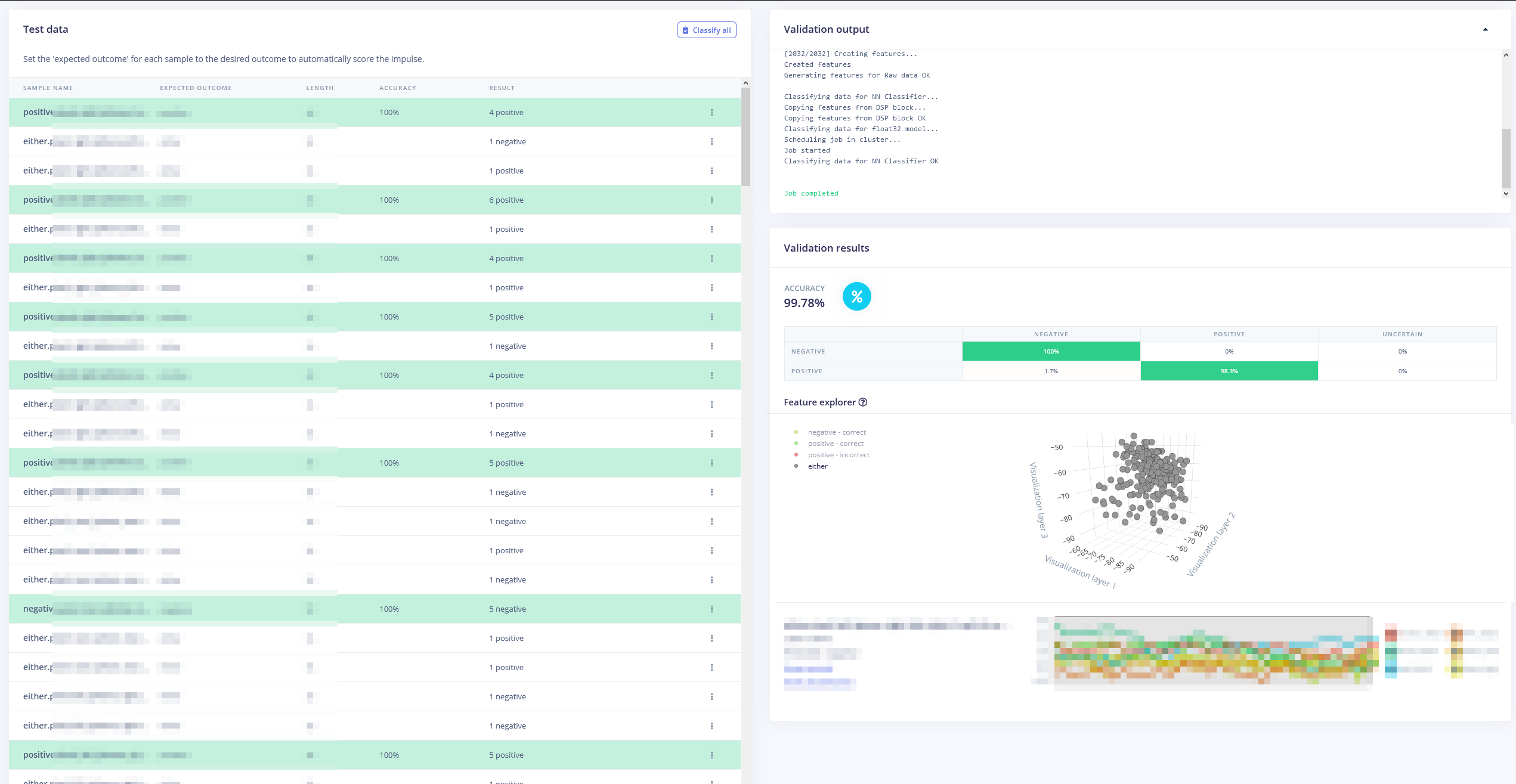
Yeah, this is by design. If you have labels that are not in the training dataset they are omitted from the confusion matrix as they don’t give any meaningful information. The classification results and the gray dots in the feature explorer are (hopefully) helpful to set the right labels for this data.
Well it’s always going to show - in that case, there’s no data to cross-reference there, nor do we know if this is correct or not. @dansitu probably has better a idea on why
This is interesting! Just so I understand the whole context, what’s the motivation behind using the “either” class during testing vs. labelling the “either” samples with either “positive” or “negative”?
One thing we’re looking at currently is allowing users to specify metadata for samples, so if there are certain samples of interest you could add a shared metadata tag and see how they perform as a category. Would this help solve the problem you are looking to solve with the “either” class?