Hi
I am using a Open MV H7 Plus and currently following their and your tutorials to create a trained data set that can be redeployed onto the OpenMV H7 or some other processor
I am working on an mobile robot avoidance project and would like to identify people, tree trunks, grass, fallen branches. Later on I would expand the classes to animals, children etc if successful
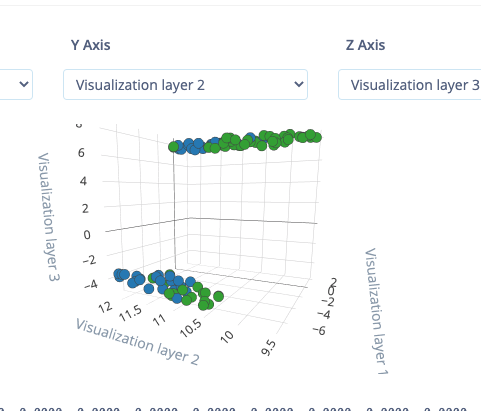
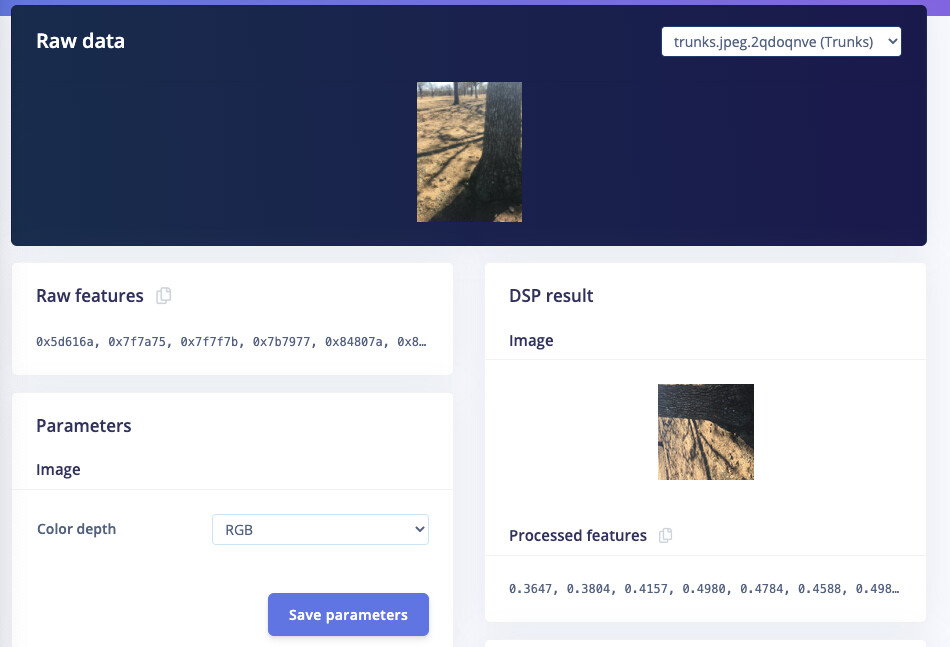
My approach would be to set up 4 classes, take say 100 pictures of each class then use your platform to do the rest.
I have notice in your tutorials you only use 2 classes. (coffee/lamp) or (lamp/plant). Still not quite sure the difference between the 2 tutorials? Can you please explain.
Is the difference due to the labelling ? ie in the lamp/coffee you had both objects in the same image
For each class I would take pictures at different distances from the object, angles, times of day, times of year, different lighting conditions. My default is grass. ie when I only see grass I am happy and when I see trees, branches or people then I need to take some action. Not sure what happens when we get grass and a tree? or human and grass?
Bearing in mind the above what should I do to maximise my chances of success?
Use a different deployment processor like the Nvidia boards
I may also use my mobil phone. Can I mix MV data and phone data sets.
I do know that I can add more images later on
Also should take pictures of multiple objects like people, grass and a tree?
Can you recomed any reading. Not interested in the nuts and bolts just implementation
regards and thanks for your great efforts
Max