Question/Issue: I’m following the steps in the Edge Impulse project example " Automated Inventory Management with Computer Vision" .
Instead of two objects, I’m trying to use object detection for three different products. I uploaded about 60 images that include a variation of the three labels I want to detect. In total, there are about 40 images for each label. When I train the model, I’m getting a very bad accuracy (40%). When I remove one of the labels, the accuracy raises to 80%. I’m using FOMO and the images are reduced in size to 96X96.
Any suggestions on what can be done to increase the accuracy?
I’m still learning and any hint would be really appreciated.
Project ID: Nur Siyam/Inventory v1
Context/Use case: I’m trying to create an inventory management system similar to this one: Automated Inventory Management with Computer Vision - Expert Projects
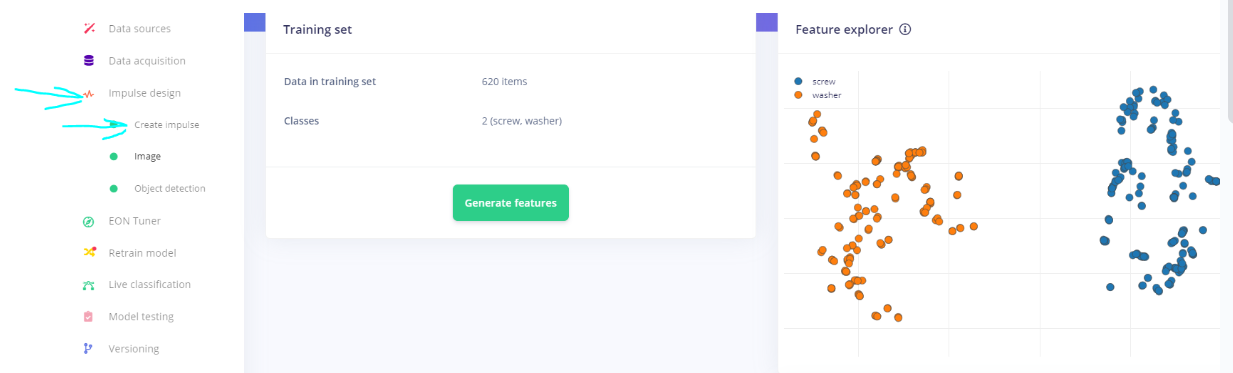
What does your Feature Explorer look like? Can you easily distinguish the Classes? If not then the ML Model will also have trouble (no magic here).
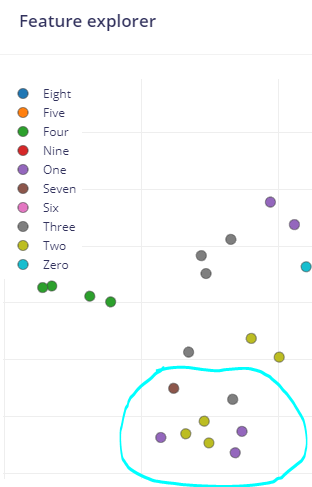
For example, the following image shows a FOMO model trained on images that have the numerals 0 to 9 within them. The Classes in the cyan colored circle are Classes {1,7,9}. Depending on how you write them and how legible your hand writing is these can all look similar. The Feature Explorer is grouping them together and is indicating they are the same object. One solution is to add more training data.
The following image shows have FOMO is easily seperating 2 different Classes:
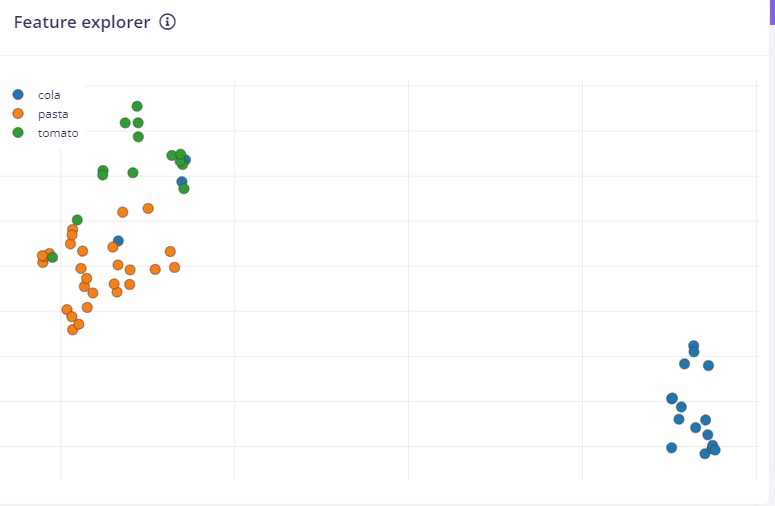
Thanks for the reply. I trained the model again and, surprisingly, I got 76% accuracy. This is not what I’m aiming for, but at least it is not 40% like before. The strange thing is that I did not change anything, I just trained the model again. It seems the issue is with the pasta, as the model is classifying it as background (85.7% of the time), which is decreasing the accuracy.
Here is the feature graph. It seems that the classes have distinguished features:
And here is how I was labeling the images:
At this point all I can say is “more data”…if you collect 2000 samples of each object and accuracy is poor then I’ll say keep collecting until you get 10000 Samples of each object. Then if accuracy is still poor we can discuss additional methods like data augmentation, photo collages, image filters and maybe even bring in more sensors like a FLIR camera.
Now it comes down to your use case. Will a robot go down the ailse, stop when it is over a X on the floor, then snap the photo with a flash (so you can control lighting)? You can passively employ your customers…maybe the image capture is a camera mounted on the customers cart so the images will be collect at random angles and lighting?
Rotate the products, change the lighting, don’t always center the products in the frame, lay the cola bottle on its side…let the Data Scientist come out of you.