Hi everyone,
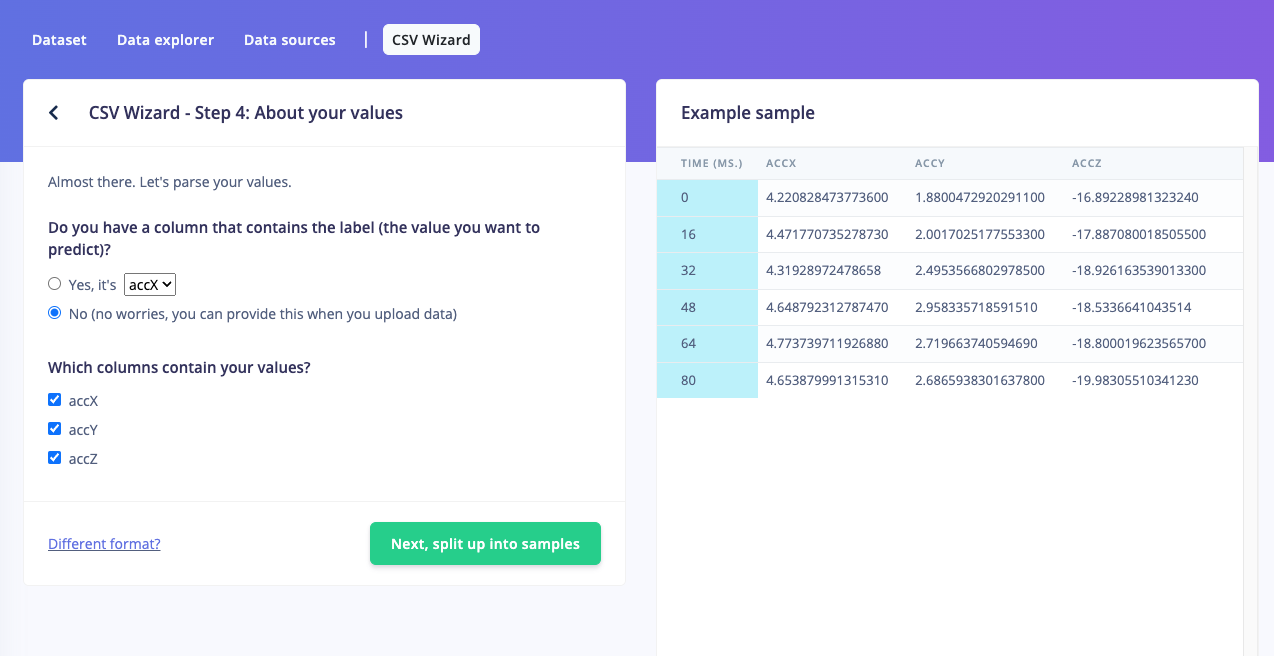
I’m currently facing an issue with the automatic labeling feature. I have a CSV file that I believe follows the guidelines mentioned in the documentation for importing CSV data with <label>.<unique-id>.csv format. Here’s an example filename:
tip_act.2023-04-08_14-17-04.csv.
However, when I upload the CSV file, the automatic labeling feature doesn’t seem to be identifying tip_act as the label. Instead, it uses the first entry in the label column of the CSV. I’m not sure what I’m doing wrong, or if there’s an additional step that I need to take in order to ensure that the automatic labeling feature works properly.
Even when I select the manual Enter label method and enter for one dataset a name, the name is not used, and it uses the first entry in the label column of the CSV.
Thank you in advance!