Any future support for the Maixduino from Sipeed? I think it has a lot of great hardware that would be perfect for Edge Impulse. I purchased a few of these.
With that said, the mic on this board sends data to the RISC V processor via PCM. I only found examples on the internet using PDM mics and Edge Impulse. Can I feed the PCM straight into the static buffer?
It uses DMA and a buffer. So when it is full it will pull an interupt then I send it to the static buffer for classification. I’m thinking that is the way that works if I’m not mistaken?
This might be a silly question but if the training data I used to create the model were only 1 second long does it matter how long the the original signal from the DMA is?
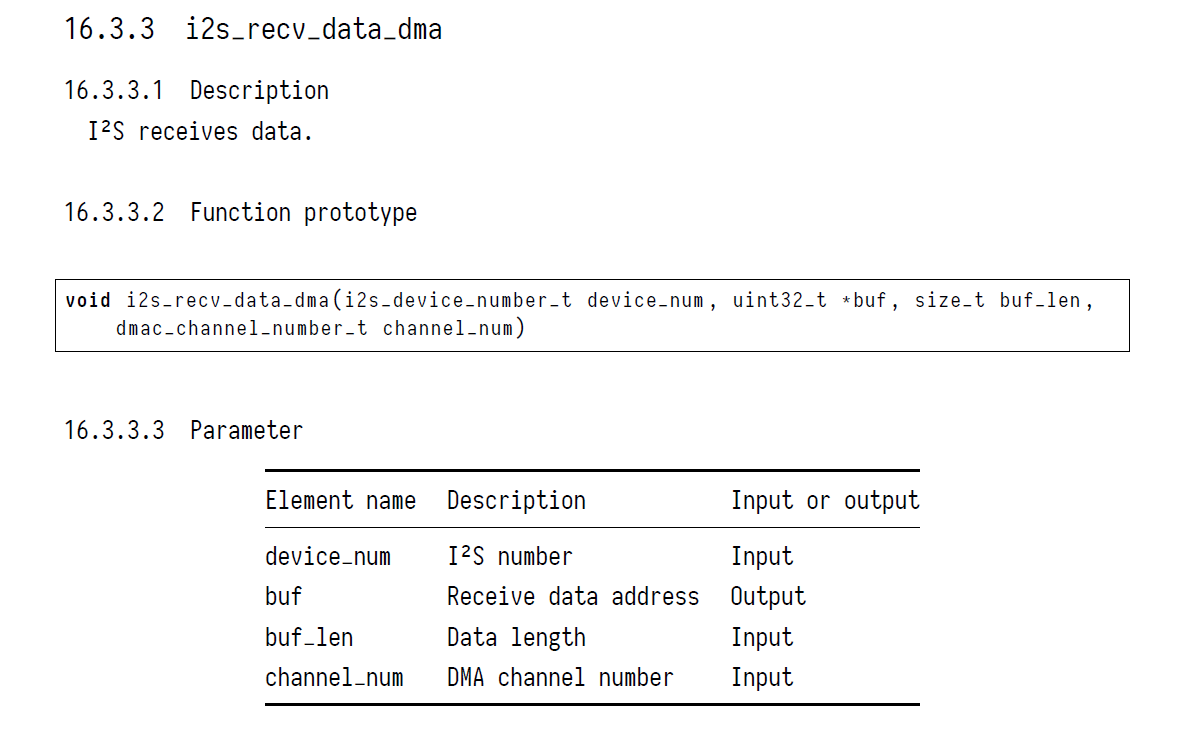
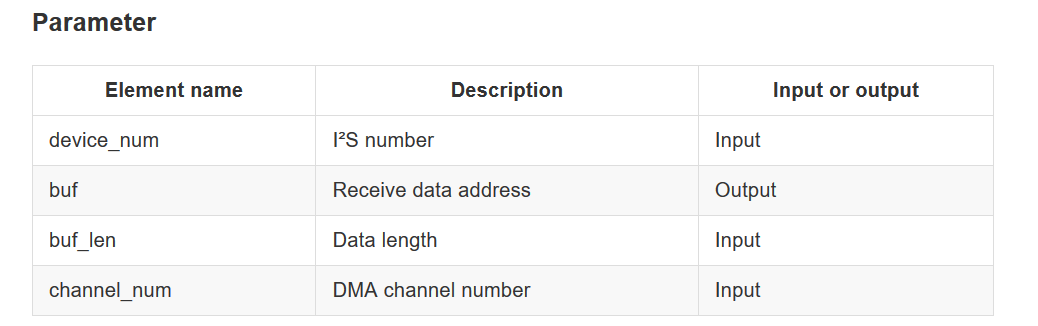
I have a few new questions since most of this is new to me. The SDK programming guide for the RISCV chip that I’m using has a function prototype as seen below in the image. I want to make sure I’m putting the correct information in the call back function. Also, the data word format from the MIC is MSB-first and it is 24 bits. Should I be bit shifting i2s_buf[i] to fit into type int16_t? Finally, should I2S_BUF_LEN = buf_len?
Yes, 24 bit audio need to be shifted to 16 bit. In the code you send the MSB part is now cutoff. I2S_BUF_LEN represents the number of samples. You should check if buf_len refers to the number of samples as well, or to the data length of the buffer in bytes.
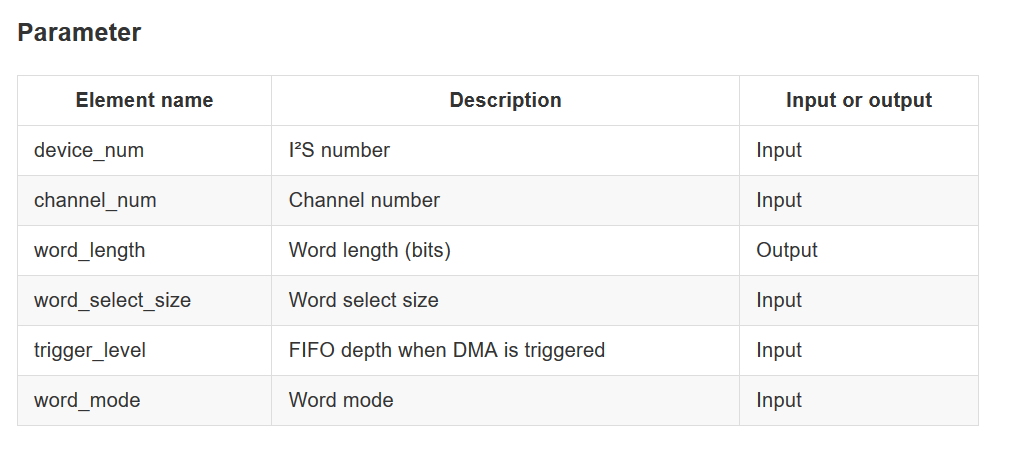
Also, I realized after copying some of the Sipeed’s code for the Maixduino that they set the receive channel configuration to 16 bit but the buffer is set to standard mode. I tried to find literature regarding what standard mode is for what they call “word mode” but couldn’t find anything. The alternatives to standard mode according to the SDK are right justified or left justified. With that said, do I still need to shift bits and do you know what standard mode is?
The default sample rate we use in the studio is 16000 Hz.
If you use the channel config you send, you will receive 16 bit sample data in a 32 bit word. Then you don’t need to shift. Don’t know what they mean by standard mode, but right justified mode should work.
I changed it to right justified and it no longer was able to classify anything so I left it in standard mode although I have no clue what that is.
I have a few more question. I cut my samples down to 1 sec long. When I run my model on the website or on the device it usually classify that sound wrong if the audio clip is 2 seconds. What am I doing wrong?
Also, I recorded 10 minutes of background noise. Do I need to cut this up in 1 second samples? If so is there any easy way to do that? “The Responding to your voice” video they were set to one second long.
I have a few more question. I cut my samples down to 1 sec long. When I run my model on the website or on the device it usually classify that sound wrong if the audio clip is 2 seconds. What am I doing wrong?
If your window length under Create impulse is set to 1s. then you should see multiple classifications under Live Classification, is this the case?
Also, I recorded 10 minutes of background noise. Do I need to cut this up in 1 second samples? If so is there any easy way to do that? “The Responding to your voice” video they were set to one second long.
No, just set window length to 1s and window increase to 1s under Create Impulse and it’ll automatically split samples up that are longer. This does not work well for events (like a keyword) because splitting up is based on timing rather than finding the event, but does work for noise. This is f.e. used here: https://docs.edgeimpulse.com/docs/audio-classification
Actually, I figured it out this morning. It was actually my model that was the problem. I watched your “Responding to your voice” video a bunch of times and realized that you checked marked Data Augmentation. So I did the same. That made a world of difference. I have some fine tuning to do but otherwise the model is working great.
I will keep my window length to 1 but set the increase to 1 and retest. It took me a while to figure out how everything works together. Thank you for answering my question.
This chip that I’m using has Knowledge Processing Unit (KPU, aka Neural network Processing Unit), Fast Fourier Transform (FFT) Accelerator, and is dual core. Do you know how I could utilize any of those to make my model better? I know your library basically does everything but I figure it I might be able to use one of those to make the model perform better.
Also, I read over the documentation but wasn’t sure if I just have to declare double buffers and library takes care of the rest or do have to fill each buffer manually with samples and put them through classifier?
Finally, I went through the documentation for the chip but I don’t see a way to end the interrupts or I2s on this chip. Do I need to the function “ei_microphone_inference_end” to free up the memory for running the classifier continously?
To use the KPU and FFT from the processor you have to replace the NN and FFT functions from our library with the KPU and FFT functions. As those functions run on a separate core and run a dedicated function the inference will run faster. The classifaction output should be the same.
The double buffers are needed to run the inference continuously. They are already declared in the sdk, you just have to connect the callback function audio_buffer_inference_callback() is called when new audio data is sampled.
If you can’t stop the I2S interrupt you can use a flag in the interrupt that prevents calling the callback function when inference is stopped.
Thank you both for the information. Yes, I put the interrupt callback function as audio_buffer_inference_callback() when the buffer is full so what your saying is the SDK handles the rest?
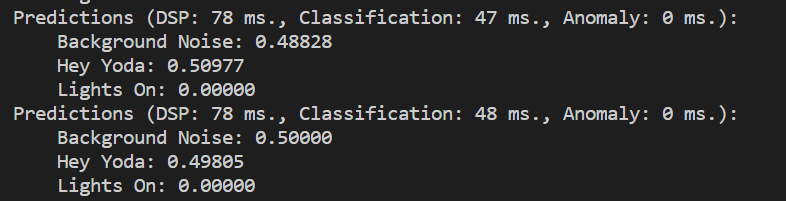
Also, is there something wrong with my model if the word classification is split up like below? Do I need more data as there is too much noise in the window or is my timing off?
Also, do you know any good books or references that dives deeply into KPU, FFT, or any advanced topics on microcontrollers? All the ones I’ve seen are for the basics and beginners.