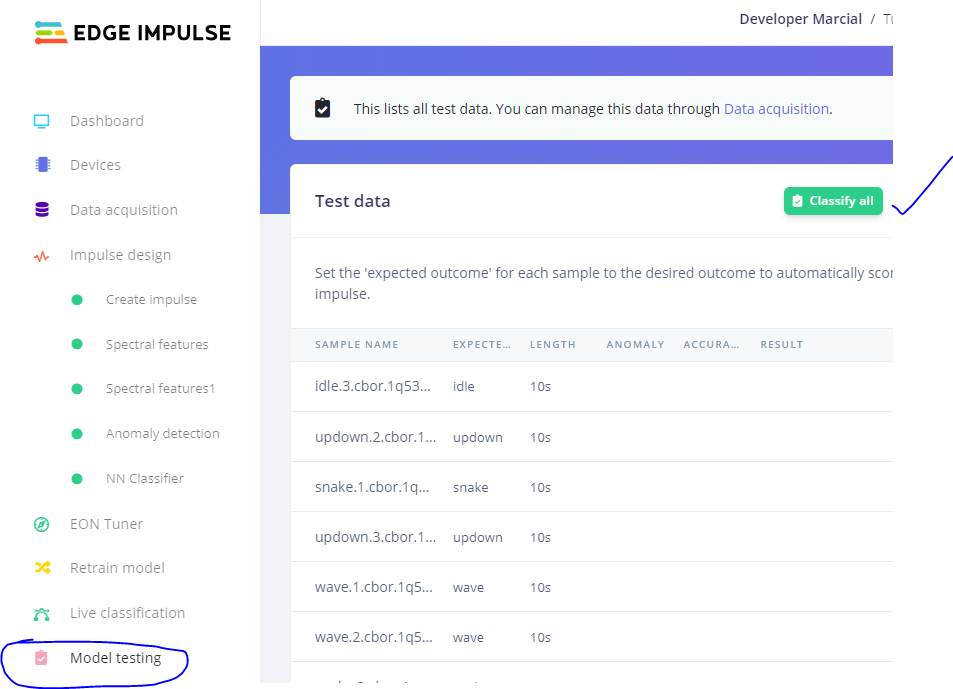
Good evening everyone,
I would like to ask if this models has good acting or not, is there overfitting?If yes, what are the suggestions to correct it?
Hi @Bayan_khalid,
Can you provide your project ID so we can take a look at your dataset, validation, and test results? Without context, I’m not sure what A, B, C, D, E, F mean. 90% may be good enough–it all depends on your particular application and what’s an acceptable accuracy for your needs.
Project ID:196699
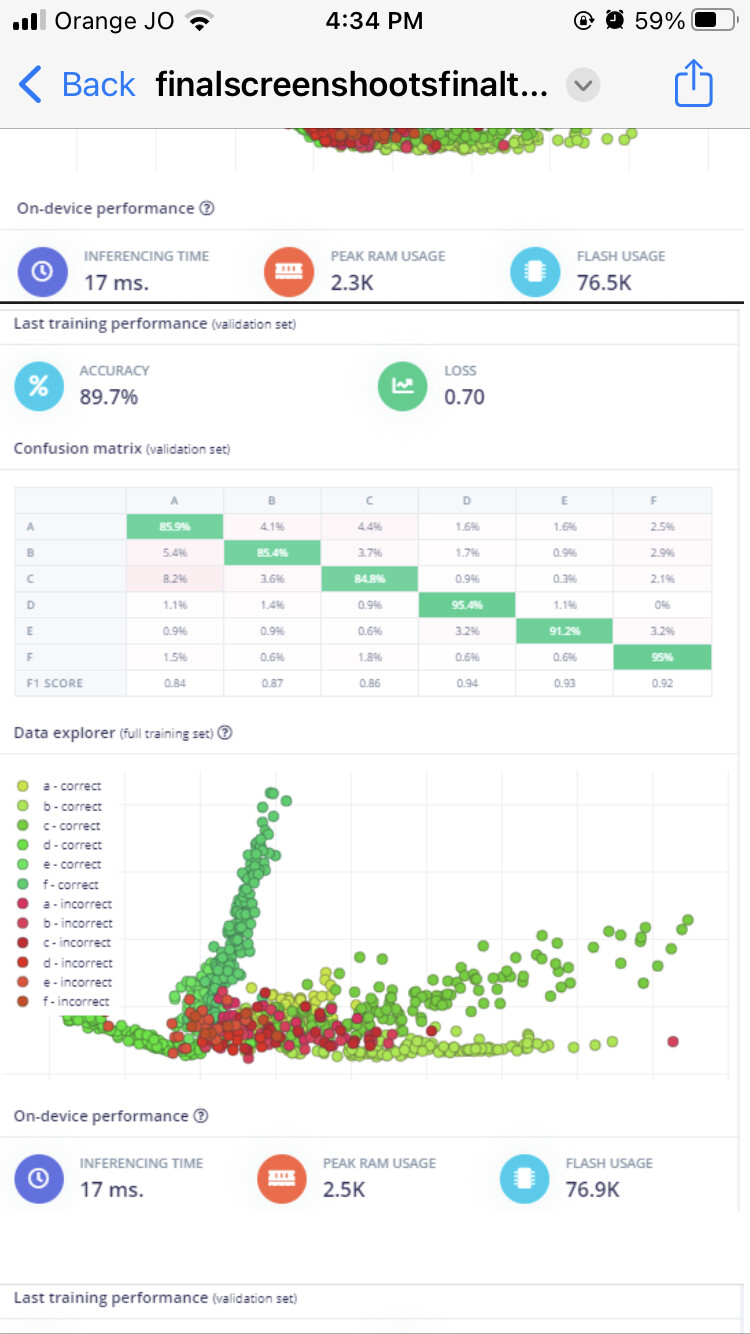
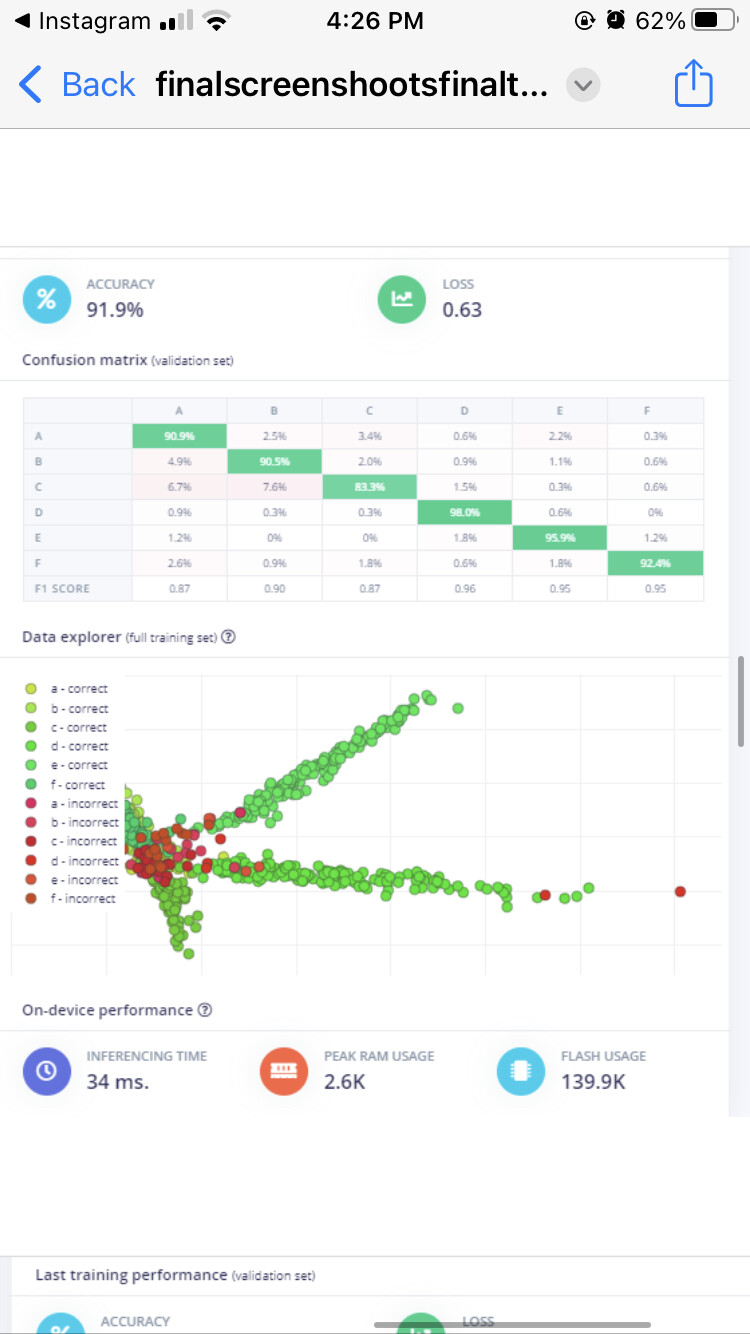
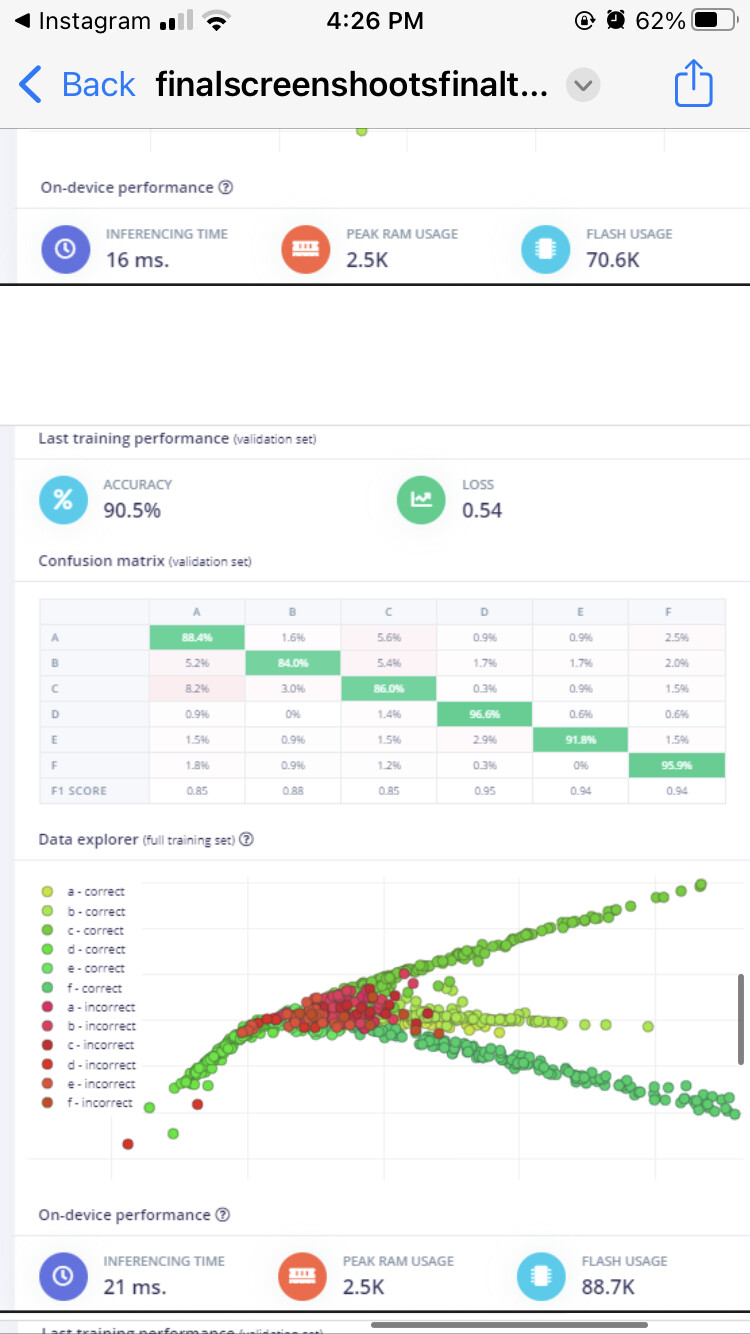
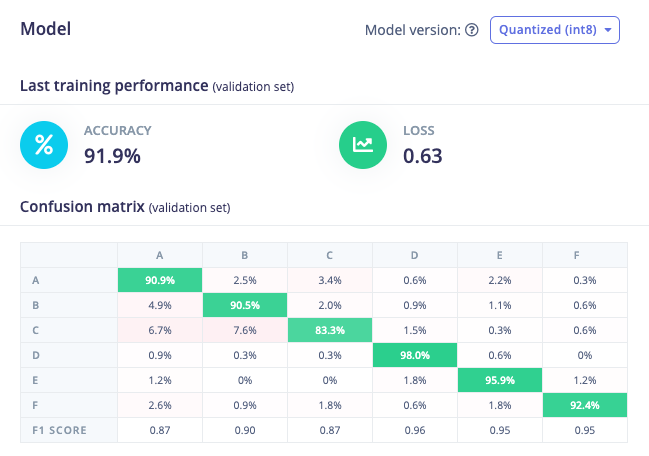
labels represent
A: normal drive
B: bumps
C: circle bumps
D: sudden start
E: sudden stop
F: sudden detour
Hi @Bayan_khalid,
In your latest model training, it looks like you have ~92% accuracy on your validation set.
If you test your model using the test (holdout) set, you get ~76%.
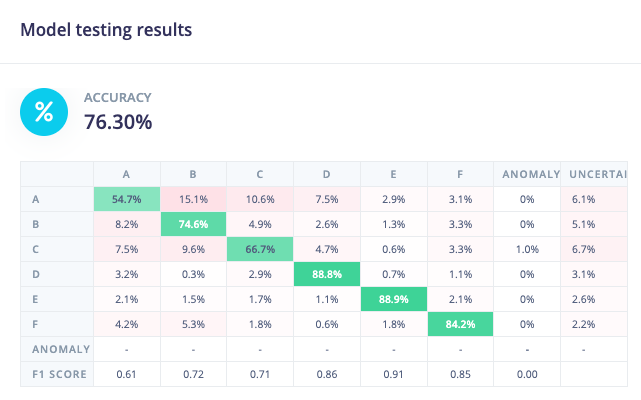
Because your test set accuracy is significantly lower than your validation/training accuracy, it appears that you have overfit your model to your training data. There are a few ways to address this:
- Gather more data to create a robust model
- Reduce the complexity of your model (i.e. fewer layers, fewer nodes per layer)
- Try a different feature extraction method or hyperparameters (e.g. play around with your spectral analysis settings or try a different processing block)
I might recommend using EON Tuner to help guide you in a good direction for finding a balance of feature extraction and model complexity. I also recommend reading through these tips for helping with model performance.
2 Likes