I’ve trained up an object detection model (FOMO MobileNetV2 0.35). I downloaded the model with edge-impulse-linux-runner --download modelfile.eim to my x86 Linux machine, and I can process still images with python classify-image.py modelfile.eim image.jpg.
Given exactly the same image file, classify-image.py’s bounding boxes are different from the studio’s Model Testing results. The coordinates of the bounding boxes don’t match, and sometimes the number of bounding boxes don’t match as well.
classify-image.py writes the processed image, so I can tell that the preprocessing is working (grayscale, 600x600). I’ve also seen the related posts concerning int8/float32, e.g.
In the studio, I found the Deployment > C++ Library > Optimizations dialog. I selected Unoptimized (float32) , disabled the EON Compiler, and rebuilt – but it’s not clear to me how to propagate these changes to the downloaded modelfile.eim.
So my questions are:
why don’t the results match?
is the Python SDK a feasible route for deploying object detection for image files or should I stick with C++? I don’t need to process a camera feed; I thought testing with image files would be easier.
is there any way with the Python SDK to determine if the model is using int8 or float32?
Can you provide your example image.jpg so I can try replicating your results?
The Python SDK is an easy route for deploying any Edge Impulse model to Linux-based computers (including single board computers as well as macOS). For deploying to other embedded systems (such as microcontrollers), the C++ SDK route is the preferred option.
By default, the edge-impulse-linux-runner command will download the float32 version of the model. You can download the int8 version by using the --quantized flag. Type edge-impulse-linux-runner --help to see the available options.
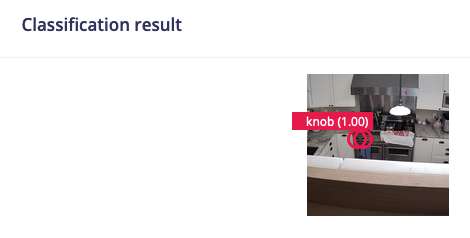
This image is also in my test data set. When I process it via Model Testing > Show Classification, the model identifies two “knobs” with bounding boxes:
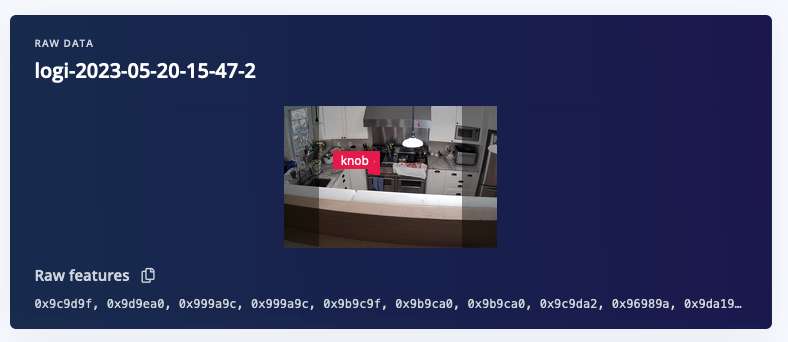
According to the Edge Impulse C++ Tutorial, I should be able to copy-paste the “raw features” into a C++ array and run classification on this data. This procedure doesn’t work in my case, however, because the array is too large with >= (660*660) elements (I attempted to copy-paste, but it failed).
In any case, I’m assuming that the array of raw features represents the RGB values which go into the preprocessing front-end of my impulse, i.e. the input to the image preprocessing.
I wrote code to read logi-2023-05-20-15-47-2.jpg, convert the RGB pixels to packed 0xRRGGBB values, and print them. And I get different results from the raw features! Based on the raw features, the first couple of pixels should be 0x706a65, 0x716b65. Instead, I’m seeing 0x91a7a4, 0x92a8a5.
Note that my input image has dimensions (1000 x 666). I’m guessing that my deployed model is actually expecting a cropped, square input image–this explains both the incorrect number and placement of the output bounding boxes. This is despite the Edge Impulse Studio accepting and processing the rectangular images.
Question: does the C++/python deployment not perform image cropping and/or resizing?
@louis Correct me if I am wrong but if the Impulse Design - Create Impulse - Image Data block has an Image Width = 96 and Image Height = 96, then the deployed C++ library will crop or black fill (upsize) the image to 96x96, correct?
Having downloaded the C++ source code for my impulse, I can see that EI_CLASSIFIER_DSP_INPUT_FRAME_SIZE = 435600 = 660x660. I think this means that the library code expects input images of size 660x660, even though I trained with a dataset containing non-square 1000x666 images.
It’s curious that the python deployment doesn’t assert or complain when I give it a non-square image.
I used imagemagick to crop my images to the expected size, then fed it into my python implementation. This time it identifies the correct number of bounding boxes, but the bounding boxes are still incorrectly located.
I also replicated the same experiment with the C++ library (by reading the image into an RGB array, then calling run_classifier()) and got similar results.
I suspect that the problem is that my original data set consisted of non-square images, so I’ll upload a new set of square images, tag them, and try again…
@MMarcial: what do you expect to happen if the Image Data block uses Image Width = 96, Image Height = 96, but the dataset contains images with dimensions Width=150 height = 100?
When inferencing via res = runner.classify(features), this statement does not know if it is classifying an image or classifying an image segmentation (FOMO) so the Python code will not complain
If you resize you images then the bounding box labels file will need to have its contents adjusted accordiningly. Depending on how you resized, you may be able to programatically run the JSON FOMO labels file thru a script to adjust the values therein.
Also note that FOMO should to be fed square images.
classify-image.py eventually calls cv2.resize() so the input image will be downsized or upsized based on the Impulse design.
Just curious here, but is the Impulse design in the Studio also 660x660?
hi @MMarcial: A question–when using FOMO, do the square image’s dimensions need to be an integer multiple of 8? In the FOMO article, the dimensions are all integer multiple of 8 (e.g. 160x160, 320x320).
I’m using images with dimensions 660x660, and the returned centroid coordinates are inexplicably offset from the actual objects, for example:
In your case of 660x660, my guess is FOMO will throw out the 4 pixels along one vertical side and one horizontal side. It would be nice if the FOMO “pixel counter” would find the edge, in this case 4 pixels and then back into the main image by 4 pixels so that it gets the desired 8 pixels. This is a boundary condition so it will only affect FOMO objects at the very edge of the image.
FOMO BBs are referenced to the top left corner.
Since your BBs are offset, you should plot the training Samples with BBs and see where they land just to rule out its not a training issue.
After resizing my images to 640x640 (an integer multiple of 8), uploading them, retagging them, and then adjusting the Impulse Design image parameters to match, I finally got my local results to match the EI Studio results.
I tried to move the MobileNet cut point to increase the heatmap grid points, but the resulting model never trained up–I never got a F1 score > 0.0
it would be VERY USEFUL if output images in the EI Studio’s Live Classification page could be displayed at full resolution, or even downloaded. Currently, the downsampled images are too small, especially if the FOMO objects are small or close together. I had trouble telling if the bounding boxes were correct.
Not that python pre-allocates memory, as prudent, when the instantiated means, for locomotive, and fore-front development, as standard recluse to java development, as reinstated; nay the development consist in code practice, of computing logic, as computer science, as elective.