Hello,
We are developing a sound detection application (on a ESP32) to detect animal sounds. I’m familiar with the code changes required to implement a continuous sound detection scheme & have a working implementation.
My question is, does a sound detection model have to be modified if one wants to change from continuous to non-continuous or vice versa?
Many thanks,
Owen
I’ve looked at the difference in the code for
run_classifier_continuous()
and
run_classifier()
And the difference appears to be the expression in the continuous code:
enable_maf = true
This is referred to in ei_run_classifier.h & there is a reference to
ei_printf(“WARN: run_classifier_continuous, enable_maf is true, but performance calibration is not configured.\n”);
ei_printf(" Previously we’d run a moving-average filter over your outputs in this case, but this is now disabled.\n");
ei_printf(" Go to ‘Performance calibration’ in your Edge Impulse project to configure post-processing parameters.\n");
ei_printf(" (You can enable this from ‘Dashboard’ if it’s not visible in your project)\n");
ei_printf(“\n”);
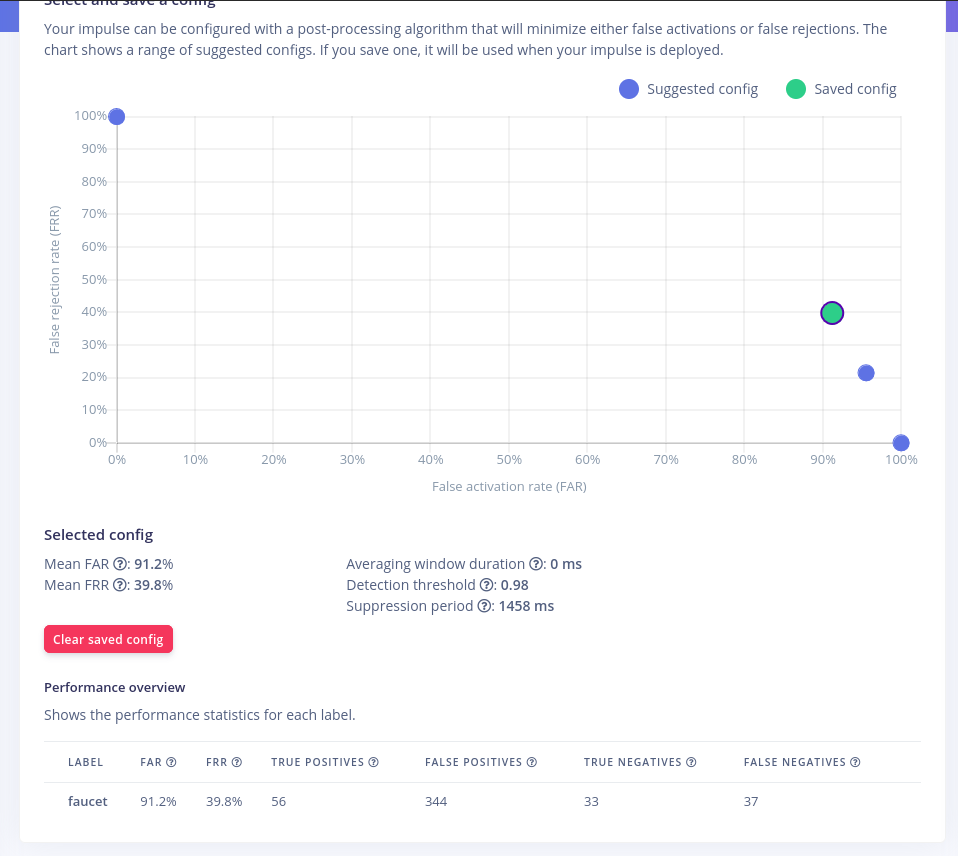
I don’t see an explicit way of setting this option, in for example, the faucet detection example. Screenshot below.
Is enable_maf set to true when the ‘Averaging window duration’ is greater than 0?
Thanks
Hi @electronicconsult1_g,
To answer your first question: the model can be the same between run_classifier() and run_classifier_continuous(). The big benefit behind run_classifier_continuous() is that it caches previous slices of your DSP processing (MFE, MFCC, spectrogram) to create a rolling window across time. This saves you from having to create a rolling buffer with raw data (thus saving a good amount of RAM).
To answer your second question: run_classifier_continuous() only enables the moving average filter (MAF) when you have gone through the calibration (https://docs.edgeimpulse.com/docs/edge-impulse-studio/performance-calibration) process. You can easily create your own MAF by collecting inference results and averaging them over time.
1 Like