Hi, I have several questions about image classification with different scenarios.
I have uploaded some 320x240 images to EI with a single label for each image (no object detection).
My purpose is to capture images and classify them on Nano 33 BLE sense with a 32x24 camera.
Case 1:
I chose to create a pulse with input size 32x32 and “Fit shortest axis” and trained my model with MobileNetV1 96x96.
I guess the code will expect a 32x32 frame to run the classifier once implemented on the Nano 33, right? So, what should I do?
I can’t “crop” the image to 24x24 (to fit the shortest axis) because the classifier wants 32x32. Right?
So, I should fill 32x8 pixels with something to get a 32x32 image. But with what? Black pixels?
What if I choose “squash” as an option? How should I deal with the pre-processing of the image? Are there functions that allow me to perform squash? Case 2:
Same case as Case 1, but I chose a 96x96 impulse size and the same NN 96x96 model.
With my 32x24 camera frames, do I need to interpolate to get a 96x96 image to provide to the classifier?
Is this done automatically by the library or not?
Are these problems that I should not have to ask myself because the library somehow does all these things automatically or do I have to do them manually? From what I understand, all the blocks created in impulse are transferred to the library.
Actually there is no specific question but many doubts.
I thank those who will help me.
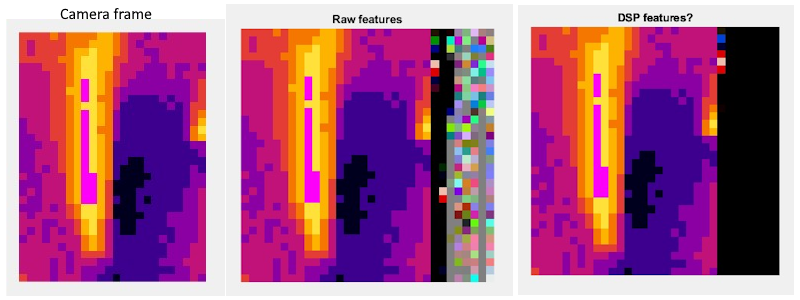
If you look at the image tab under Impulse design, it gives Raw Features and then in the block labeled DSP result which gives the processed features.
You can copy both of these datasets to the clipboardand , if required, paste them into a text editor.
By comparing the two, you can figure out what digital processing Edge Impulse has done with the data before it is fed to the learning block. What ever processing is done here will be performed when the Impulse is deployed to your target hardware.
In my experience, Edge Impulse will downsize larger pictures, but I am not sure if it upsizes pictures.
Squash is an option in the Image data block in the resize mode drop down list.
As expected, it seems that the 32x32 array input of the classifier is filled with my camera frame and the remaining part (32x8) is (almost) filled with black pixels…
I’m wondering if this is correct regarding the model accuracy.(?)
Here is an article that descibes difference between fit and squash
As far as I know, the Image DSP in Edge Impulse fills in black pixels to get a square image. So the image you show of the processed features (32x32) is consistent with what Image DSP does.
Regarding model accuracy, that is a difficult question. Best is to experiment with different configurations. I can suggest some alternative approaches:
In my experience, the Nano 33 BLE does not have enough RAM (limited to 256 K) to run inferencing on RGB images. So best results I have achieved is to convert the images to Greyscale (this reduces the number of input features by a factor of 3).
If you have a large enough dataset, the presence of black pixels in the processed features should not make much difference because the trained network will take these into account. Train a model and see how accurate it is.
My experience shows there are two options for image recognition when it comes to the learning block in impulse design - Transfer Learning (Images) or Classification (Keras Neural Network). Transfer learning offers MobileNet options. Suggest try the MobileNetV1 96x96 0.25 (no final dense layer, 0.1 dropout). V2 networks are beyond the capability of the Nano 33 BLE. Default values for Classification network seem to work OK
If you are ambitious, it may be possible to write your own Image processing block. What you would then do is convert your images to Greyscale, then flatten the image into 32x24 = 768 raw features. Feed this into the Classification neural network and see how this works
Same as above but skip the greyscale conversion. This give 32x24x3 = 2304 raw features.
Sorry @kevinjpower, some things are still not clear to me.
Maybe a stupid question since I’m not an expert in this field but its a real issue for me.
Now I have 240x240 RGB images taken with a “professional” camera and I want to develop an ML model to upload on Portenta H7 (image classification, no object detection). The camera connected to Portenta is 32x32.
My doubts are as follows:
Only at the level of training on EdgeImpulse, what is the correlation between input size of the Impulse and the resolution of the neural network I choose as a model? E.g. Input size 96x96 for Impulse. I reasonably choose MobileNetV2 96x96. But what if I choose 32x32 as input size using the same network? Does the NN automatically scale the image from 32x32 to 96x96? What if I put 240x240 as the input size of the Impulse using the same network?
Looking at using the real 32x32 camera, should I already set 32x32 as input size in the Impulse? What happens if I choose a larger size?
Suppose I have trained and uploaded my model to Portenta and my real frames from the camera are 32x32. This frame should become the same size as my input size in the Impulse. Correct? If the set size was 32x32, no problem. If it was 96x96, however, do I have to interpolate the captured image to feed it to the model first?
Somehow, I think the three questions are connected (or can be connected) but I don’t quite understand how. I guess the real problem is that I don’t understand what to do when I do the training with very high resolution images and then in reality I have very low resolution images.
The questions might be similar to the last time, but I am probably still not convinced of how the different steps work.
The following answers assume you are using the standard features of edge impulse. I think you could do something different if you were prepared to do some level of adjusting the background code yourself.
Standard edge impulse offers only 96x96 or 160x160 MobileNet networks, both of which require an input image of this exact size. I don’t see anyway to alter that in the transfer learning block interface. The way edge impulse handles images of sizes different from 96x96 or 160x160 is in the image block and processing block of the impulse design. These blocks will automatically rescale your images to 96x96 or 160x160 before been presented to the NN. This re-scaling will either be up-scaling or down-scaling dependent on your image data. (so 240x240 will be rescaled to 96x96, if you chose that option, before been input to the NN)
Having said all this, you could probably adjust this in expert mode (three vertical dots on the transfer learning page.
You must set the input size to 96x96 on the image data block in impulse design. The processing block will upscale your 32x32 image to 96x96. There are various algorithms for scaling; I don’t know what specific algorithm is used by edge impulse. A question for their experts.
My understanding is that if you download the code and deploy on your device, it automatically includes a resize function that converts from 32x32 to 96x96 so that it can be fed into the NN. If you suddenly started feeding the model on your device with 96x96 it will not work. So either you have to retrain the model in edge impulse with a new data set or do the low level programming on your device to convert to 32x32.