On popular request we’ve added a new processing block which outputs a spectrogram. Super useful for any sensor signal with both frequency and time components. The spectrorgam is still tuned a little bit towards the human hear as this is Mel Energy spectrogram (more on the why at the bottom of this forum post) rather than a normal spectrogram, but should be very useful specifically for non-voice audio. Naturally the MFCC block has not gone anywhere, so for best performance on voice tasks you’d still use that.
To add the new block, navigate to your Edge Impulse project, go to Create impulse and click Add a processing block. Then select Audio (MFE):
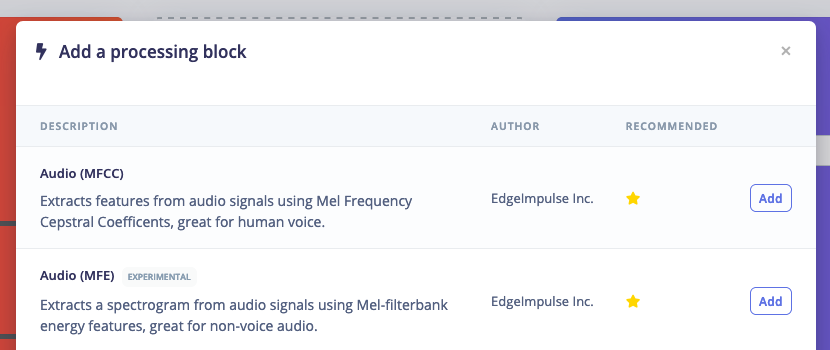
And then you’ll have the new MFE UI showing a spectrogram!
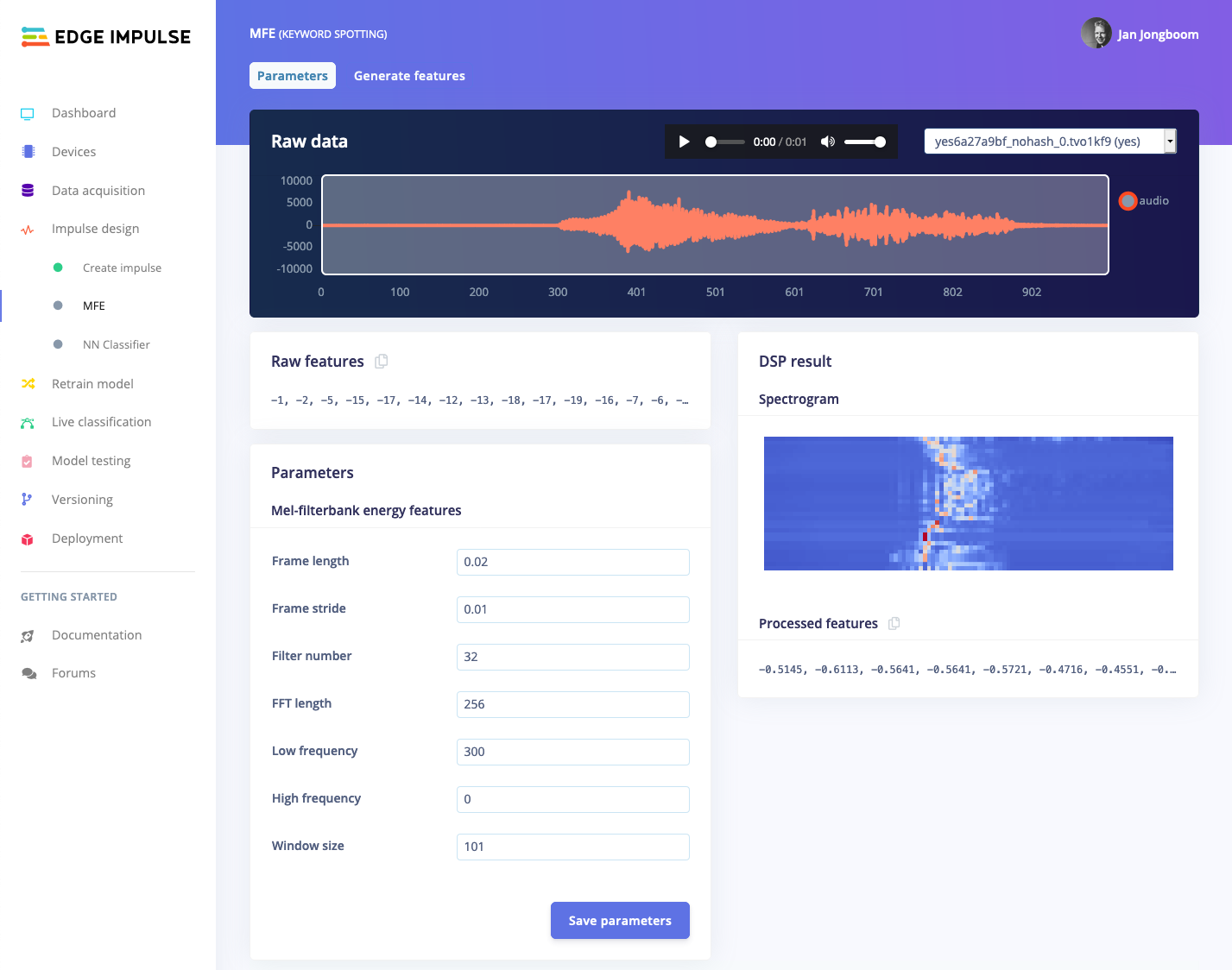
Everything from here out works exactly the same as in Recognizing sounds from audio, so follow that tutorial for more info.
Some notes:
- A spectrogram is a lot bigger than the MFCC features, so this has a non-negligible effect on on-device performance. We’ve set default ‘frame length’ and ‘frame stride’ parameters so this works on the smallest devices we support, but you probably want to set ‘frame length’ to 0.02, and ‘frame stride’ to 0.01 for the best effect.
- MFE DSP blocks work on device, in both normal classification as well as in continuous mode. All ready-to-go firmware builds from the studio can handle these blocks.
Last: why Mel spectrograms and not normal spectrogram? Mainly to shorten development time. We’re already calculating the MFE spectrogram when creating the MFCC, so we have finished the device implementation (and optimizations, like using the vector extensions) already and have validated the algorithm on a very wide set of data and devices. If you want a normal spectrogram, head to Building custom processing blocks!