Question/Issue:
I am trying to profile and deploy a BYOM 1D ConvNet model using the EI dashboard. When I upload the model in ONNX format along with representative NPY features, there still is not any option to quantize it in the Deployment page or anywhere else. I need to quantize it, to make it “fit” in the nRF52840.
Project ID:
776399
Steps Taken:
- Successfully uploaded model in ONNX format, along with representative features in .npy file.
- Successfully viewed “On-device performance” and option to deploy float32 model via downloading C++ libraries.
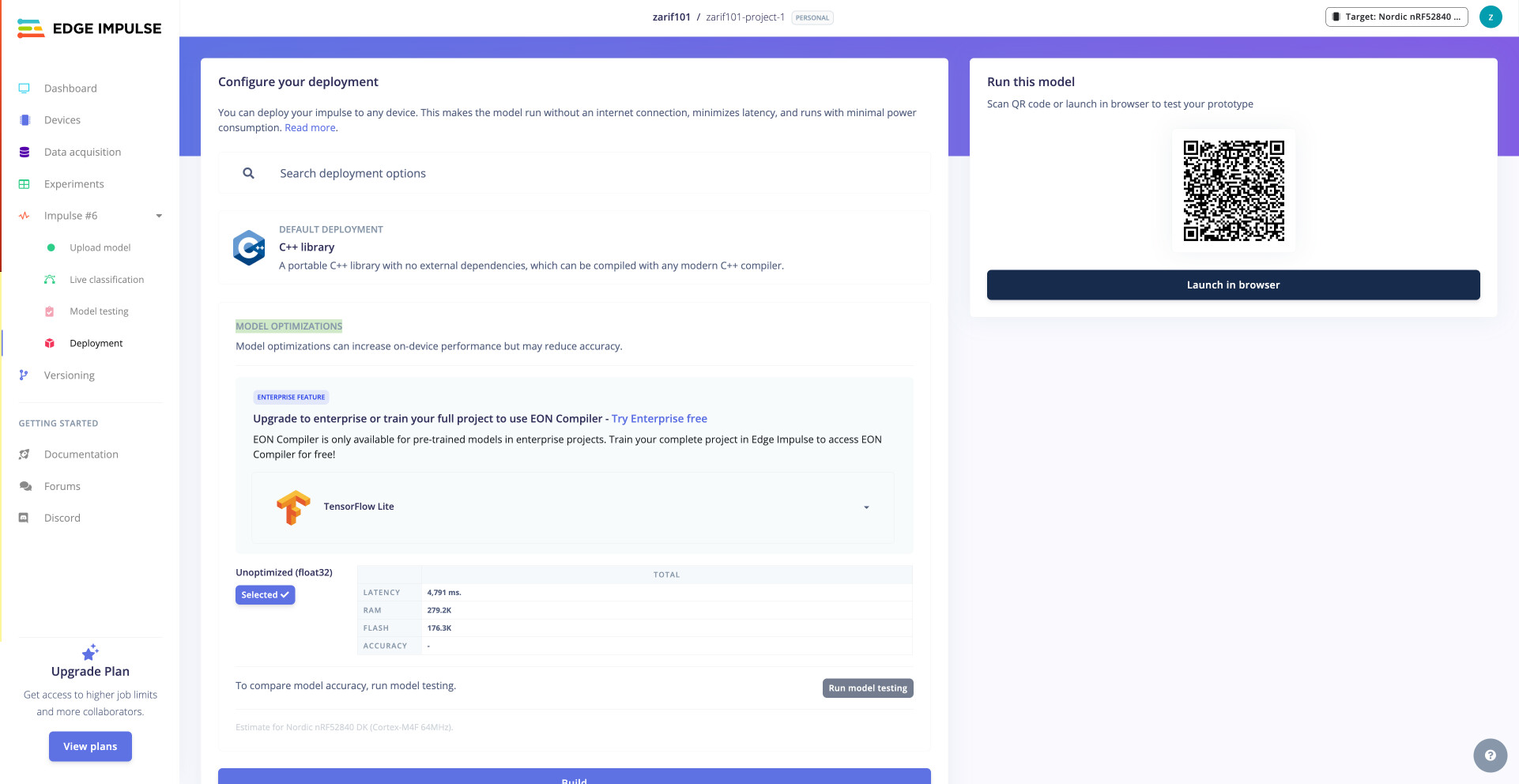
- Attempted to quantize model under the “Model Optimizations” section of the Deployment page, but do not see any option other than float32 (looking for int8).
Expected Outcome:
Expected to see option for int8 quantization under “Model Optimizations,” as the layers of the model are standard convolutions, and I uploaded representative features.
Actual Outcome:
Do not see any option for model optimizations.
Reproducibility:
Always
Environment:
- Platform: nRF52840
- Using Edge Impulse dashboard
Logs/Attachments:
Include screenshot of deployments page that shows no quantization options
Additional Information:
Sharing model architecture (written in PyTorch, converted to ONNX)
class DWConv1d(nn.Module):
"""Depthwise 1-D convolution. Preserves channel count."""
def __init__(self, in_ch: int, k: int, stride: int = 1, dilation: int = 1, bn: bool = True, act: bool = True):
super().__init__()
pad = (k // 2) * dilation
self.dw = nn.Conv1d(in_ch, in_ch, k, stride=stride, padding=pad, dilation=dilation, groups=in_ch, bias=False)
self.bn = nn.BatchNorm1d(in_ch) if bn else nn.Identity()
self.act = nn.ReLU(inplace=True) if act else nn.Identity()
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.dw(x)
x = self.bn(x)
x = self.act(x)
return x
class PWConv1d(nn.Module):
"""Pointwise 1x1 convolution."""
def __init__(self, in_ch: int, out_ch: int, bn: bool = True, act: bool = True):
super().__init__()
self.pw = nn.Conv1d(in_ch, out_ch, 1, bias=False)
self.bn = nn.BatchNorm1d(out_ch) if bn else nn.Identity()
self.act = nn.ReLU(inplace=True) if act else nn.Identity()
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.pw(x)
x = self.bn(x)
x = self.act(x)
return x
class DSBlock(nn.Module):
def __init__(self, in_ch: int, out_ch: int, k: int = 5, stride: int = 1, dilation: int = 1,
residual: bool = True, drop: float = 0.0):
super().__init__()
self.depthwise = DWConv1d(in_ch, k, stride=stride, dilation=dilation)
self.pointwise = PWConv1d(in_ch, out_ch)
self.dropout = nn.Dropout(p=drop) if drop > 0 else nn.Identity()
self.residual = residual and (in_ch == out_ch and stride == 1)
def forward(self, x: torch.Tensor) -> torch.Tensor:
y = self.depthwise(x)
y = self.pointwise(y)
y = self.dropout(y)
if self.residual:
y = y + x
return y
class DSCNN1D(nn.Module):
"""
Minute/short-window classifier for accel
Inputs: (B, 3, L)
Outputs: (B, K)
"""
def __init__(self, in_ch: int = 3, num_classes: int = 3, stem_ch: int = 32,
blocks: Optional[List[Tuple[int, int, int]]] = None, head_drop: float = 0.1):
super().__init__()
if not blocks:
blocks = [(32,5,1), (32,5,2), (64,5,1), (64,5,2), (96,3,1), (128,3,2)]
self.stem = PWConv1d(in_ch, stem_ch, bn=True, act=True)
layers: List[nn.Module] = []
ch = stem_ch
for out_ch, k, s in blocks:
layers.append(DSBlock(ch, out_ch, k=k, stride=s, residual=True, drop=0.0))
ch = out_ch
self.features = nn.Sequential(*layers)
self.pool = nn.AdaptiveAvgPool1d(1)
self.head = nn.Sequential(nn.Flatten(), nn.Dropout(p=head_drop), nn.Linear(ch, num_classes))
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.stem(x)
x = self.features(x)
x = self.pool(x)
x = self.head(x)
return x
Can provide any additional info as helpful. Would greatly appreciate any support!