I need some help with an image recognition project using a Nano 33 BLE Sense and attached OV7670 camera module
The project ID is 270080
I have successfully interfaced the OV7670 camera with the Nano 33 BLE Sense and after flashing the Nano with the correct firmware, was able to connect the Nano to Edge Impulse and access the camera
From there, I captured a training and testing set of images of three objects. After some experimentation, I settled on the following parameters for the project:
Impulse design: Image data 96x96, Image and Transfer Learning (Images)
Color depth set to Greyscale
After feature generation and training, the transfer learning on device performance
Inferencing Time 1883 ms
Peak RAM usage 333.7 K
Flash usage 579.5 K
I compiled the binary firmware and flashed it to the Nano 33. Firmware statistics seemed within Nano 33 capabilities
Sketch uses 837704 (85%) of program storage space
Global Variables use 67800 (25%) of dynamic memory
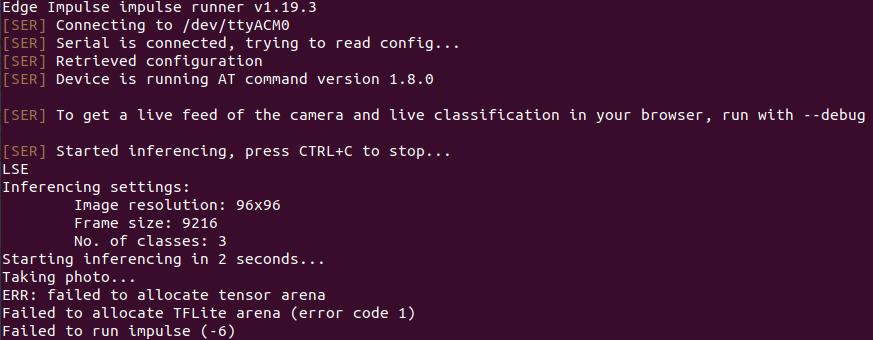
However, when I use edge-impulse-run-impulse, the following error message results; “failed to allocate tensor area”
If I take the other approach and use the arduino library, I get an error “failed to create buf_mem”
I am guessing that these errors result from insufficient memory on the Nano 33, because the buffer required to read in camera data is declared dynamically at runtime, or the array required to hold the feature set for inferencing is declared dynamically.
Any suggestions on how the model or data could be adjusted to fit into memory? Thanks
Hi @kevinjpower,
As you have correctly assessed: yes, the TensorFlow system dynamically allocates memory (the “arena”) to perform inference with the model. So, even though the firmware stats show that your predicted memory usage is OK, it is often quite inaccurate when dealing with TensorFlow Lite Micro allocation. As a result, you might deploy a model thinking the RAM/ROM usage is OK only to find it fail in runtime.
In my experience, 96x96 is too big for the Nano 33. I usually stick with something much smaller (e.g. 28x28 or 32x32). 64x64 is pushing it, but it might work. Here is an example of a project where I trained a simple image classifier to be deployed to the Nano 33: electronic-components-cnn-augmented - Dashboard - Edge Impulse
2 Likes
Hi @shawn_edgeimpulse,
Thanks for the prompt answer. Three questions that arise from your answer:
- In studying your sample electronic components classifier project, I see that it includes a Neural Network (Keras) as the network training block. I don’t appear to have that option in my choices so am assuming that it is unavailable in my account or has been discontinued. The option available to me that appears to be the best is Transfer Learning (Images). What is the difference between these two and is one better or worse/
- I am assuming that you can feed any image size into the input block (say 160 x 120) and it will be resized and cropped to the specified dimensions of the input block (say 32x32). These 32x32 images will then be used to train the network. When it comes to inferencing on the Nano33 BLE, you can use any image size (say 176x144) and it will be resized to 32x32 before been analyzed by the network. Is this correct?
- The images that belong to the training and test data can be .jpg or .png files. I assume that these formats are converted to raw format by the Input and Processing block. I assume that this also occurs during inferencing on the Nano33 BLE?
Thanks
I managed to get the project to work reasonably well.
The project ID is 271392
The pertinent parameters associated with the project as follows:
- 96x96 Greyscale, Fit longest axis (after reading the explanation post, I may change this to squash)
- Transfer learning (images) using Mobile Net V1 96x96 0.25. This network architecture indicates 105 K RAM and 301 K ROM.
- The input layer is 9216 features (96x96 one byte per pixel)
- Target Arduino Nano 33 BLE Sense (Cortex-MF4 64 MHz)
- 241 training pics, 61 test pics split into three labels/categories
After training the network with the following results:
- Inferencing 1131 ms
- Peak RAM 124.3 K
- Flash Usage 307.2 K
Running the Model Testing in Edge Impusle, gives an accuracy of 98.36% (which is not bad considering the small dataset)
The compiled firmware uses 56% of program memory and 24% (64.3K) of dynamic memory.
If I run the recognition program using the CLI “edge-impulse-run-inpulse”, image recognition percentages come in at 0.99, 0.91 and 0.95 across the three categories/labels.
Based on my experiments, I have concluded that Peak RAM usage stat refers only to the amount of memory allocated for the arena required for inferencing and does not include all other variables the program may require. In the case of reading from a camera, you also need a chunk of memory to hold the image data (in this project’s case 160x120x2 - QQVGA RGB565 = 38.4 K)
My rough calculation for total memory usage is 64.3K (program variables) + 38.4K (image data) + 124.3K (arena) = 227K. Which is within the 256K memory available on the Nano33 BLE.
4 Likes