I’m trying to perform Grad-CAM to have better insights of my image classification model.
To do so, I’m following an outstanding workshop from Shawn Hymel that I’ve found on GitHub. ei-workshop-image-data-augmentation/workshop_01_saliency_and_grad_cam.ipynb at master · ShawnHymel/ei-workshop-image-data-augmentation · GitHub
While I was following the steps I realized that I needed to upload the .h5 file from my Edge Impulse project to move forward instead of using the SavedModel file that was suggested.
By doing that I could plot the Saliency Map but I’m stuck with the path to get the last convolutional layer due that the model has them inside of what seems to call a functional engine.
This is the main model structure as seen in Netron.app
If I click into the function button and I move downwards this is what I reach
Is there any modification that I could do to the code to access the last convolutional layer (model/Conv_1) of my model?
Thanks in advance
Dislcaimer: To be fair with the instructions, I just realized that are written for a NN Classifier project whereas I have a Transfer Learning one.
What changes can I do to still perform the Grad-CAM tests?
Hi @Lesurfe,
This is a really good question…I have not tried the visualization techniques with transfer learning models (e.g. MobileNet). As you have discovered, I doubt they would work out of the box  If I get some time, I’d like to get it working for MobileNet, but it’s not something I can do right now. I filed an issue on GitHub (Get visualizations (GradCAM and saliency maps) working for MobileNet · Issue #1 · ShawnHymel/ei-workshop-image-data-augmentation · GitHub) to remind myself to look into it. If you do manage to get it working, please let me know how!
If I get some time, I’d like to get it working for MobileNet, but it’s not something I can do right now. I filed an issue on GitHub (Get visualizations (GradCAM and saliency maps) working for MobileNet · Issue #1 · ShawnHymel/ei-workshop-image-data-augmentation · GitHub) to remind myself to look into it. If you do manage to get it working, please let me know how!
Hi @shawn_edgeimpulse thank you so much for your reply!!
I’ve been doing a lot of thinking and I came up with a solution.
Grad-CAM code is looking for the last Conv2D layer, but is not finding it because in the model definition step instead of adding layer by layer we are importing the whole MobileNet model as a layer. Grad-CAM doesn’t know how to manage that.
Therefore modifications in the Grad-CAM code might be needed to allow the program to find the last Conv2D layer of the MobileNet CNN… OR we could manually add additional “neutral” Conv2D layers to the model by editing the code in Keras (expert) mode. The intention of that would be to keep the CNN as it is, but also to allow the Grad-CAM code to find the last Conv2D layer!
So, I edited the Edge Impulse code in Keras (expert) mode by:
-
Added a Conv2D layer with ReLU activation (for values greater than 0 returns the same value, which works perfect for a “neutral” layer)
-
After the Conv2D layer I added a MaxPooling2D with a pool_size of 1 and strides of 1 (the max value of a single number is that number which works perfect for a “neutral” layer)
-
Importing MaxPooling2D function
Thus, model definition lines now look as follow:
model = Sequential()
model.add(InputLayer(input_shape=INPUT_SHAPE, name=‘x_input’))
last_layer_index = -3
model.add(Model(inputs=base_model.inputs, outputs=base_model.layers[last_layer_index].output))
model.add(Conv2D(16, kernel_size=3, activation=‘relu’, kernel_constraint=tf.keras.constraints.MaxNorm(1), padding=‘same’, name=“last_2dconv_layer”))
model.add(MaxPooling2D(pool_size = 1, strides = 1))
model.add(Reshape((-1, model.layers[-1].output.shape[3])))
model.add(Dense(16, activation=‘relu’))
model.add(Dropout(0.1))
model.add(Flatten())
model.add(Dense(classes, activation=‘softmax’))
To wrap it up I have two last comments:
- Model accuracy has not been affected by these changes
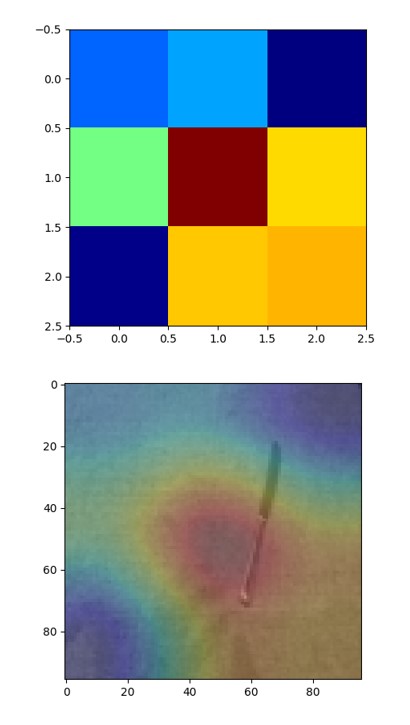
- Even though I could see the Grad-CAM images they do not look like as gracefully as I expected (see images below for heatmap and big_heatmap plt.imshow()
Hi @Lesurfe,
You can use the get_layer() method with an integer parameter to select the index of a layer, so you don’t necessarily need to pass it the name of a Conv2D layer: The Model class. I’m not sure how that works with the function layer that you mentioned, but it might be a good start to being able to remove certain layers.