I am trying to build a model to recognize the sounds of helicopters. When I deploy the model, I seem to be getting a lot of false positives from silence. I think this maybe because the silence gets normalized to be relatively loud, and when normalized the randomness of the silence sort of sound like a helicopter. Is there a way to turn normalization down so that the model is better able to separate quiet sounds from loud ones?
Is this the pre-emphasis setting in the MFCC? Are there settings in the Arduino inference script/lib I should adjust?
I was also going to try turning the gain down for the Mic in the Arduino script, it is set to the max.
It is also very possible my problem lies elsewhere, so let me know if this seem unlikely.
I’m not an audio processing expert, but here are my thoughts. The sound of a helicopter contains regular periodic variations that the sound of “silence” (i.e. background noise) does not. For example, the “chop” of a rotor blade may happen every n milliseconds. The challenge here is to make sure our MFCC output represents these periodic variations in a way that is discernible from background noise.
The first think about is the low-frequency cutoff. By default, this is set to 300Hz. If your helicopter is making sounds below this frequency, they will be filtered out. I’d start by reducing this value and seeing if your results change.
Secondly is the MFCC output’s resolution. The default parameters for the MFCC block have a frame length and frame stride of 0.02 seconds (20ms). This means that each column of the MFCC represents 20ms of sound. If the “chop” of the rotor blades happens faster than every 20ms, it may not be distinguishable from a constant background “hum”.
So, I would perhaps try and increase the resolution of your MFCC output by reducing the frame length and frame stride. This might result in a an output that can be more easily distinguished from background noise. Of course, the larger MFCC output will require more memory and compute, but you could maybe get away with reducing the overall length of the window if this is a problem.
You are much more of an audio expert than me.That makes a lot of sense, I am going to give that a try. I did try experimenting with sending in normalized vs the audio I am capturing right off the Arduino board (which is very quiet) and the MFCC process does not seem to be impacting by the volume levels of the samples you are training on. I will post back on how it goes.
UI Feedback - having the Spectragams update as you adjust the MFCC parameters has been super helpful. It only seems to work on Chrome though, it isn’t working for me on Safari. It would be super awesome to get some sort of memory/compute feedback too as you adjust parameters.
I am still tilting at this windmill. I have tried using both MFCC and Spectrogram feature extractors. I can train a network that gets about 90% val accuracy and about 85% accuracy in testing.
However, I get very erratic results in the real world. When there is a normal volume noise nearby, it does a great job of determining whether it is a helicopter or not. When there isn’t much sound, the predictions start jumping around like crazy. For the same ambient background noise it will go from 90% no helicopter, to 90% helicopter and every prediction in between. I have tried recording the silence and adding it to the no helicopter class.
I have added a loop to go through the samples in the inference buffer to find the Max/Min, and this only happens when those are low (close to zero). Could this be because the normalize() function is amplifying the silence, which is probably just the noise in the Mic A/D? Maybe this random noise can end up looking like high frequency noise source like a helicopter after feature extraction?
Is there a clean way to add a noise floor threshold? I could just add something to the Arduino program, where if none of the samples go above a threshold, don’t bother running inference on it because it is too quiet to be discernable.
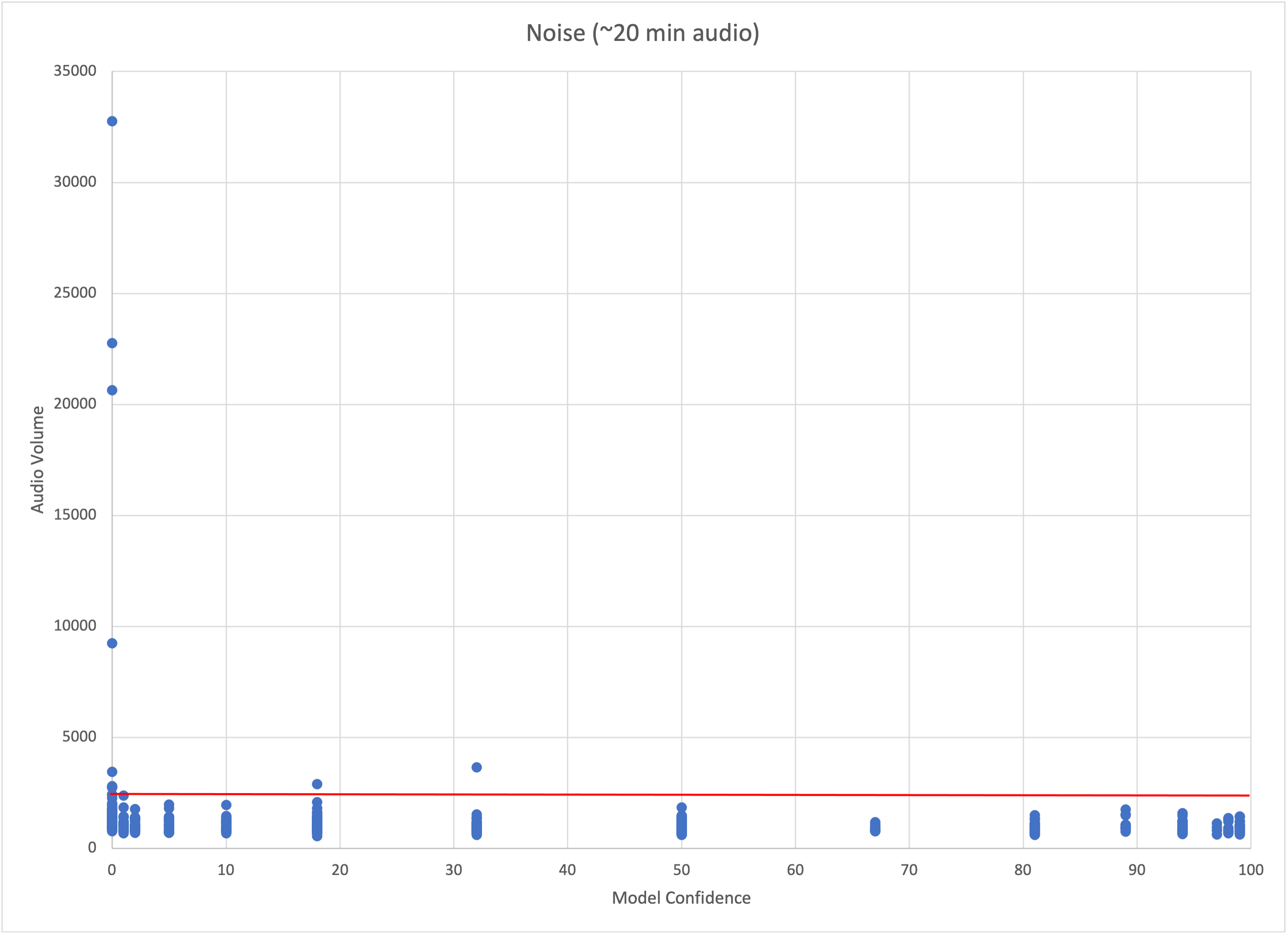
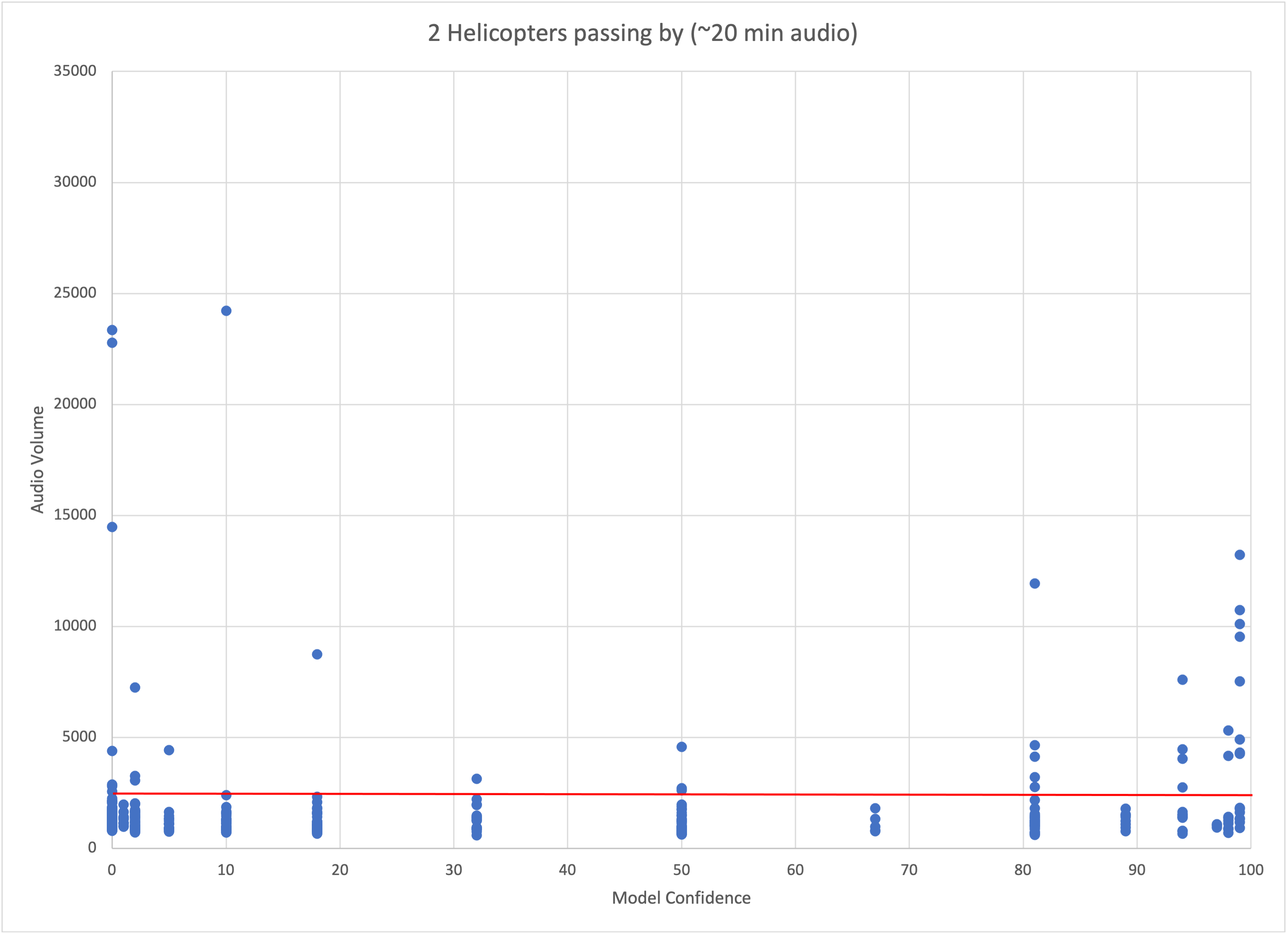
I did a bit of science. Here are 2 different ~20 minute periods. For the first period there were no helicopters present and it was recorded outside. For the second period a group of 2 helicopters flew past around the middle.
I graphed the max sample value for each inference period and the resulting prediction confidence. The red line is about the volume level for talking in a normal voice about a foot or two from the board. A couple observations:
Quiet sounds are all over the place when it comes to predictions
Helicopters are loud
The model accurately predicts loud sounds
The model still jumps around a lot when it is inside and it is quiet, but it will usually stay under 50% confidence.
I have tried adding the background noise samples to training data, but it doesn’t seem to improve the model stability. I am going to try adding in even more samples and seeing if that helps.
Any thoughts on other things I can try? I could always weight the confidence by the max volume for an inference sample.
@Robotastic thanks for all the detailed info on this! I’m on vacation today and tomorrow, and I want to be able to give as much time to this as you put into writing this up. I’ll definitely look into the normalization across silence vs helicopter and let you know about that.
The only thing I’ll mention now is that MFCC is very specifically designed for human speech. Also keep in mind, MFCC looks at change in frequency vs time, not freq vs time. This article has a good overview: https://medium.com/prathena/the-dummys-guide-to-mfcc-aceab2450fd My gut says spectrogram or spectral analysis is the better fit for what you’re doing.
Hi @Robotastic! This actually coincides with some thinking we’ve been doing internally regarding normalization. I think you’re probably right regarding the normalize function making it difficult to discern between quiet and loud noise. A solution to this I’d like to implement in Edge Impulse is normalization using learned parameters across the entire dataset, so the normalized spectrogram accurately represents the relative loudness or quietness rather than throwing that information away. I hope to do some work on this feature some time in the next few months.
In the immediate term, I think your idea of adding a noise floor in your Arduino program is a good one. If you experiment with this, you should also screen your existing training/test data to remove any samples that fall beneath the noise floor.
I’d love to hear how this goes, and we’ll keep you updated on our normalization work! Thank you for your detailed feedback, this is extremely helpful.
@AlexEEE is much more of a DSP expert than I am, so I’m sure he can add some interesting thoughts.
I tried out MFE, MFCC and Spectrogram and I did get the best performance from the Spectrogram. Unfortunately it still has the problem with low volume.
That is a good point about not using low volume Training data for helicopters. It may have been picking up a bit on the amplified noise from the ADC vs the helicopter.
I did leave it running for a bit and if you filter for samples over the threshold, the accuracy is really good. It does miss a few of the distant helicopters, but the goal is to try and record the number of times there are very loud and annoying helicopters flying over head. I will switch to using the loud recordings as training data.
This is great!! I finally got some time and updated to the new Blocks. The Spectrogram seems to be working a bit better… but I haven’t noticed much of an improvement with the MFE. I am wondering if some of the problem is with my dataset. It was recorded using the PDM mic at a mix of different Gains and also a digital recorder. Since the gain maybe different than what is being used at Inference, I wonder if that would have an impact?
I think I might try recording more samples using the onboard mic, with the Gain set to 80.
@AlexE - Tell me more about this MFE Block tweak! I am game to give it a try.
Also - a valuable lessoned learned is that building a model to detect unpredictable, rarely occurring events is a pain. I have tried adding in audio from Youtube… but I am not sure if that helps because it is a lot cleaner than the audio captured by the MCU.
@Robotastic Yeah it definitely is, one thing that we’re working on right now is a ‘model testing on long real-world data’ feature. Here you should be able to either upload (or generate based on our noise datasets mixed in with your test set) a long (1 to 24 hours) stream of audio and then show exactly when the model activates, and the number of false activations and missed events. From here you can then tweak e.g. filters, activation thresholds, result smoothing etc. so you get a great idea on realworld performance.
This is something we’ve learned is pretty hard to do by hand, I’ve done the same replaying of audio from YouTube, but it’s pretty difficult to get accurate numbers over longer time. Don’t have a release date for this yet, but it’s a natural next step for the audio pipelines in Edge Impulse.
Sorry for the delayed response! Can you post your MFE settings that have the best performance right now? Also, sample rate, window size, and window increase.
Also, which classes do you have? Just helicopter and other? It might help to break up “other” into 2 classes, like a “background noise” class with quiet ambient noise, and “other-loud” class, which has other loud, but not helicopter, sounds. Especially if you know at all what kinds of sounds are causing the false alerts, put those into other-loud.