git clone git@github.com:edgeimpulse/firmware-st-b-l475e-iot01a.git replaced by git clone https://github.com/edgeimpulse/firmware-st-b-l475e-iot01a.git
followed by mbed deploy to be allowed to build
This results in following error:
[ERROR] In file included from ./mbed-os/platform/mbed_atomic.h:883:0,
from ./mbed-os/platform/SingletonPtr.h:24,
from ./mbed-os/drivers/I2C.h:26,
from ./mbed-os/components/802.15.4_RF/atmel-rf-driver/source/at24mac.h:23,
from ./mbed-os/components/802.15.4_RF/atmel-rf-driver/source/at24mac.cpp:16:
./mbed-os/platform/cxxsupport/mstd_type_traits:1123:12: error: 'std::is_trivially_copyable' has not been declared
using std::is_trivially_copyable;
^
./mbed-os/platform/cxxsupport/mstd_type_traits:1140:12: error: 'std::is_trivially_constructible' has not been declared
using std::is_trivially_constructible;
^
./mbed-os/platform/cxxsupport/mstd_type_traits:1141:12: error: 'std::is_trivially_default_constructible' has not been declared
using std::is_trivially_default_constructible;
^
./mbed-os/platform/cxxsupport/mstd_type_traits:1142:12: error: 'std::is_trivially_copy_constructible' has not been declared
using std::is_trivially_copy_constructible;
^
./mbed-os/platform/cxxsupport/mstd_type_traits:1143:12: error: 'std::is_trivially_move_constructible' has not been declared
using std::is_trivially_move_constructible;
^
./mbed-os/platform/cxxsupport/mstd_type_traits:1144:12: error: 'std::is_trivially_assignable' has not been declared
using std::is_trivially_assignable;
^
./mbed-os/platform/cxxsupport/mstd_type_traits:1145:12: error: 'std::is_trivially_copy_assignable' has not been declared
using std::is_trivially_copy_assignable;
^
./mbed-os/platform/cxxsupport/mstd_type_traits:1146:12: error: 'std::is_trivially_move_assignable' has not been declared
using std::is_trivially_move_assignable;
^
[mbed] ERROR: "/anaconda/bin/python" returned error.
Code: 1
Path: "/Users/au263437/workspace/ML_uc/ei2/firmware-st-b-l475e-iot01a"
Command: "/anaconda/bin/python -u /Users/au263437/workspace/ML_uc/ei2/firmware-st-b-l475e-iot01a/mbed-os/tools/make.py -t GCC_ARM -m DISCO_L475VG_IOT01A --profile debug --source . --build ./BUILD/DISCO_L475VG_IOT01A/GCC_ARM-DEBUG -c"
Tip: You could retry the last command with "-v" flag for verbose output
[mbed] WARNING: Using Python 3 with Mbed OS 5.8 and earlier can cause errors with
compiling, testing and exporting
I’m new on the mbed offline tools, can anyone point me towards a remedy
Hi @opprud I realized that we had a small issue with the firmware repo which might failed to load the right matching Mbed OS version (but not 100% sure), so could you run:
$ git pull
$ mbed deploy
To ensure you’re at the right dependency version?
FYI these are my tool versions which build the firmware successfully:
GCC ARM
$ arm-none-eabi-gcc --version
arm-none-eabi-gcc (GNU Tools for Arm Embedded Processors 9-2019-q4-major) 9.2.1 20191025 (release) [ARM/arm-9-branch revision 277599]
Mbed CLI
$ mbed --version
1.10.0
Could you post similar output if the above didn’t work?
adding “” to the GCC_ARM_PATH seemed to do the trick.
My local arm-none-gcc- is only 4.9, but i assume the mbed config -G adds the gcc 9.4 to the mbed build system.
Image now builds
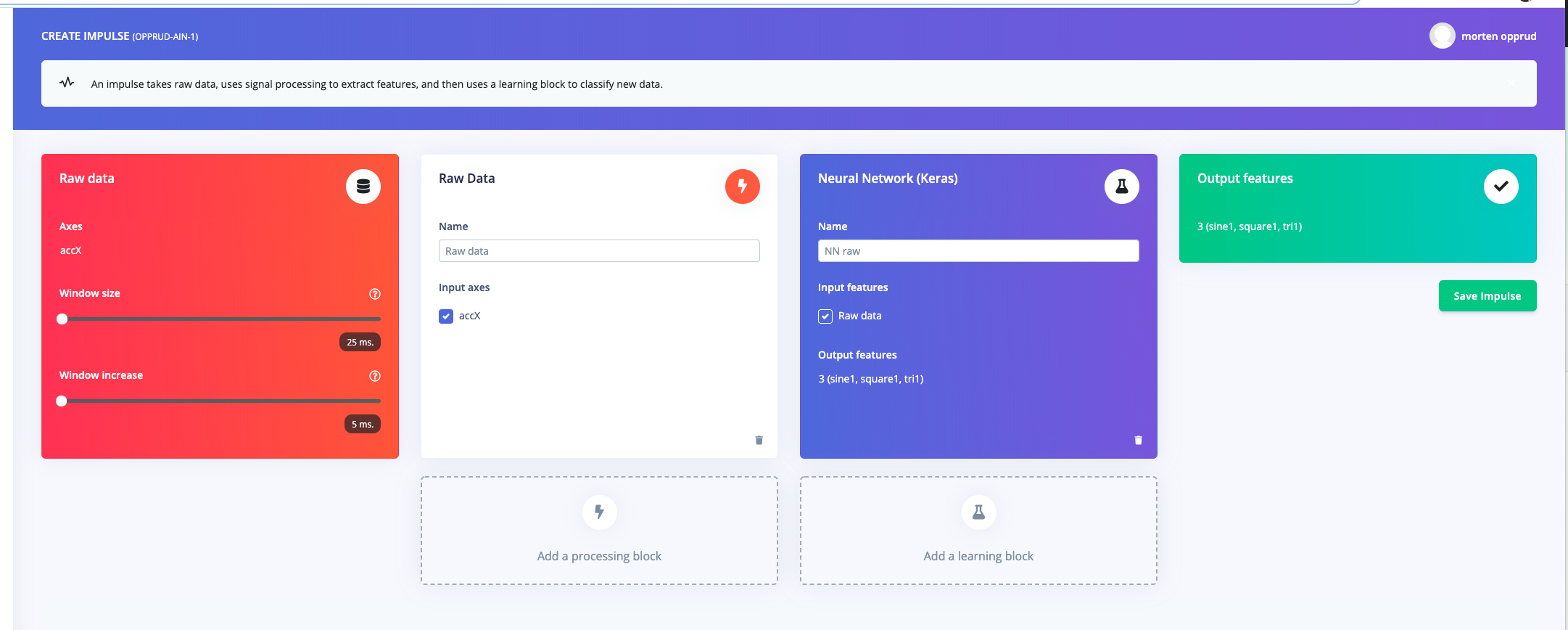
Moving ahead, do you plan to add some notes on how to add additional support for sensors to the edgeimpulse studio, in my case an accelerometer attached to SPI or analog input
awesome job you’we done with edgeimpulse sofar btw
Cool, thanks i got low speed ADC data coming in.
Running the sampler faster than a few 100 Hz breaks the execution.
Sorry for stealing forum bandwidth here, but when i need 30+KHz ADC sampling, i guess i need to get into the lowest HAL layers to setup the ADC preferable to use DMA to push data to a buffer.
The ei_microphone.h running @16.000Hz is a bit scary in terms of buffering up data, and writing it to flash ?during? acquisition.
Would a hack be to use a ticker to sample data, once acquisition is started, and buffer up in between each ei_<mymodule>_sample_read_data(float *values, size_t value_size), and what dictates the shape of values in this case, can it be an array…?
There’s a sensor_aq_add_data_batch() that seems to grab an array next to sensor_aq_add_data() in sensor_aq.h that im guessing might be useful for this ?
/morten
Btw, The ultralow power target coming up, during next weeks TinyML summit wouldn’t happen to be Ambiq Apollo3 ?
Hi @opprud, yes the sampler is really made for lower frequency data collection, if you’re sampling at 32KHz I’d look at how we sample from the microphone. Buffering to flash is required because we only have 128K of RAM of which maybe 40K is available during sampling. We use this two stage process (first buffer raw data, then process the data into the right format) because the flash is pretty slow and we spend almost all of our cycles waiting for writes to complete (this is also why we do an erase pass before sampling). Creating the file on filesystem directly during sampling is non-deterministic because it starts erasing pages randomly - causing delays up to 70 ms. which would cause the buffer to be overwritten.
Makes sense, a target with a few hundred K’s of additional RAM would ease this issue
If i keep the sampletime/buffersize low enough, can i pass an array of values each time ei_<mymodule>_sample_read_data(float *values, size_t value_size) ,is called e.g. every 10 or 20 ms, to avoid overloading the sampler
@opprud, the easiest would just be to skip the sampler and use the C Ingestion SDK to write the files. Just call sensor_aq_add_data (or the batch variant) whenever you have data cached. Then use the sampler only to upload. The sampler has all sorts of timing information around it that don’t need there.
Headless, polled adc.read_u16() in a loop, filling a buffer gives an acceptable samplerate of ~34KHz,
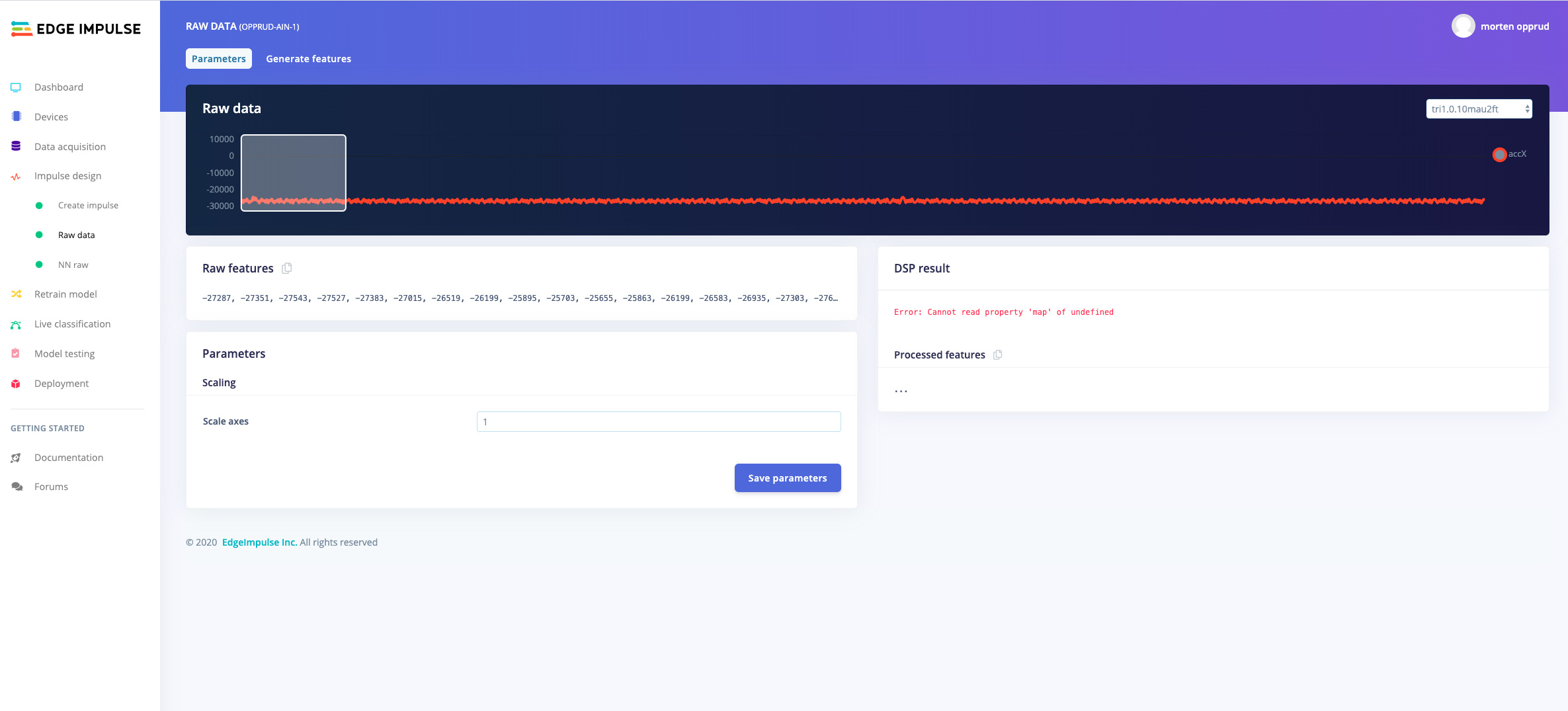
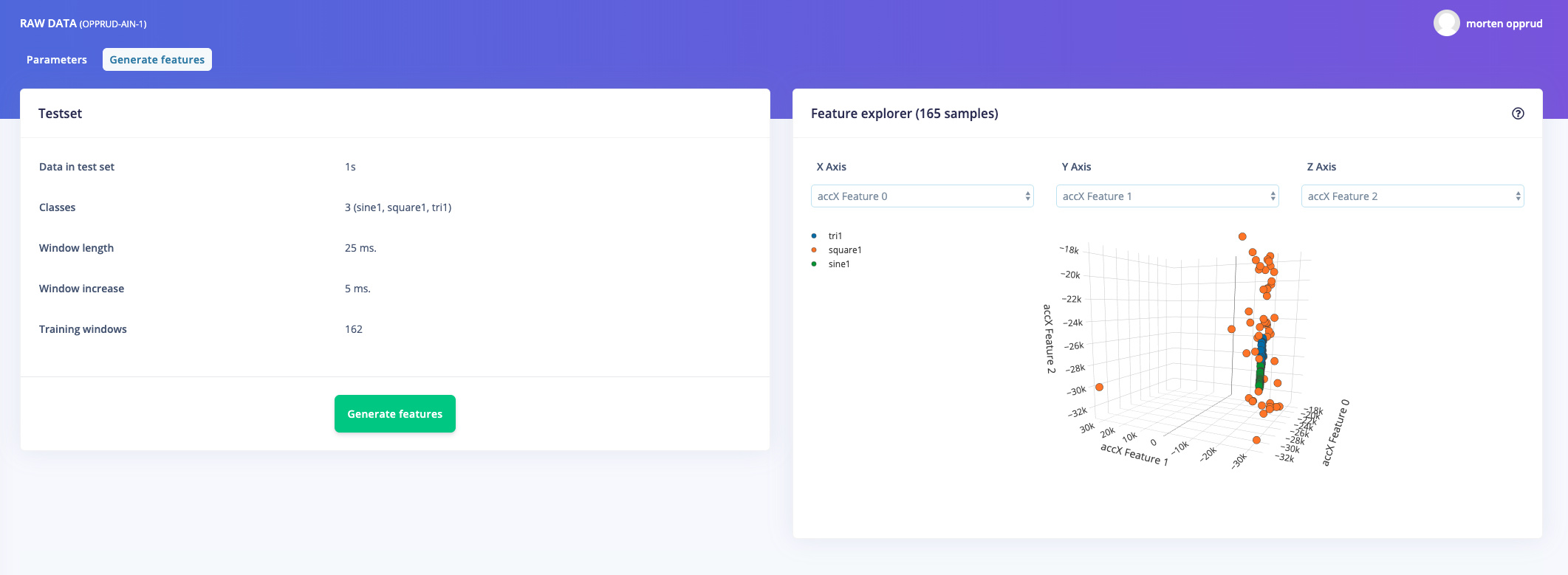
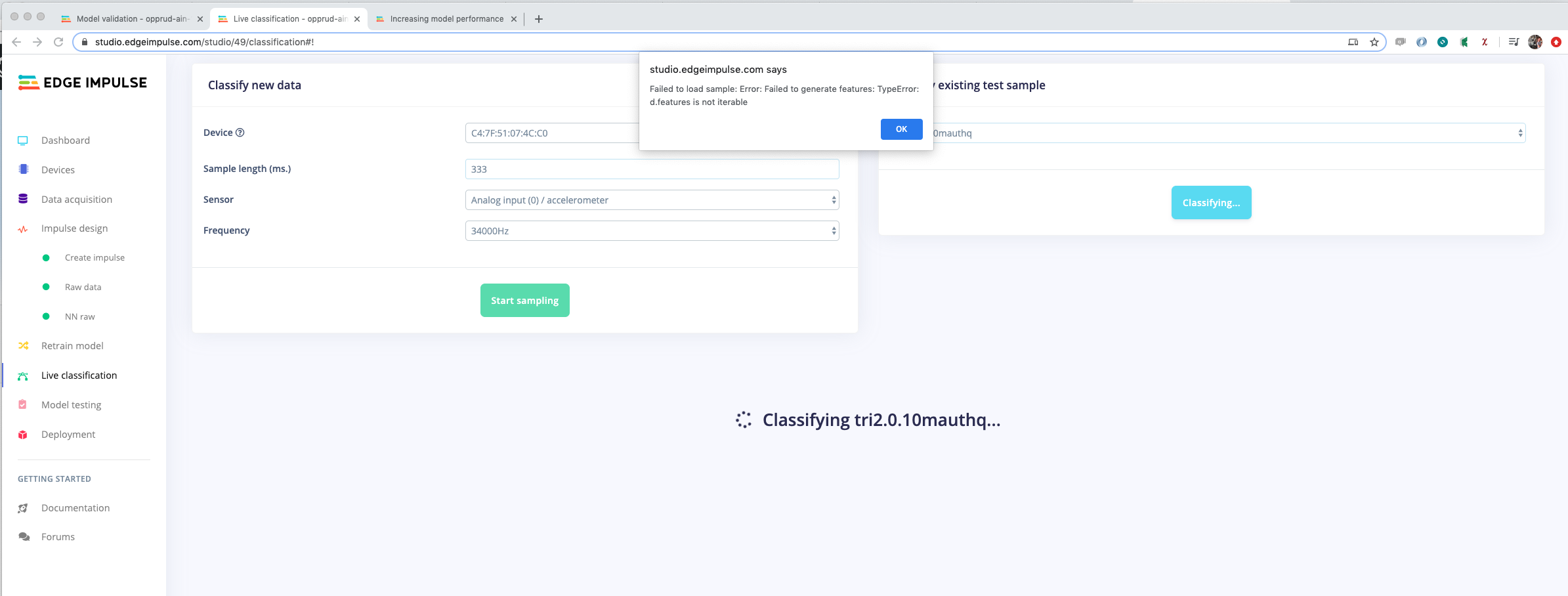
I fill a buffer with 10.000 samples (20.000 threw a buffer allocation error ), upload them and look at it, when generating features, either raw or FFT’ed, following appears:
Feature generation output
Creating job… OK (ID: 11197) Creating windows from 4 files… Failed to process an_500hz_3.0.10js7co7: Cannot process file, impulse window size setting requires 57085 data frames, but this file only contains 10000 data frames Job failed (see above)
Capturing additional 47085 samples and appending them to the open file, i guess would require DMA to handle the ADC in the background, as sampling done in an ADC ISR would maybe kill the filesystem ?
I assume it’s a flash file sys, is there recommendation on the block/buffer sizes, to reach optimal performance of the file sys, when parsing a finished sample buffer ?
Perhaps by having two 8-10K buffers, and filling one while flushing the other, to the open file ?
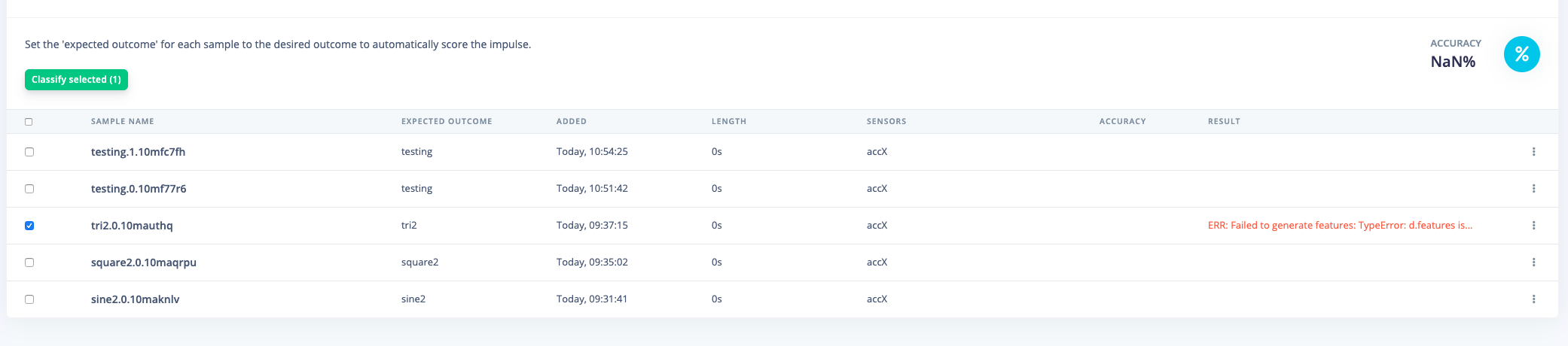
@opprud, that error actually indicates that the an_500hz_3.0.10js7co7 file does not have enough samples for the window setting you chose. My guess would be that that file is shorter than the window you’ve set in the impulse. Note that all files need to have the same frequency, so if you’ve been experimenting you might want to remove older files with the wrong frequency.
@opprud, Interesting bug you found! This happens when the values in your data are integers, and not floats, and piping the input through the raw features block. We’ve deployed a fix now!