_image also takes a crop direction arguments in case you don't have square images
features, cropped = runner.get_features_from_image(resized)
But the result is still the same : Closed at 100%
Do you know what could be the cause here ?
Thanks again for your help
Sylvain