Question/Issue:
Hello,
I am currently working on deploying an Edge Impulse model within a micro-ROS node on a Linux machine
Ubuntu 22.04, which will later be deployed on a Renesas RA6M5 MCU. I have successfully tested the standalone inferencing example, where the model correctly processes image data. However, I am encountering issues with correctly filling the input buffer to pass to the classifier in my micro-ROS node setup.
I want to use the built in image processing functions provided by the C++ SDK. I have been using the following example to resize the image before sending it to run_classifier function. However I recieve a segmentation fault in the function cropImage(…). I am using the following code as example: GitHub - edgeimpulse/example-resize-image: Example of using SDK to resize images before run_classifier
Project ID:
439843
Context/Use case:
- Micro-ROS Node: Deployed on a Linux machine Ubuntu 22.04, communicates with another ROS node via a micro-ROS agent.
- Hardware Target: The final deployment will be on a Renesas RA6M5 MCU.
- Video Source: The video frames are published by a ROS node, captured via OpenCV, and converted to ROS
sensor_msgs/msg/Imagemessages.
Steps Taken:
- Implemented a micro-ROS node that subscribes to video frames and attempts to convert the frame data into an input buffer for the Edge Impulse classifier.
- Used OpenCV on the ROS node to capture video, convert frames to RGB format, and publish them as
sensor_msgs/msg/Imagemessages. - Developed a callback function in the micro-ROS node to process the incoming frames and prepare the input buffer for classification.
Expected Outcome:
The incoming frames should be processed correctly, and the input buffer should match the expected format and size
Actual Outcome:
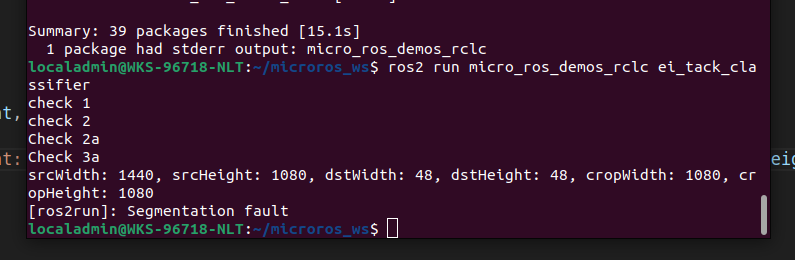
Reproducibility:
Always
MicroROS code:
#include <rcl/rcl.h>
#include <rclc/rclc.h>
#include <rclc/executor.h>
#include <std_msgs/msg/string.h>
#include <sensor_msgs/msg/image.h>
#include "edge-impulse-sdk/dsp/image/processing.hpp"
#include "edge-impulse-sdk/classifier/ei_run_classifier.h"
#include <stdint.h>
#include <stdio.h>
// Raw features
static uint8_t resized_image[EI_CLASSIFIER_INPUT_WIDTH * EI_CLASSIFIER_INPUT_HEIGHT * 3] = {0};
// ROS publisher
rcl_publisher_t inference_publisher;
// Function to convert image data to float array for classifier
static int get_signal_data(size_t offset, size_t length, float *out_ptr);
// Forward declarations
void image_callback(const void *msgin);
void publish_classification_result(rcl_publisher_t *publisher, const char *result);
using namespace ei::image::processing;
int main(int argc, char **argv) {
// Initialize ROS 2
rcl_ret_t rc;
rcl_allocator_t allocator = rcl_get_default_allocator();
rclc_support_t support;
rcl_node_t node;
rcl_subscription_t image_subscription;
sensor_msgs__msg__Image image_message; // Declare an instance of the message type
rc = rclc_support_init(&support, argc, argv, &allocator);
rc += rclc_node_init_default(&node, "tack_classifier_node", "", &support);
// Initialize publisher
rc += rclc_publisher_init_default(
&inference_publisher,
&node,
ROSIDL_GET_MSG_TYPE_SUPPORT(std_msgs, msg, String),
"inference_stream");
// Initialize subscriber for images
rc += rclc_subscription_init_default(
&image_subscription,
&node,
ROSIDL_GET_MSG_TYPE_SUPPORT(sensor_msgs, msg, Image),
"video_frames");
// Initialize executor
rclc_executor_t executor;
rclc_executor_init(&executor, &support.context, 1, &allocator);
rclc_executor_add_subscription(
&executor,
&image_subscription,
&image_message, // Pass the instance of message type
image_callback, // Changed to function pointer
ON_NEW_DATA);
// Spin the executor (equivalent to rclpy.spin)
rclc_executor_spin(&executor);
// Clean up resources
rcl_subscription_fini(&image_subscription, &node);
rcl_publisher_fini(&inference_publisher, &node);
rclc_executor_fini(&executor);
rcl_node_fini(&node);
rclc_support_fini(&support);
return 0;
}
// Image callback function to process video frames
void image_callback(const void *msgin) {
EI_IMPULSE_ERROR res; // Return code from inference
printf("check 1\n");
const sensor_msgs__msg__Image *image_msg = (const sensor_msgs__msg__Image *)msgin;
// Check encoding (assuming "rgb8" format)
if (strcmp(image_msg->encoding.data, "rgb8") != 0) {
printf("Unsupported image encoding: %s\n", image_msg->encoding.data);
return;
}
printf("check 2\n");
// Resize the image
int res_int = ei::image::processing::resize_image_using_mode(
image_msg->data.data,
image_msg->width,
image_msg->height,
resized_image,
EI_CLASSIFIER_INPUT_WIDTH,
EI_CLASSIFIER_INPUT_HEIGHT,
3, // RGB888
EI_CLASSIFIER_RESIZE_MODE);
printf("check 3\n");
if (res_int != 0) {
printf("Error resizing image: %d\n", res);
return;
}
// Prepare the signal
signal_t signal = {
.get_data = &get_signal_data, // Initialize 'get_data' first
.total_length = EI_CLASSIFIER_DSP_INPUT_FRAME_SIZE // Initialize 'total_length' second
};
printf("check 4\n");
ei_impulse_result_t result = {0};
// Classify image using Edge Impulse
res = run_classifier(&signal, &result, false);
printf("check 5\n");
if (res == EI_IMPULSE_OK) {
// Process results and create a classification string
char result_str[1024];
snprintf(result_str, sizeof(result_str), "Detected: %s (%.2f)", result.classification[0].label, result.classification[0].value);
// Publish the result
publish_classification_result(&inference_publisher, result_str);
}
else
printf("Error classifying the image\n");
printf("check 6\n");
}
// Callback: fill a section of the out_ptr buffer when requested
static int get_signal_data(size_t offset, size_t length, float *out_ptr) {
// we already have a RGB888 buffer, so recalculate offset into pixel index
size_t pixel_ix = offset * 3;
size_t out_ptr_ix = 0;
while (length != 0) {
// pixels are written into the mantissa of the float
out_ptr[out_ptr_ix] = (resized_image[pixel_ix] << 16) +
(resized_image[pixel_ix + 1] << 8) +
resized_image[pixel_ix + 2];
// go to the next pixel
out_ptr_ix++;
pixel_ix += 3;
length--;
}
return EIDSP_OK;
}
// Function to publish classification result
void publish_classification_result(rcl_publisher_t *publisher, const char *result) {
std_msgs__msg__String msg;
size_t result_length = strlen(result);
msg.data.data = (char *)malloc(result_length + 1); // Allocate memory for the string
if (msg.data.data == NULL) {
printf("Failed to allocate memory for message data\n");
return;
}
strcpy(msg.data.data, result); // Copy the string into the allocated memory
msg.data.size = result_length;
msg.data.capacity = result_length + 1;
rcl_publish(publisher, &msg, NULL);
// Free allocated memory after publishing
free(msg.data.data);
}
**Publisher Code: **
import rclpy
from rclpy.node import Node
import cv2
from cv_bridge import CvBridge
from sensor_msgs.msg import Image
class VideoPublisher(Node):
def __init__(self):
super().__init__('video_publisher')
# Declare the video path parameter
self.declare_parameter('video_path', '')
# Wait until a valid video path is provided
self.video_path = self.get_parameter('video_path').get_parameter_value().string_value
while not self.video_path:
self.get_logger().info('Waiting for video path to be provided...')
rclpy.spin_once(self)
self.video_path = self.get_parameter('video_path').get_parameter_value().string_value
# Initialize the video capture with the provided path
self.cap = cv2.VideoCapture(self.video_path)
if not self.cap.isOpened():
self.get_logger().error(f"Could not open video file: {self.video_path}")
rclpy.shutdown()
return
# Create a publisher
self.publisher_ = self.create_publisher(Image, 'video_frames', 10)
# Initialize the CvBridge
self.bridge = CvBridge()
# Set the timer period for 30 FPS
timer_period = 1.0 / 30.0 # 30 FPS
self.timer = self.create_timer(timer_period, self.timer_callback)
def timer_callback(self):
# Capture a frame from the video
ret, frame = self.cap.read()
if not ret:
self.get_logger().info('Video stream ended.')
self.cap.release()
rclpy.shutdown()
return
# Convert the OpenCV BGR image to RGB
rgb_frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
self.get_logger().info('Converted to RGB')
# Display the frame that is being published
cv2.imshow("Published Frame", rgb_frame)
cv2.waitKey(1) # Allows the image to be displayed properly
# Convert the RGB image to a ROS Image message
image_message = self.bridge.cv2_to_imgmsg(rgb_frame, encoding='rgb8')
# Publish the Image message
self.publisher_.publish(image_message)
self.get_logger().info('Publishing video frame')
def main(args=None):
rclpy.init(args=args)
video_publisher = VideoPublisher()
rclpy.spin(video_publisher)
video_publisher.destroy_node()
rclpy.shutdown()
# Close OpenCV windows
cv2.destroyAllWindows()
if __name__ == '__main__':
main()
Additional Information:
- How can I correctly convert and format the incoming image data from the
sensor_msgs/msg/Imageto match the expected input buffer format for the Edge Impulse classifier? - Is there a more efficient way to handle RGB image data and convert it to the required format for inference?