Question/Issue: Training output does not give an int8 optimized version of the model to use.
Project ID: 199176
Context/Use case: Cloned the project Counting Cubes (project id: 39560, which shows both float32 and int8 optimized models as training output), and just trained the model again without any changes to the project specifics (including DSP, Model, Etc). From the looks of it, there is a float32 version of the model as output, but no int8 optimized output after training again. Noticed a similar issue with projects started from scratch. Is there a new update/setting we should know about?
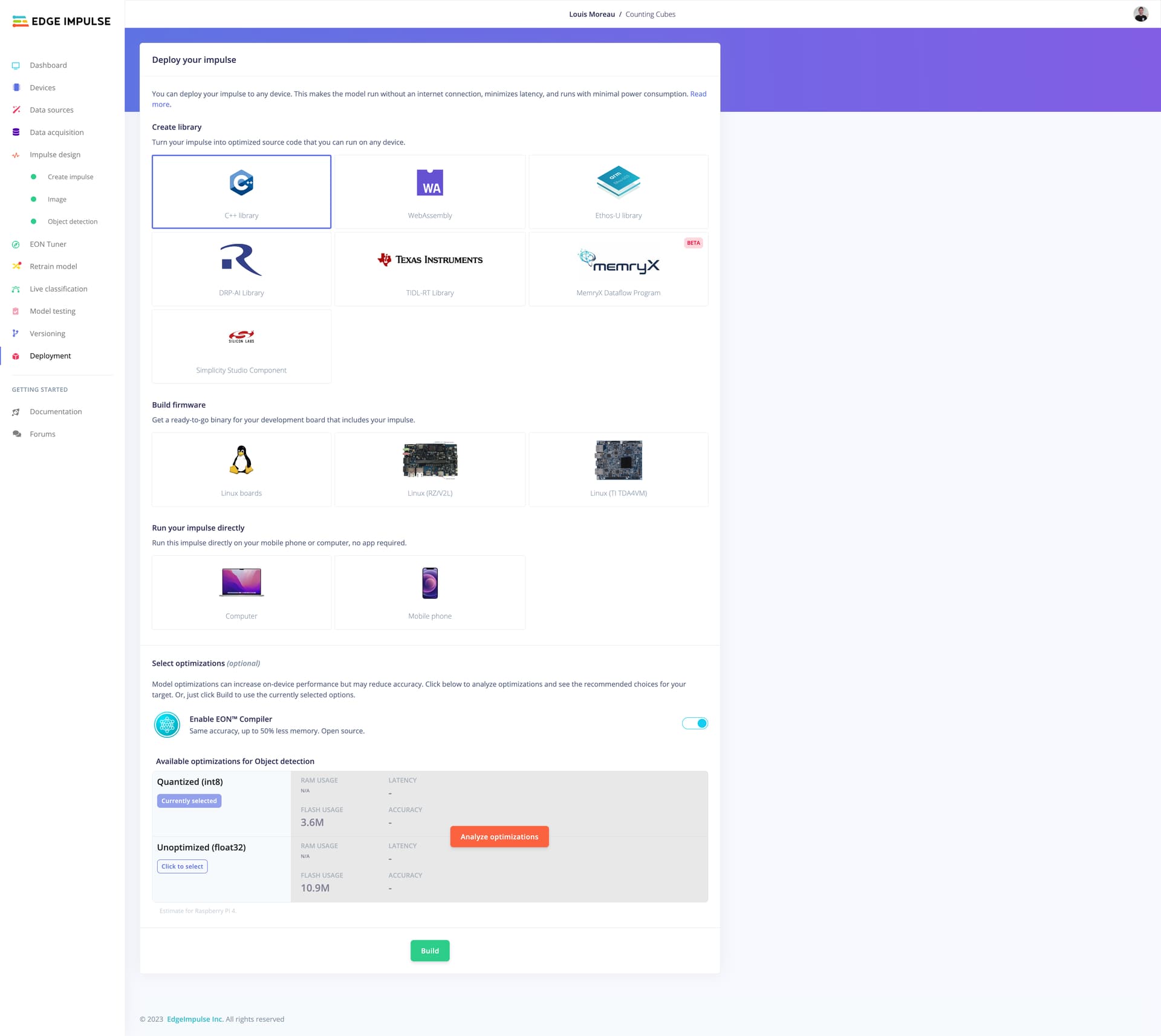
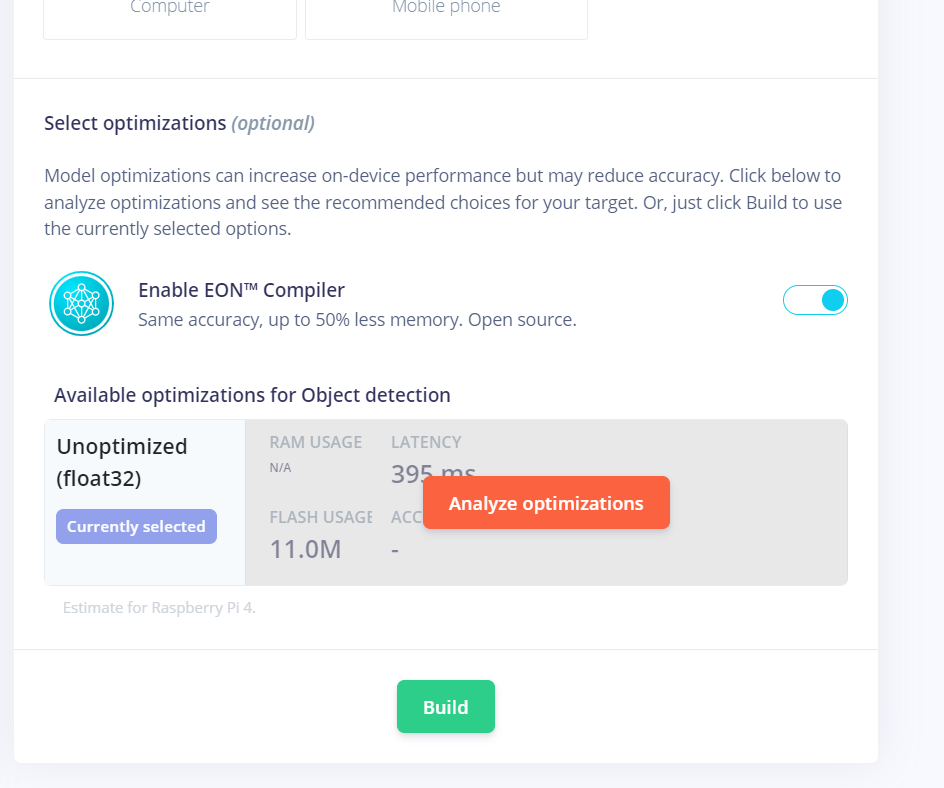
Are you seeing on the Studio Deployment page at the very bottom of the page only a Unoptimized (float32) and are not seeing Quantized (int8) build option?
Yes that is correct, I only see Unoptimized float32 build option on the deployment page. And I only see unoptimized float32 output result after training as well. No option to switch to optimized int8 like it used to be on the training page, and no option for deployment of the same either.
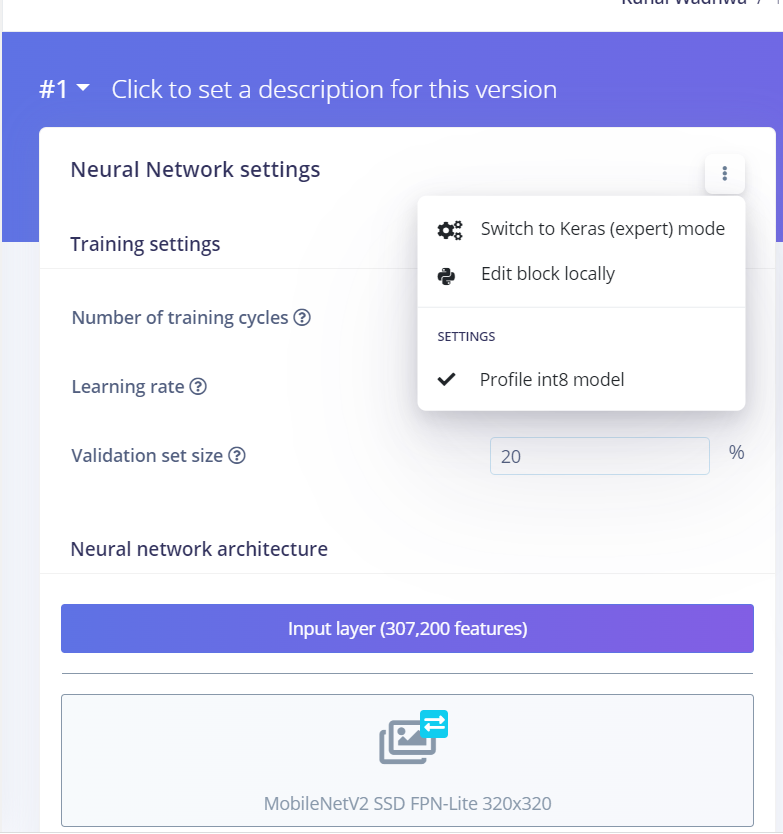
Also, with Jenny’s project, I do not see an option to profile for int8, which I see when I clone the project. That option is checked, but I still do not see an output int8 model.
Indeed, I did not retrained it. I can now see the same as you. I’ll check internally why.
That being said, MobileNetv2 SSD will only works on linux architectures and have very bad results with quantized version. That’s probably the reason we removed it but not entirely sure, I’ll let you know if I know more.
Also, I would love to hear about your need for int8 to understand the context.
Thank you for your response. I was trying to use the MobileNetv2 SSD with an ESP32. Since the size of int8 optimized model is ~3.6/3.7 MB, I can still put it to use on smaller non-linux devices like I mentioned. This isn’t possible with the float32 model which is around 11 MB.
Is there a way we can get that back? Let me know! And thanks a ton for your help.
I’d suggest to use FOMO object detection model that will fit on the ESP32. MobileNetv2 SSD would be too greedy in RAM. At least I have never seen anyone using it on an ESP32.
Let me know if you need some resources around FOMO to understand how it works.l, I’d be happy to help.
Thanks @louis, I’ve been able to use FOMO on ESP32 and it works as expected.
Again, thanks for the help and let me know if there’s any changes and we can still use the int8 optimized version using the MobileNetv2 SSD.