Question/Issue:
Multiple errors in
Impulse design > Classifier
Training output.
Job is cancelled
What might be the issue?
Project ID:
ChrisTech-project-1
Context/Use case:
Error message:
Scheduling job in cluster…
Job started
Initializing job pod…
(node:78) MaxListenersExceededWarning: Possible EventEmitter memory leak detected. 11 change listeners added to [StatWatcher]. Use emitter.setMaxListeners() to increase limit
at _addListener (node:events:465:17)
at StatWatcher.addListener (node:events:487:10)
at Object.watchFile (node:fs:2319:8)
at Object.watchFile (/home/node/common/node_modules/dd-trace/packages/datadog-instrumentations/src/fs.js:239:57)
at new PgDBImpl (/home/node/studio/build/server/shared/db/pg_db.js:130:26)
at new PgDB (/home/node/studio/build/server/shared/db/pg_db.js:9024:9)
at Object. (/home/node/studio/build/server/server/init-server.js:145:14)
at Module._compile (node:internal/modules/cjs/loader:1101:14)
at Object.Module._extensions…js (node:internal/modules/cjs/loader:1153:10)
at Module.load (node:internal/modules/cjs/loader:981:32)
at Function.Module._load (node:internal/modules/cjs/loader:822:12)
at Module.require (node:internal/modules/cjs/loader:1005:19)
at Module.Hook.Module.require (/home/node/common/node_modules/dd-trace/packages/dd-trace/src/ritm.js:85:33)
at require (node:internal/modules/cjs/helpers:102:18)
at Object. (/home/node/studio/build/server/server/start-daemon.js:38:27)
at Module._compile (node:internal/modules/cjs/loader:1101:14)
at Object.Module._extensions…js (node:internal/modules/cjs/loader:1153:10)
at Module.load (node:internal/modules/cjs/loader:981:32)
at Function.Module._load (node:internal/modules/cjs/loader:822:12)
at Function.executeUserEntryPoint [as runMain] (node:internal/modules/run_main:81:12)
at node:internal/main/run_main_module:17:47
Initializing job pod OK
Scheduling job in cluster…
Container image pulled!
Job started
Splitting data into training and validation sets…
Splitting data into training and validation sets OK
Training model…
Training on 176 inputs, validating on 44 inputs
6/6 - 1s - loss: 546.7579 - accuracy: 0.2216 - val_loss: 206.9956 - val_accuracy: 0.2500 - 1s/epoch - 244ms/step
Performing post-training quantization…
Performing post-training quantization OK
Running quantization-aware training…
Epoch 1/30
6/6 - 3s - loss: 3.0473 - accuracy: 0.2386 - val_loss: 2.5020 - val_accuracy: 0.3409 - 3s/epoch - 435ms/step
Epoch 2/30
6/6 - 1s - loss: 2.9999 - accuracy: 0.2557 - val_loss: 2.4301 - val_accuracy: 0.3409 - 1s/epoch - 223ms/step
Epoch 3/30
6/6 - 2s - loss: 2.8657 - accuracy: 0.2670 - val_loss: 2.3228 - val_accuracy: 0.3182 - 2s/epoch - 254ms/step
Epoch 4/30
6/6 - 1s - loss: 2.7966 - accuracy: 0.2898 - val_loss: 2.2077 - val_accuracy: 0.3409 - 1s/epoch - 224ms/step
Epoch 5/30
6/6 - 1s - loss: 2.7026 - accuracy: 0.2727 - val_loss: 2.0418 - val_accuracy: 0.3182 - 1s/epoch - 220ms/step
Epoch 6/30
6/6 - 1s - loss: 2.5928 - accuracy: 0.2955 - val_loss: 1.9569 - val_accuracy: 0.3182 - 1s/epoch - 225ms/step
Epoch 7/30
6/6 - 2s - loss: 2.5414 - accuracy: 0.2898 - val_loss: 1.9123 - val_accuracy: 0.3409 - 2s/epoch - 275ms/step
Epoch 8/30
6/6 - 1s - loss: 2.4700 - accuracy: 0.2670 - val_loss: 1.8683 - val_accuracy: 0.3182 - 1s/epoch - 218ms/step
Epoch 9/30
6/6 - 1s - loss: 2.3338 - accuracy: 0.2898 - val_loss: 1.7883 - val_accuracy: 0.3182 - 1s/epoch - 223ms/step
Epoch 10/30
6/6 - 2s - loss: 2.3284 - accuracy: 0.2898 - val_loss: 1.7037 - val_accuracy: 0.3636 - 2s/epoch - 267ms/step
Epoch 11/30
6/6 - 1s - loss: 2.3065 - accuracy: 0.3125 - val_loss: 1.6721 - val_accuracy: 0.4091 - 1s/epoch - 219ms/step
Epoch 12/30
6/6 - 1s - loss: 2.1318 - accuracy: 0.3125 - val_loss: 1.6439 - val_accuracy: 0.4318 - 1s/epoch - 211ms/step
Epoch 13/30
6/6 - 0s - loss: 2.0946 - accuracy: 0.3466 - val_loss: 1.6514 - val_accuracy: 0.4318 - 55ms/epoch - 9ms/step
Epoch 14/30
6/6 - 2s - loss: 1.9145 - accuracy: 0.3580 - val_loss: 1.5888 - val_accuracy: 0.5227 - 2s/epoch - 264ms/step
Epoch 15/30
6/6 - 0s - loss: 1.8818 - accuracy: 0.3977 - val_loss: 1.6401 - val_accuracy: 0.5227 - 70ms/epoch - 12ms/step
Epoch 16/30
6/6 - 0s - loss: 1.8192 - accuracy: 0.4034 - val_loss: 1.5921 - val_accuracy: 0.5000 - 31ms/epoch - 5ms/step
Epoch 17/30
6/6 - 1s - loss: 1.7419 - accuracy: 0.4091 - val_loss: 1.5721 - val_accuracy: 0.5000 - 1s/epoch - 219ms/step
Epoch 18/30
6/6 - 1s - loss: 1.7478 - accuracy: 0.4091 - val_loss: 1.5182 - val_accuracy: 0.3409 - 1s/epoch - 218ms/step
Epoch 19/30
6/6 - 1s - loss: 1.7257 - accuracy: 0.3920 - val_loss: 1.5010 - val_accuracy: 0.5000 - 1s/epoch - 212ms/step
Epoch 20/30
6/6 - 2s - loss: 1.7082 - accuracy: 0.4432 - val_loss: 1.4494 - val_accuracy: 0.5227 - 2s/epoch - 264ms/step
Epoch 21/30
6/6 - 0s - loss: 1.6810 - accuracy: 0.4545 - val_loss: 1.4682 - val_accuracy: 0.5000 - 87ms/epoch - 15ms/step
Epoch 22/30
6/6 - 0s - loss: 1.6408 - accuracy: 0.4261 - val_loss: 1.4653 - val_accuracy: 0.5000 - 27ms/epoch - 5ms/step
Epoch 23/30
6/6 - 0s - loss: 1.6344 - accuracy: 0.4318 - val_loss: 1.4515 - val_accuracy: 0.4773 - 67ms/epoch - 11ms/step
Epoch 24/30
Restoring model weights from the end of the best epoch: 14.
6/6 - 1s - loss: 1.6316 - accuracy: 0.4148 - val_loss: 1.4224 - val_accuracy: 0.5000 - 1s/epoch - 224ms/step
Epoch 00024: early stopping
Running quantization-aware training OK
Finished training
Saving best performing model…
Saving best performing model OK
Converting TensorFlow Lite float32 model…
Converting TensorFlow Lite int8 quantized model…
Converting to Akida model…
Converting to Akida model OK
Model Summary
Input shape Output shape Sequences Layers
[1, 1, 39] [1, 1, 4] 2 4
SW/dense (Software)
Layer (type) Output shape Kernel shape
dense (Fully.) [1, 1, 20] (1, 1, 39, 20)
HW/dense_1-y_pred (Hardware) - size: 1432 bytes
Layer (type) Output shape Kernel shape NPs
dense_1 (Fully.) [1, 1, 10] (1, 1, 20, 10) 1
y_pred (Fully.) [1, 1, 4] (1, 1, 10, 4) 1
Saving Akida model…
Saving Akida model OK…
Loading data for profiling…
Loading data for profiling OK
Creating embeddings…
[ 0/220] Creating embeddings…
[220/220] Creating embeddings…
Creating embeddings OK (took 2 seconds)
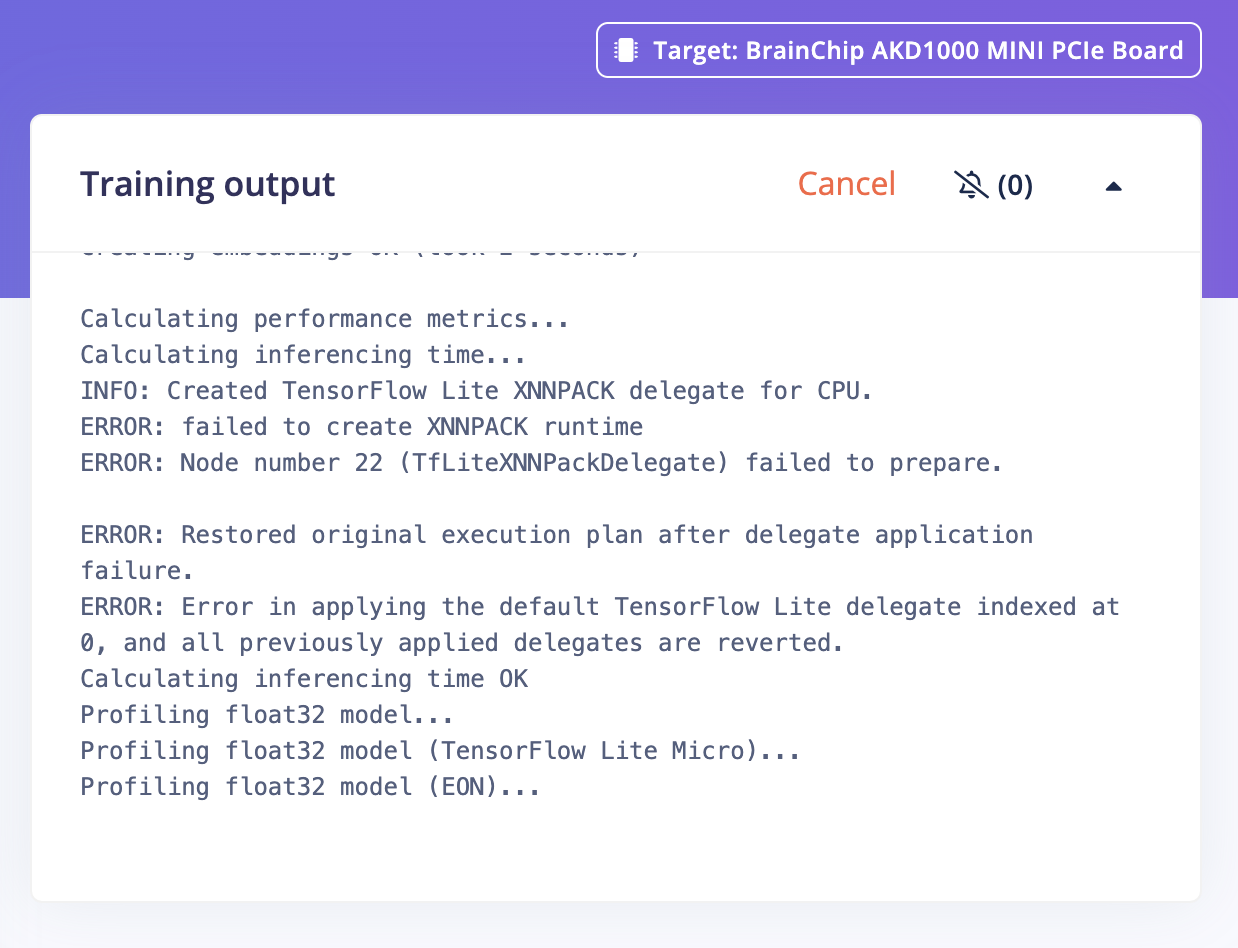
Calculating performance metrics…
Calculating inferencing time…
INFO: Created TensorFlow Lite XNNPACK delegate for CPU.
ERROR: failed to create XNNPACK runtime
ERROR: Node number 22 (TfLiteXNNPackDelegate) failed to prepare.
ERROR: Restored original execution plan after delegate application failure.
ERROR: Error in applying the default TensorFlow Lite delegate indexed at 0, and all previously applied delegates are reverted.
Calculating inferencing time OK
Profiling float32 model…
Profiling float32 model (TensorFlow Lite Micro)…
Profiling float32 model (EON)…
Profiling int8 model…
Profiling int8 model (TensorFlow Lite Micro)…
Profiling int8 model (EON)…
Attached to job 8293204…
What might be the issue?