Hi,
I have to say I’m new to ML and Edge impulse, but I love how easy it is to train a model with this tool.
But now I ran into a problem and don’t know how to solve it:
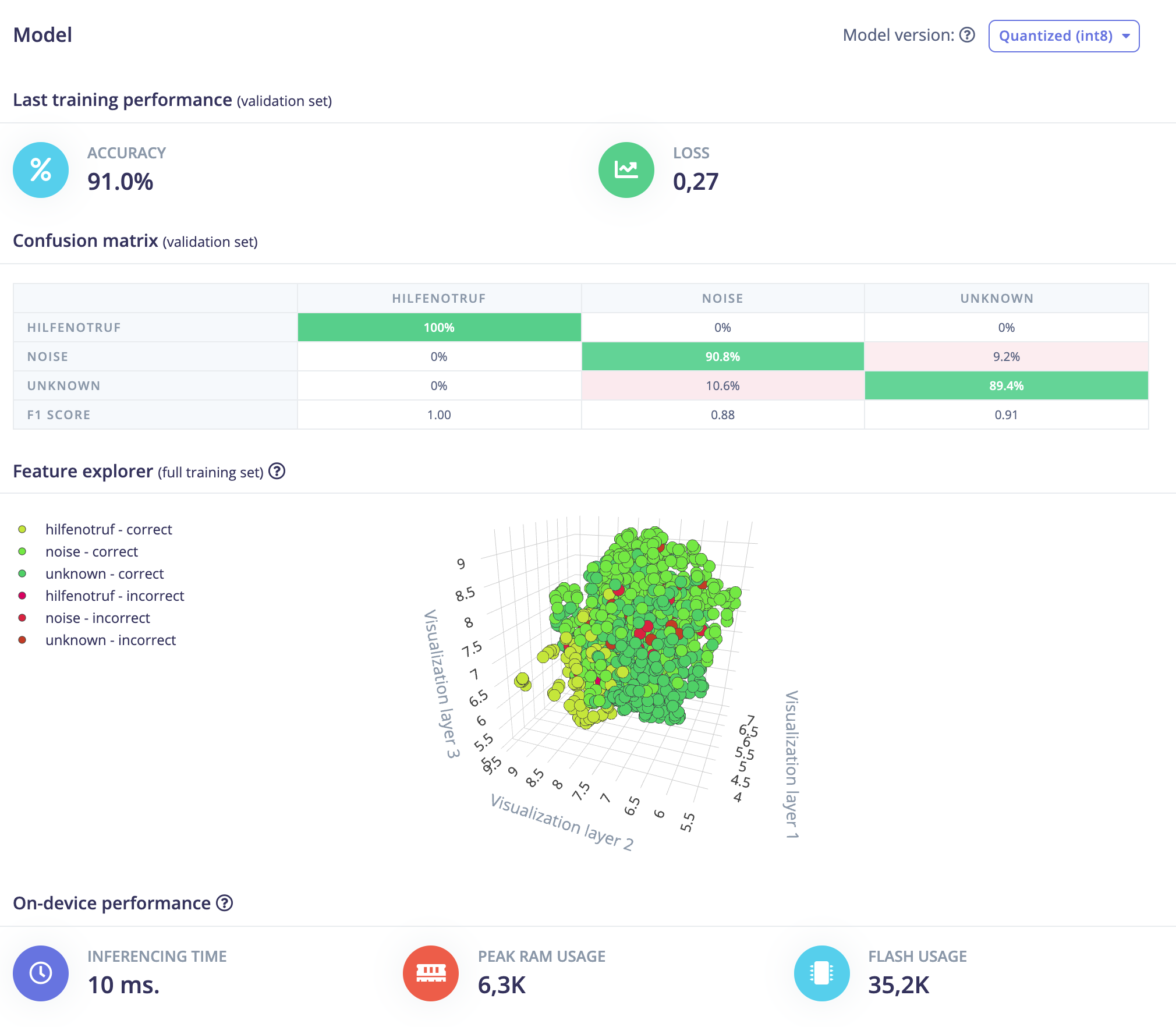
After training my keyword spotting model It outputs an accuracy of >90%, which is good I think?
Also additional training files get classified mostly correct.
However, when I put it on my Arduino BLE Sense 33, I outputs probabilities for my trained keywords “Hilfe Notruf” (german) close to 1 (mostly 0.9 +) even if I don’t say a word. The same goes for the live classification on mobile phone / web app.
What am I doing wrong?
I uploaded a picture of my training results.
Can you give me some hints of what I can do?
I took a look at your project and tried it out on my smartphone. It looks like it defaults to “hilfe notruf” during inference. You can get the probabilities on the other labels to go up if you provide noise (e.g. whistling) or say other words (especially those that match the English words used in the “unknown” category).
I might recommend trying a few things:
Extend the samples in the noise and unknown categories to be 2 sec instead of 1 sec (so that they match the sample length of your target keyword)
Collect additional background noise from a variety of sources. It sounds like you’re just using one environmental sound right now for all your noise samples (let me know if that is incorrect).